论文总字数:32959字
摘 要
随着人体动作识别在人群监控、人机交互、运动分析、人物相关内容检索等众多领域中的应用越来越广泛,成为了计算机领域中备受关注的前沿方向之一。本文提出用基于深度学习的机器视觉模型,在只使用由 Kinect 采集回来的人体骨架的运动数据的条件下,进行人体运动类型的识别。由 Kinect 采集回来的骨架模型数据具有数据容易获取,数据维度少的特点,可以方便地存储、传输与处理。因此,本文提出的识别模型在训练时除了 CAD-60 数据集提供的人体骨架数据,没有使用任何的先验知识来进行人体运动类型的识别。由此可以减少在数据的预处理阶段中人工的干预,只由机器自己来进行特征的提取,从而减少人工提取特征时的工作,使最终的模型的泛化性更优秀,鲁棒性更好,模型对人体运动类型有更好的理解与识别。在模型的研究上,本文测试了卷积神经网络、自编码器、降噪自编码器以及混合的多种结构,并实验了多种网络训练上的效果加强算法,比如一些正则化的方法和其他新的激活函数,最后选择了卷积神经网络作为自动特征提取的模型,并在其后面配合上多层感知机来进行分类,针对 CAD-60 里的数据,识别率为 81.8% ,取得比较优良的识别效果。
关键字:人体运动类型识别,CAD-60 数据集,深度学习,卷积神经网络,自编码器,Kinect
HUMAN ACTION RECOGNITION BASE ON COMPUTER VISION
Abstract
Human action recognition is an active research area in the computer science because it is widely used in the fields of the security monitoring, human machine interaction and the character related content searching. We propose a computer vision model in the paper base on the deep learning theory, which can recognize the human action only base on the data source in the skeletons of the human from Kinect. The reason to use the skeletons data from Kinect is it is easy to obtain, to store and to transfer, and it has the less dimensions of the data. This model only uses the human skeletons data from the CAD-60 dataset to recognize the human action without using any prior knowledge. It can reduce the works from the human on the stage of preprocessing and hand the feature extraction to the computer, which can reduce the error from the human-engineer. It can also improve generalization performance and robustness of the model, and give a better understanding of the human action. In the paper, we do the experiment on with convolutional neural networks, the autoencoder, the denoising autoencoder and some of their mixture, and it also do some experiments for the tricks which can improve the neural network, such as some regularization methods or other activation functions. In the end, we choose the convolutional neural networks for the feature extraction, with using the multilayer perceptron as the following classifier. And we get the accuracy rate of 81.8% which mean that the model is effective.
keywords: Human action recognition, CAD-60 dataset, deep models, convolutional neural networks, autoencoder, Kinect
目录
第一章 绪论 1
1.1 引言 1
1.2 人体运动类型识别的相关研究现状 1
1.2.1 人体运动数据源的获得 1
1.2.2 人体动作识别的主要问题 2
1.2.3 国内外研究现状 2
1.2.4 使用深度学习进行有效的特征提取 3
1.3 模型选择 4
1.4 数据源选择 4
第二章 人体识别模型原理 5
2.1 特征提取模式 5
2.1.1 人工特征提取 5
2.1.2 无监督训练特征提取 5
2.1.3 有监督特征提取 5
2.2 深度学习经典模型 6
2.2.1 主要成分分析 PCA 6
2.2.2 自编码器 Autoencoders 7
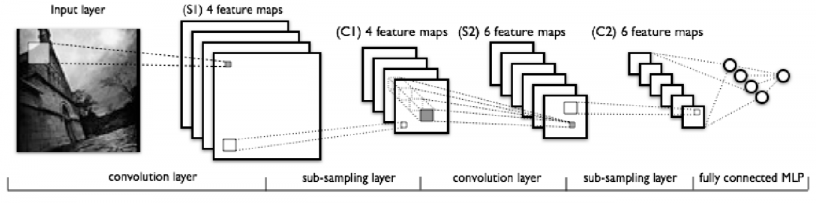
2.2.3 卷积神经网络 7
2.3 多层感知机(MLP) 9
2.3.2 前向传播 10
2.3.3 后向传播 11
第三章 人体运动识别模型设计 12
3.1 数据预处理 12
3.1.1 对输入数据进行标准化 12
3.1.2 参数的初始化 12
3.1.3 打乱样本的训练顺序 12
3.2 网络设计技巧 13
3.2.1 加入正则化环节防止过拟合 13
3.2.2 加入范数惩罚 13
3.2.3 Max-norm 14
3.2.4 Dropout 14
3.2.5 Maxout 14
3.3 实验模型 15
3.3.1 5层的多层感知机 16
3.3.2 自编码器+多层感知机 16
3.3.3 卷积神经网络+多层感知机 16
第四章 模型实验设计与验证 18
4.1 框架选择 18
4.2 数据集 20
4.3 实验准备 22
4.3.1 实验环境 22
4.3.2 实验编程平台 22
4.4 实验结果 23
4.4.1 5层的多层感知机 23
4.4.2 自编码器+多层感知机 23
4.4.3 卷积神经网络+多层感知机 24
4.4.4 加入正则化环节 24
4.5 实验结果分析 25
4.5.1 同行结果对比分析 25
4.5.2 本文实验结果分析 26
4.6 基于深度模型的动作识别软件开发 27
第五章 总结 28
5.1 总结 28
5.2 展望 28
5.2.1 加入提前停止法 28
5.2.2 更换其他分类器 28
参考文献 29
致谢 33
绪论
引言
在模式识别和机器学习(Pattern Recognition and Machine Learning, PRML)领域中,人体动作识别(Human Action Recognition, HAR)一直是比较重要的一个领域。 计算机自动去理解人类的行为、动作还有跟环境之间的交流互动,在近年来逐渐地成为了一个热门的领域,因为这个技术在很多领域都有可以使用的地方。比如现代社会快速的生活节奏和巨大的工作压力,严重影响着个人的身体健康。科学的运动可以提高身体素质增强运动能力,进而降低患病的风险(尤其是一些慢性疾病),例如糖尿病、血脂异常、高血压等。而进行科学运动的前提是实现人体运动类型的准确识别,对人的运动、健康状况进行理解、评估,这样才能对这些东西进行有用的指导和建议[1]。
在信息安全领域,可以通过监控视频识别到人物的动作,甚至是识别到身份,用这种方式利用计算机自动对视频中人体的运动类型进行识别从而为监控或者案件侦破提供依据,也具有着重要的意义和广泛的用途[2]。
在人机交互领域,可以通过手势、身体姿态等信息来进行输入,这样除了辅助交互输入设备和自然语言分析,其他的空白也能得到补充。这样就可以提高计算机和人进行交互的能力,使过程更有趣、更高效[2]。
在大型的图像数据库或者互联网上的信息中[3],还可以通过对人体运动类型的识别,从而标注并理解其中的信息,让搜索的方位更广、提供的信息更多。
由于人体动作识别的应用如此广泛,如何有效地提高人体动作识别的准确率是该领域急需解决的问题。而本本的任务是通过使用深度学习的相关理论,使用深度学习的相关技术来提高人体动作识别的识别率。
下文中分别对深度学习中的卷积神经网络、自编码器等模型进行试验,并应用类似 Dropout、 Max-norm 等算法对这些已有的模型进行改良,提高它们的效果,并用它们构造分类模型,应用于人体运动类型的识别,从而对人体运动类型有更好的理解,并提高对人体动作识别的准确率。
人体运动类型识别的相关研究现状
人体运动数据源的获得
首先,对于人体运动识别的数据的来源存在着几种不同的种类[4]。例如由 RGB 摄像机、距离传感器或其他遥感的方式。使用深度传感器来进行人体运动识别的发展始于 80 年代初。过去的研究主要集中在训练和认识到从视频序列(可见光相机)所采集的数据中。可见光视频的主要问题是从单目视频传感器捕捉得到的人体运动存在相当大的损失。由于视频天生的对的人体行为识别的限制,尽管已经有了过去几十年的努力,但通过视频来识别人体运动,仍然是非常具有挑战性的。
而得益于近期发布的成本低廉的深度传感器,和 3D 数据相关的研究越来越多了。在过去的 20 年里,获得 3D 数据的方法,一共分为三类。一种方法是通过使用基于标记的动作捕捉系统,如 MoCap。 第二种方式是通过立体视觉: 从多个角度捕获 2D 图像序列,通过从多个视图来重建三维信息。第三种方式是使用距离传感器(使用类似 TOF 原理的传感器)。深度相机在过去几年里取得迅速的发展。最近出现的深度照相机可以在相对低廉的成本和较小的尺寸的条件下提供较高的帧率和分辨率,这导致出现了许多新的研究中的动作识别都是采用的三维数据。
人体动作识别的主要问题
基于视觉的人体动作识别里有四个主要的问题。
第一个问题的挑战性比较小 [5-6]:闭塞、 杂乱的背景、 阴影和不同光照条件会让运动难以分割或者被错误地识别。这是从 RGB 视频行为识别的一大难点。引入 3D 数据可以在很大程度上通过提供现场的结构信息,从而缓解这个问题。
第二个是视角的变换[5,7-9]。相同的操作可以从不同的角度产生不同的"外观"。传统的 RGB 相机解决这一问题的方法主要是引入多个同步的摄像机,同时获得多个视角的图像,但对于某些应用程序,这不是件容易的事。不过对于三维运动捕捉系统,这不是一个严重的问题。而如果通过深度图像来进行识别的话,这个问题也会有部分被缓解,因为从轻微旋转的视角的外观可以推断深度的信息。这一点并不完全解决问题,因为摄像机始终还只是在对象的一侧上,这个距离图像只提供了部分的信息,还是没有人知道这个对象的另一面是什么样子的。如果可以运用单一深度相机来精确地推断出人的骨架模型,则可以通过骨架模型的信息来构造一种视图不变识别的算法。
第三个问题是放缩上的差异,因为人离相机的距离的不同会影响主体的大小从而影响运动的识别。而在 RGB 视频中,这可以通过在多个尺度下的[10] 特征提取解决了。而在深度视频中,这可以很容易调整,因为真正的主体的 3D 尺寸直接是已知的。
第四个问题是同一种类内的变异性和不同种类之间的相似性问题[11]。人可以通过不同的身体部位在不同的方向上做动作,但不同的方向和两个动作仅只有只由非常细微的细节来区分。而这个不管对于使用哪种数据的来源的算法来说都仍然是一个非常困难的问题。
前三个问题基本上都可以通过使用三维空间上的图像或者类似骨架之类的模型来解决,而且由于现在获得人体运动骨架已经变得非常简单了,所以本文使用的数据来源是由传感器采集计算直接得到的骨架数据。
国内外研究现状
从各种论文来看,相关研究的重点都是集中在寻找合适的特征,然后通过一些经典的或者是修改过的分类器进行分类。
如 Yu Zhu等人[12]提出来的使用通过在 RGB 图像或者深度图像中提取时空特征点STIP,然后把它与骨架模型等其他特征联合起来。把特征组合起来后放入 SVMs 分类器进行学习,最后得到一个可以使用的分类模型。
而 Lukas Rybok 等人[13] 则是提出了使用方向梯度直方图(Histogram of oriented gradients, HOG)[14]和光流场方向直方图(Histograms of Optical Flow,HOF)[15-16]来作为提取特征的模型,然后再配合 proto-object 来描述上下文的特征,最后也是通过 SVM 分类器的学习,得到一个有效的分类模型。
张永强[17]提出的在图像的基础上提取7个 Hu 不变矩作为特征,然后把它们输入到使用了AFSA优化过的 SVM 分类器中进行分类。
剩余内容已隐藏,请支付后下载全文,论文总字数:32959字
相关图片展示: