论文总字数:18662字
摘 要
社交网络在我们生活中日益重要,我们不仅通过社交网络平台记录生活、分享感悟,还可以与他人互动交流交流,实现了不见面也可以社交。关于社交网络用户的研究有很多,本文研究的是用户文本信息。
本文最开始介绍目前关于社交网络的研究,比如其网络结构、影响力,接下来本文选取微博用户的文本内容作为分析对象,因为随着微博从“新浪微博”改名为“微博”用户量巨大,文本数据比较多元,得到的结果比较有代表性。
本文首先介绍了中文分词、类聚等相关技术,并对不同的分词技术进行了优缺点比较。接下来介绍了本文针对微博文本信息的处理流程,包括文本表示流程,相似度计算,k-means聚类算法等。最终实现对微博文本信息的分析,得到结果并进行简单的预测。
通过本文,可以看出一个微博用户发布信息既多元又有很大的相似性。进而可以预测该用户在使用微博过程中的类型,是积极分享、重在围观,还是公共平台。最后我们统计微博用户发布内容的时间,进行简单的预测。希望可以提供给用户一些使用社交网络和现实生活的建议。
最后通过几组实验来验证这一过程。
关键词:微博;分词;聚类;k-means;TF-IDF
User behavior analysis in social network
09011402 Liang Xiaolei
Supervised by Professor Wu Guoxin
Abstract
Social network is becoming more and more important in our life, we not only through the social network platform record feeling, sharing life, you can also interact with others communication, implementation is not can meet social. Research on social network users have a lot of, this article studies the user text information.
This paper first introduces the relevant technology such as Chinese word segmentation, type, and the segmentation techniques are compared and the advantages and disadvantages. Next introduced in this paper, based on micro blog information processing, including text representation process, the similarity calculation, the k means clustering algorithm and so on. Finally realizes the analysis of micro blog post this information, results and carry on simple prediction.
In this article, you can see a weibo users publish information is diverse and there is a lot of similarities. Which can predict the user types in the process of using weibo, is actively sharing, emphasizing the onlookers, or a public platform. We finally released statistics weibo user content, a simple prediction. Hope you can provide users with some use of social network and real life.
Key words: Weibo; Participles; Clustering; K - means; TF - IDF
目 录
摘 要 I
Abstract II
第一章 绪论 1
1.1 引言 1
1.2 选题背景 1
1.3 社交网络研究现状 2
1.3.1 社交网络的结构支撑理论 2
1.3.2 在线社交网络影响力分析 3
1.3.3 微博文本信息的特点 3
1.4 本文的研究目的和主要研究内容 4
1.5 本文的组织结构 4
第二章 相关技术研究 6
2.1 分词 6
2.1.1 最大匹配法 6
2.1.2 最大概率法 7
2.1.3 最短路径法 8
2.1.4 几种方法的优缺点对比 8
2.3 文本聚类技术 8
2.3.1 文本聚类概况 8
2.3.2聚类方式 8
2.4 本章小结 9
第三章 微博信息分析处理流程 10
3.1 微博文本数据预处理 10
3.3.1 中文分词技术 10
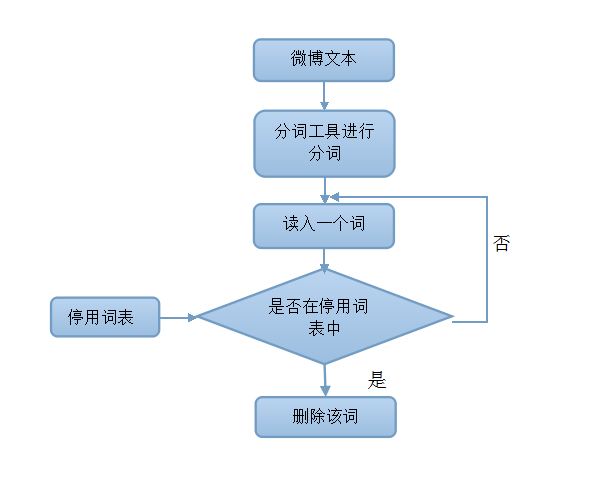
3.3.2 停用词过滤 11
3.2 微博文本表示 12
3.2.1 文本聚类概况特征项权重计算 12
3.2.2 建立向量空间模型 13
3.3 类聚处理 15
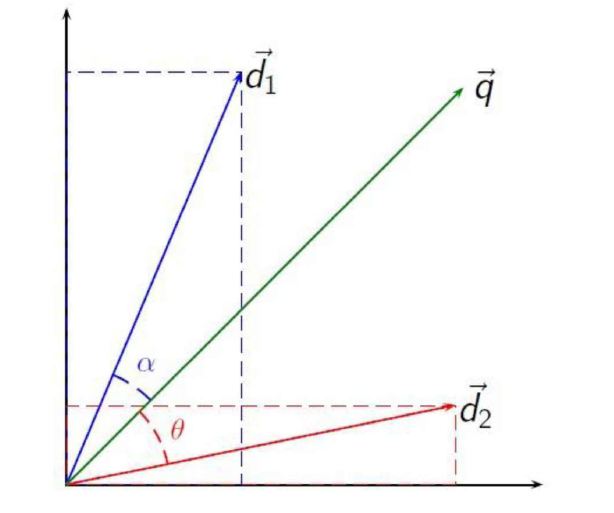
3.3.1 文本相似度 15
3.3.2 文本相似度计算 15
3.3.3 文本聚类概况k-means算法 15
3.4 本章小结 16
第四章 微博文本分析的实现 17
4.1 数据预处理的实现 17
4.1.1 文文分词 17
4.1.2 停用词过滤 17
4.2 文本表示实现 19
4.2.1 特征项选取 19
4.2.2 特征项权重 19
4.2.3 建立向量空间模型 19
4.2.4 TF-IDF权重计算 20
4.3 k-means算法的实现 20
4.4 本章小结 23
第五章 实验及结果分析 24
5.1 实验环境 24
5.2 实验过程 24
5.2.1 实验数据 24
5.2.2 权重计算 25
5.2.3 k-means聚类结果 25
5.3 实验结果 26
5.3.1 用户类型预测 26
5.3.2 用户发布微博时间分析 28
5.5 本章小结 29
第五章 总结及展望 30
致谢 31
参考文献 32
第一章 绪论
1.1 引言
随着互联网的进步,社交网络在人们生活、工作中产生了巨大的影响。从微博、人人网、facebook、QQ,到微信的风靡,越来越多的网站、app都在社交网络化,让漫无边际的互联网似乎形成了以一个个社交圈子连接起来的大网。
一方面,人们借助社交网络平台分享个人生活、联络朋友、发表观点、讨论公共话题等,使社交网络成为了现实社会的延伸;另一方面,随着社交网络的不断完善以及对人们生活渗透作用的增大,当量变引起质变的时候,社交网络也可以看成是对现实社会关系网络的重建。这种重建的社交模式既平行于现实社会,又与现实社会紧密相连。由于在社交网络中个体的行为和状态更容易被记录、获取和分析,因此对社交网络上用户行为的分析研究成为了社会计算领域的重要研究内容。
关于社交网络,目前主要有两方面的研究,一是社交网络结构的分析,二是社交网络用户行为的分析。本文将对社交网络用户行为的一个方面进一步进行分析,即社交网络用户的文本信息。
1.2 选题背景
分析社交网络用户行为,不仅可以帮助企业根据用户行为特征提供更好的服务和产品、进行更有效的网络营销和推广,而且也为有关部门对网络舆论进行合理的监控和干预。例如淘宝网根据用户的浏览记录推荐商品,使用户有更好的体验,同时也为企业带来收益。而网络舆情同样重要,近年来,通过不断爆发的舆情事件可以看出,社交网络一方面可以快速传播的网络信息内容,使社交网络的小世界现象和级联式传播方式具有更强的催化放大作用,极大地加速着信息的传播和演化;另一方面,社交网络用户通过在阅读、交友和游戏过程中传播信息,也在不断地淘汰低质信息源,生成新的社会关系和信息通道,这种对信息源的再选择行为也导致了网络结构的变化。
而微博作为既可以称之为社交网络,也可以称之为社交媒体。用户通过微博不仅可以分享自己的内容,也可以获得大量信息,如近期热点话题等。微博也拉进了人与人之间的距离,在我们看来遥不可及的两个人通过“关注”取得了联系。如我们通过微博关注名人明星,不仅可以关注他的近期动态,还可以通过评论、转发与其获得沟通的机会。而这一过程中,用户在社交网络上的言论具有极大的自由和开放性,也具有一定的匿名性,所以针对用户在社交网络上的内容研究具有十分重要的作用。总之,社交网络用户的行为对个人工作生活、国家经济发展、社会稳定和国家安全都有着至关重要的影响。
由此,我们选定在社交网络领域影响力较大的微博用户的文本信息作为分析对象。
1.3 社交网络研究现状
1.3.1 社交网络的结构支撑理论
社交网络就像一张大网,一个用户的观点或内容可以引起很多关注、转发甚至成为热点话题,那么,当一个新兴热点出现时,我们如何判断它的兴起究竟是用户们自身对其感兴趣,还是社交网络的网络结构使其效果放大化?一个话题迅速引起用户们关注,是否存在水军的幕后推动?我们又该如何识别这些网络推手?在社交网络中,用户在信息交换中体现出一种相互依存的特点。
该理论简单来讲,是在一个社交网络中,如果将节点v断开,会导致另外一个节点u的社会影响力发生变化,则我们认为u在某种程度上依赖于v;将u的社会地位变化的程度量化表示,就是u对v的依赖度;反过来看,对于两个节点u和v,u对v的依赖可以理解为v对u的支持,而一个节点对于网络上其他节点的支持程度总和,就是这个节点对网络的支持力[[1]]。
我们简单介绍一下个体支持力,个体支持力是指,社交网络中的节点对他人提供支持的力度的一种衡量。近年来,通过分析网络结构,对用户进行指标衡量这一类型的研究获得了广泛的关注。
1.3.2 在线社交网络影响力分析
已有的研究通过社交网络中的影响力度量分析用户社交影响力的大小及预测用户的行为变化规律,影响力度量也为其研究和应用提供技术支持和理论依据,常用的影响力度量方法有:基于网络拓扑结构、基于用户行为和基于交互信息的度量等类型,社交网络拓扑是用户在社交活动中残留下的“遗迹”,从网络拓扑学角度体现了用户影响力的特征,而且社交网络结构的获取比较简单,基于其上的度量方法相对成熟,计算量较小,但是,网络拓扑无法刻画用户之间频繁的交互活动,而用户在社交活动中的行为变化能够更准确地反映用户社交影响力的产生和演变情况,用户的交互信息则能够进一步体现影响力产生及演化的细节,所以,在进行社交影响力分析时,既需要根据实际情况选择合适的度量手段,还可以综合使用上述方法,尽可能准确客观地刻画社交影响力的真实面貌[[2]]。
社交影响力及其传播过程会受到很多因素的限制,而且这些因素之间是紧密联系,相互依存的。比如在社交网络上的交友现象,两个人最终成为朋友的因素有很多种,有可能是因为某些信息交流产生相互影响的结果,也有可能他们本身就具有很多相似点,比如有相同爱好、相似的习惯或者信仰等同质性特征,也有可能是其他的外界因素使得两人成为朋友,还有可能是以上因素共同作用产生的结果。目前的影响力模型大都以上述要素的个别部分作为主要因素进行构建,为模型设计和计算带来便利的同时,模型的通用性也不强,而全面考虑上述要素又会使得模型过于复杂或者根本无法实现。所以,在设计和完善现有影响力模型的过程中,既要全面考虑各种要素的作用和权重,使模型尽可能符合现实世界的真实情况,同时还有赖于对非独立要素相关性的分析和研究,找出它们之间的内在联系和变化规律,以减少模型中的参数数量,降低模型复杂度。
1.3.3 微博文本信息的特点
我们选择新浪微博用户在社交网络上的行为数据作为研究对象,因为微博如今不仅仅是人们分享心情、沟通交流的平台,更是很多社会热点、关键话题的发起源头。微博作为一个开发的社交网络平台,得到了越来越多用户的青睐。
微博文本,指的是微博用户通过微博进行发布的内容信息,可以是文字,也可以是表情,图片等等。本文研究的是中文内容,微博中文文本的特点是:
- 字数少。微博规定每条微博发布内容最多140个字,所以用户一般发布的字数都不会大于140,有时甚至只是一句话或是几个词。
- 随意性。微博的功能之一就是记录生活、分享感悟,所以用户在发布内容的时候一般比较随意,不会吹毛求疵,这样的结果就是,微博文本中有大量错别字或是超链接噪音等等。
- 数量多。注册微博十分简单,所以微博用户有很多,且发布一条微博也很容易,这样的结果是微博的数量极大,数据极多。
1.4 本文的研究目的和主要研究内容
综上所述,研究者们对社交网络已经进行了大量的研究,本文在这些研究的基础上,具体的对已有的微博文本信息进行分析,并通过实验来验证。
由于注册微博十分简单,所以微博具有大量用户,这些用户发布的文本数据是巨大的。想要了解一个用户更关注哪些内容、更喜欢发布哪些内容,通过直接观察是很难的,且效率很低。所以本文的研究目的,是想通过对微博文本信息的处理及聚类,了解这些文本的大致类别,更直接简单的理解用户,并对结果进行分析,预测用户的类型,希望给用户一些使用社交网络的建议。
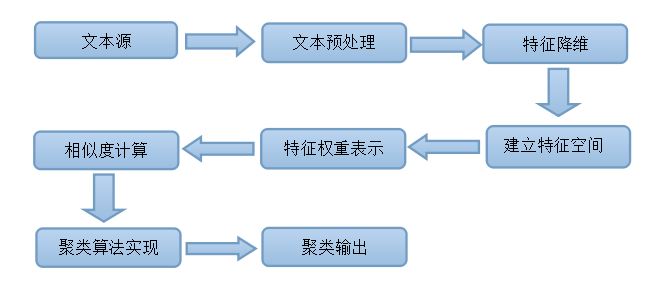
本文的研究内容,首先是微博用户发布的文本信息该如何从只可以是人类可以理解的自然语言转换为计算机可以进行操作的信息,第二,这些文本信息中哪些词是对该条内容有意义的,哪些是可有可无意义不大的,如何进行筛选;第三,筛选后的文本数据如何进行分析。针对这些目的,本文将通过分词、停用词过滤、文本表示、聚类过程等实现对微博文本的分析。
1.5 本文的组织结构
第二章,介绍几种本文涉及的相关技术。包括多种分词方法及优缺点比较,文本聚类技术。
剩余内容已隐藏,请支付后下载全文,论文总字数:18662字
相关图片展示: