论文总字数:17523字
目 录
1 引言 1
1.1 研究目的,背景与研究意义 1
1.2 国内外研究现状 1
1.3 本文工作安排 2
2 语音识别系统 2
2.1 系统的基本框架 2
2.2 语音信号的录制 3
2.3 语音信号的处理 4
2.3.1 预处理 4
2.3.2 端点检测 5
2.3.3 特征提取 5
2.4 语音识别的算法 6
2.4.1 隐马尔科夫模型算法(HMM) 6
2.4.2 人工神经网络模型(ANN) 6
2.4.3 动态时间规整技术算法(DTW) 6
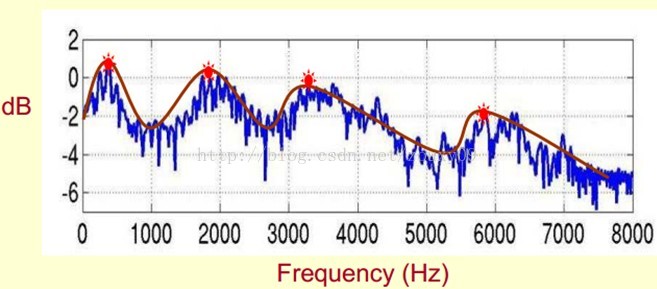
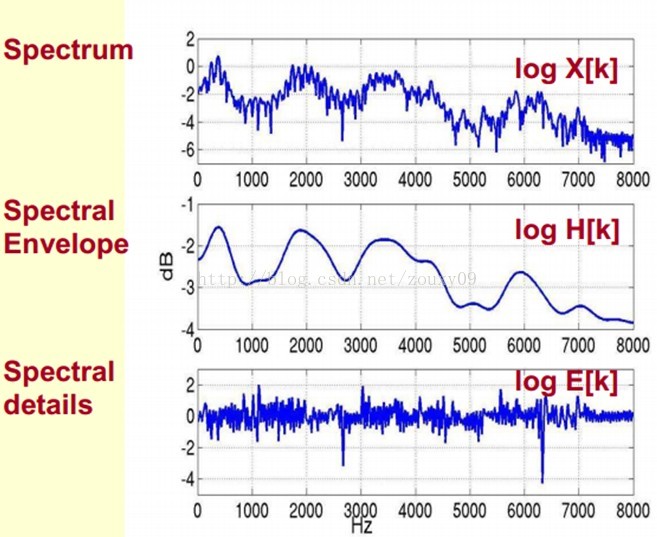
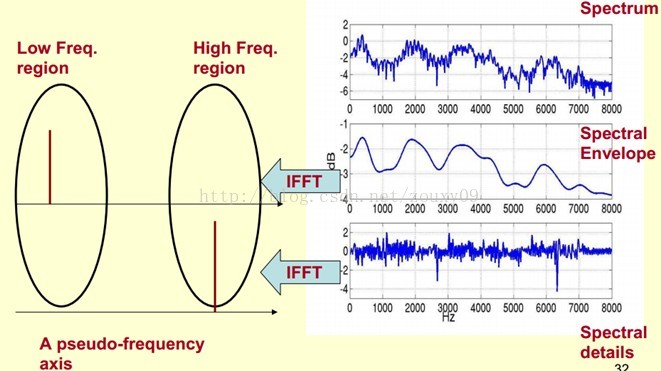
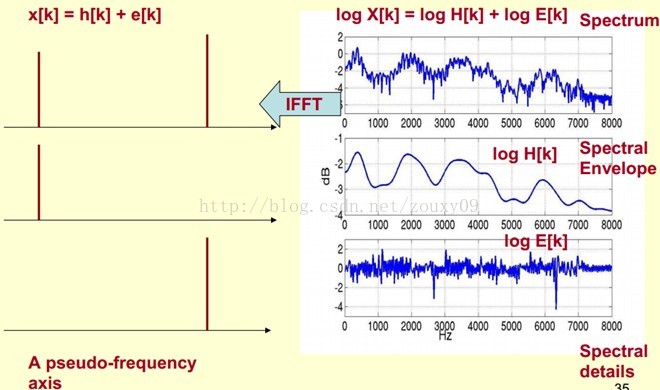
3 语音信号的特征参数MFCC 7
3.1 MFCC特征参数概述 7
3.1.1 倒谱介绍 7
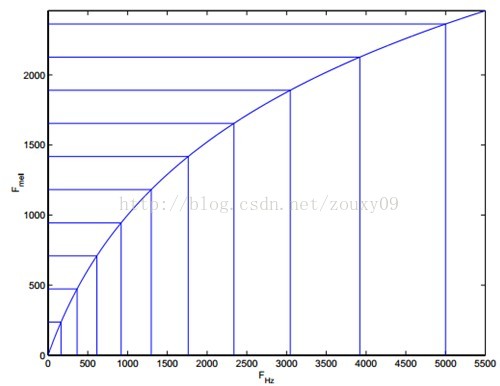
3.1.3 Mel倒谱分析 10
3.1.3 梅尔频率倒谱系数 11
3.2 语音特征参数MFCC的提取过程 11
4 DTW算法基本原理 12
4.1 动态时间规整技术算法(DTW) 12
4.1.1 DTW算法的基本原理 12
4.1.2 DTW算法的MATLAB实现 14
5 语音识别系统的GUI设计 15
5.1 运行环境 15
5.2 GUI界面设计 15
5.2.1 GUI介绍 15
5.2.2 语音识别系统的GUI实现 15
5.2.3 GUI界面测试 16
6 实验测试 20
6.1 阈值实验调试 20
6.2 识别率测试 22
6.2.1 测试方法 22
6.2.2 实验结果 22
7 总结 23
参考文献 23
致谢 24
基于DTW和MFCC的语音识别系统
张立
,China
Abstract:A speech recognition system based on dynamic time regularization (DTW) and MFCC is designed in this paper. This system uses DTW algorithm to complete the training of short speech by recording, preprocessing, segmenting and extracting MFCC characteristic parameters. And then this system can test the real-time input voice or pre-loaded voice, compare it with the trained template .If it corresponds with the training template,the recognition success, otherwise the recognition fail.The recognition rate is 90% after test, proves that the system has the voice recognition function.
Keywords:Speech Recognition;DTW;MFCC;Trained template
1 引言
1.1 研究目的,背景与研究意义
什么是语音识别技术呢?如果机器能够听懂人说的话,那么这个机器就有了语音识别技术。语音识别技术就是能将原始的语音信号转换为机器可直接执行的命令。随着社会的科技化发展,不管是大型设备,还是小型的终端设备,其需要接受和存储的信息都是大量增加,功能集成性也越来越高。因此传统的按键操作或者直接通过计算机输入代码指令显得效率不高,这些操作程序多,并且很复杂。在特殊环境,比如开车环境下,想要去操作汽车音响,那么驾驶者就需要低头去用手操作汽车中控台从而忽视道路情况,这将会带来危险。另外,比如在过交通繁忙的马路时,突然手机来了信息,这样手机使用者需要低头去看手机,容易忽视道路状况。因此,所有这些情况都迫切需要设备有更全面有效的人机交互性,使人机之间交流更加直接,更加简便有效。
而语音识别技术[1]应运而生,它可以让这些问题迎刃而解,迅速受到了各行各业的青睐。语音识别技术可以大大地加强人机交互性,使人能够更加轻松,便捷地使用机器,提高处理问题的效率。像美国苹果公司的Siri系统,安装在苹果手机终端上,能够轻松识别说话人的命令,使用者不需要看手机一眼就可以拨打电话,发送消息,非常方便快捷。
最近几年,机器的智能性得到了世界的关注,尤其是人机交互性这一重要特性,更是有许多研究围绕这个课题展开。语音识别技术就是机器将语音信号通过识别转换为对应的命令和文本。随着语音识别技术在电脑和手机上应用的普及,语音识别这门技术愈发火热,语音识别产品也成为了人机交互产品的大头。
1.2 国内外研究现状
国外研究现状:语音识别技术的萌芽起源于1950年左右,那时候Bell实验室发明了一个比较基础的语音识别系统,这个系统能够识别10个英文字母。而在20世纪60年代,语音识别技术获得了一个大突破,动态时间规划(DP )以及线性预测分析技术(LP )被人提出并且取得了大家的关注。到了1970年,这个时间段出现了矢量量化VQ和隐马尔可夫模型HMM的语音识别算法以及动态时间规整(DTW)这三种至今依然在使用,在借鉴的语音识别算法,对如今的语音识别研究都有深远的影响。而到了80年代,之前语音研究只能研究孤立词语音识别,80年代的此时国外又把眼光投向了连续语音识别,这种研究重心的改变极大程度上推广了隐马尔可夫模型HMM语音识别算法,使其获得了发展和进步。快接近2000年的时候,市场研究人员开始青睐对自然语音的研究和识别,并且开发了一种不同于之前传统语音识别的算法,人工神经网络算法。这种算法的优势是可以和比较成熟的HMM模型算法相结合,用于人机交互性能的提升。
国内研究现状:国内的语音识别研究相比于国外起步较晚,在80年代才刚刚开始研究。当时的研究小组只有一个由中国科学院声学研究所的马大猷院士领导的科研小组。他们当时的研究课题也是另辟蹊径,直接开始研究汉字语音的语音识别研究,这在国际上并没有先例可以借鉴,然而他们通过10年的努力,使汉字语音识别研究开始起步。从这之后,语音识别的研究小组就像雨后春笋一样爆发在中华大地,语音识别研究也得到了很多科学家和科研组织的认同与投入。到了80年代末90年代初,汉字语音识别出现一个里程碑,研究人员开发了基于汉语的语音识别技术,这个语音技术能够识别汉字的音节,这个里程碑的出现大大加强了推我国的语音识别技术水平,特别是连续语音识别技术获得了质的飞跃。接下来的里程碑是1986年,国家在语音方向设立了一个专门的863项目,这代表着这项识别技术得到了国家的重视与大力推广。项目一开展就得到了国内如哈尔滨工业大学,清华大学等大学以及许多研究机构的支持。他们在前人基础上开展了很多研究课题,一开始只能克服针对特定人的、小词汇量孤立词识别,后来研究重心投向了连续自然语音的识别。近年来,汉语语音识别发展速度更是历史最快,带动了语音识别产品的开发与生产销售,许多单位和公司例如中科模识、腾讯微信、上海华镇、盛大游戏等,看到了这片市场的巨大机遇,想要分这一碗羹,纷纷大力投入语音识别产业。
1.3 本文工作安排
本文第一节粗略介绍了本文的研究目的,研究背景和研究现状,第二节着重讲了语音识别系统的框架和流程,语音信号的处理流程,第三节细讲了语音信号提取中使用的特征参数,梅尔倒谱系数(Mel Frequency Cepstral Coefficents,MFCC),第四章详细介绍了本文使用的动态时间规整(Dynamic Time Warping,DTW)算法,以及这个算法的基本原理,第五节讲了语音识别系统在MATLAB上GUI界面设计以及实验测试,第六节说的是本文后续所进行的实验以及实验结果,第七节就是对整个语音识别系统的总结。
2 语音识别系统
2.1 系统的基本框架
语音识别技术有以下3种分类方法。第一种是分为特定人语音识别系统和非特定人语音识别系统。特定人语音识别系统仅适用于对专人的语音识别,应用范围不大,而非特定人特定人语音识别应用广泛,适用于大部分情况。第二种是分为孤立词语音识别系统和连续语音识别系统。孤立词语音识别系统要求每个词后停顿,没有复杂的连音和变音,算法程序较为简单,而连续语音识别系统由于对语音的处理复杂,所以程序非常复杂,且识别率不理想。本文使用的系统是非特定人孤立词语音识别系统。
本系统分为3个基本模块,分别是采集模块,处理模块和识别模块。其中,采集模块是对语音信号的录音以及播放;处理模块是对语音信号的预处理,分段滤波以及特征提取;而识别模块只要是先识别语音,然后进入模式匹配,如果是之前训练过的模板,则显示语音,如果不是之前训练过的模板,则显示识别失败,然后输出结果,整个程序流程结束。
程序流程图如下:
开始
模式匹配
结束
图2.1 程序流程图
2.2 语音信号的录制
语音信号的录制其实就是收集语音信号并将其转换为数字信号存储下来。整个流程都需要电脑自带的声卡来完成。本文用的声卡是16位采样的Realtek系列声卡,采样速率为8~44.1kHz。录制的步骤首先将麦克风插入计算机的语音输入插口上,启动电脑上录音软件,本文用的是win10系统自带的录音机软件。然后开始录音,测试人员需要对麦克风清晰流利地说话, 说完后关闭录音并且保存录音文件。在保存文件时,实际上就用到了集成在声卡上的A/D转换器,转换器可以把声音的模拟信号转换为离散的数字信号进行存储。这个过程中语音信号经历了两个步骤,第一个步骤是采样,第二个步骤是量化。只有经过这两个关键步骤的处理,原始的语音信号才能转换为在时间和幅度上都是离散的数字语音信号,方便后续的语音信号处理。A/D 变换器之后还对语音信号进行预滤波和采样处理,将数字语音信号转换为二址制数字码,这一系列操作保证了语音信号的数字化质量很高。概括地说,语音声波只要通过麦克风输入到声卡,很短时间内就能得到离散的数字语音信号,期间已经做过了防混叠滤波、A/D 变换、量化的处理。
本系统录制音频的做法分为有几个步骤:
1、先用win10自带的语音录音机,这个语音录音机的功能简洁,支持音频采集和拼接,同时以MP4的格式存储在电脑内。
2、利用强大的PC端音频格式转换软件(本系统用的是格式工厂),将之前以MP4格式存储的音频文件转化为wav格式,以方便MATLAB的识别与操作。
语音信号的录制流程如下:
图2.2 录音信号录制流程
2.3 语音信号的处理
本系统的语音信号的处理分为3个步骤:预处理,端点检测[2],特征提取。
2.3.1 预处理
本系统语音信号的预处理包括两个步骤,第一个步骤是预加重,第二个步骤是加窗分帧。
预加重,预加重一般只有一个目的,就是针对语音信号中的高频部分进行加重,这样处理过的语音信号在高频上分辨率更高。预加重在MATLAB中的实现为:
剩余内容已隐藏,请支付后下载全文,论文总字数:17523字
相关图片展示: