论文总字数:17543字
目 录
1.绪论 1
1.1背景 1
1.2 聚焦搜索引擎设计的主要功能 1
1.3 关键技术 1
1.3.1 开发环境及框架 1
1.3.2 Lucene 2
1.3.3 Ajax 5
1.3.4 Jsoup 5
1.3.5 Selenium 5
1.4 论文结构 6
2.需求分析 6
2.1 功能需求 6
2.2 性能需求 6
2.3 可用性及可靠性需求 7
3.总体设计 7
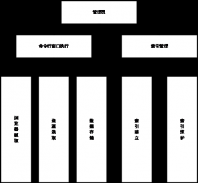
3.1 系统各功能模块划分 7
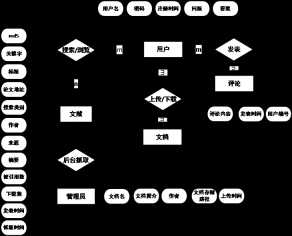
3.2 数据库E-R图 9
3.3 数据库的逻辑设计 10
4.详细设计 11
4.1 数据采集 11
4.2 数据存储 12
4.3 索引更新 12
4.4 分词 13
4.5 网盘搜索 13
5.系统实现 13
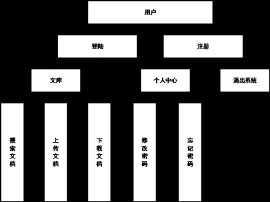
5.1 前台用户模块 13
5.1.1 用户注册和登录 13
5.1.2 系统首页 14
5.1.3 用户搜索 14
5.1.4 单条搜索出来的文献详情 15
5.1.5 网盘搜索首页 15
5.1.6 个人中心 17
5.2 管理员后台模块 18
5.2.1 信息采集模块 18
5.3 实现过程中出现的主要问题及解决方法 19
总结 20
参考文献 21
致谢 22
聚焦搜索引擎的设计与应用
林会杰
,China
Abstract:The purpose of this paper is to solve the problem that the current web crawler can not directly climb ajax and jQuery pages. The main method is to use the selenium to operate the chromedriver, simulating the user to select the input query field in the browser, jumping to the appropriate interface using jsoup grab page data. On the basis of a series of basic research on the core components of the search engine, namely, the data, the weight, the index and the search, and the realization of the process, the realization of this graduation project is completed.This system mainly realizes that search for custom keywords according to different search topics such as home,for example, search unit of Nanjing University of Information Science and Technology, and store it in the datasheet, after building the Lucene index to the datasheet, you can quickly achieve the fast search inside the station.
Key words:Automated crawling; Search Engines; SkyDrive search
1.绪论
1.1背景
由于项目需要,公司需要使用网络上关于某一方面的数据作为自己的数据支撑,如果直接向此数据库提供商租借,必须支付数据提供商高昂的费用,提高了项目的预算,此时,需要手动从网络上抓取相关的精准数据。现阶段,使用当前主流的搜索引擎搜索关键字时,往往会出现很多噪点,降低了搜索的精准度,有时远远不能满足用户的需要。
1.2 聚焦搜索引擎设计的主要功能
聚焦搜索引擎设计的具体实现功能方面,主要可以根据用户输入关键字可以搜索网站关于此方面的所有内容,使用数据采集方法将数据采集后存进数据库,索引建立后,用户可以在系统内快速搜索到相关信息。
此外,系统还包含了网盘搜索系统,可以让用户输入关键字后搜索到所有存在于百度网盘里的相关文件。
本次系统研究了Ajax建设的网站的特点,在传统爬虫对其无计可施时,需要一种新的方法能够自动触发网页的动作,实现网页跳转到所需要的目标界面,再对其采用一般的数据采集方法即可。
浏览器抓取突破了传统爬虫的局限性,可以让数据采集拓展到所有网站,尤其时如今火爆的电商网站,网站对其本身的数据都采取保护措施,纷纷采取Ajax页面避免爬虫爬取网站获取。使用本次系统的方法,只要是浏览器能够浏览的界面,里面的数据都可以被抓取采集到本地为系统所用,具有一定的现实使用意义。
科学技术的飞速发展加速了信息的增长,同时也加重了信息用户搜集信息的负担,成功的检索必将会减少用户的搜索时间,使其可以拥有更多的时间致力于所研究内容。某些情况下,用户只需要网络中一部分的信息,其他繁杂的数据必定给用户造成了一定的困恼。本次系统为爬取采集到的知网上关于计算机与软件学院老师的文献建立了数据库,可以供本院学生查询老师的相关著作或者老师们对某一关键技术的研究。
1.3 关键技术
1.3.1 开发环境及框架
Eclipse比起Myeclipse来说其免费且体积非常轻便,对于硬件和内存的消耗比较小,可以根据需要安装插件,而不是像Myeclipse一样默认增加了平时用不到的插件,运行时增加系统负担,所以本次系统选择了免费高效的eclipse作为开发工具。
与Java配套使用的Web服务器自然而然便想到了Tomcat服务器,其优点不必多说。
由于Mysql数据库占用系统资源少,且运行速度快,所以系统开发中便使用了Mysql数据库,并且Mysql数据库的管理和维护极为方便,利于小中型系统的开发;本次系统中利用Navicat来操作数据库。
本次系统所用的框架是Spring MVC框架,Spring MVC,顾名思义,采用了MVC架构的思想,是一种轻量级的web框架。框架的目的就是帮助开发人员简化开发,Spring MVC也是一样,降低了项目的耦合度,利于分层管理,简化了日常开发,提高了开发效率。
大三下学期学了J2EE中的Struts,由于Spring MVC和Struts都属于MVC框架,所以特将二者作一比较。在易用性、安全性和可扩展性方面进行对比,Spring MVC都表现出了一定的优势,可以说Spring MVC的使用未来也会越来越多。在本次系统开发过程中体会最深的就是Spring MVC注解为开发带来的便捷,而Sturts的配置文件设置跳转远比前者在开发过程中效率低的多。
1.3.2 Lucene
Lucene作为一个搜索引擎的工具包,它可以快捷方便的帮助开发人员为其开发应用配置搜索及全文检索功能;早前,作者就是为了这一目的,开发了Lucene,帮助开发人员更加快捷高效的开发。
由于Lucene纯粹基于Java语言,且免费、开源,并且所有需要全文搜索功能的应用程序几乎都能够对其完美适配。
当前,全文检索在搜索引擎搜索中发挥了重大作用。在众多的全文检索的工具中,Lucene是现阶段比较受欢迎的全文检索工具,所以本系统也使用了此工具来实现检索功能。在我们经常使用的工具基本都会看到Lucene的影子,比如本次设计使用的开发工具Eclipse就使用到了Lucene(帮助部分,如图1.1所示),可以看到,被检索到的字都已经被高亮,适合用户查看每一个被检索到的信息。
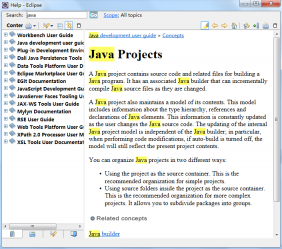
图1.1 Eclipse中使用Lucene原理处
Lucene一般使用到的包结构和功能大致如图1.2所示

图1.2 Lucene包结构功能表
Lucene检索属于索引检索(类似于课本目录),即用空间来换取时间,预先在系统资源里建立相应的索引文件,虽然占据了系统部分空间,但大大的节省了搜索的时间,搜索结果将返回数据中这个关键词出现的位置
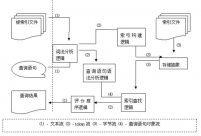
图1.3 Lucene数据流图
将Lucene全文索引与数据库作对比,比较两者的性能,如表1.1所示
表1.1 Lucene全文索引与数据查询比较表
Lucene全文索引引擎 | 数据库 | |
索引 | 将数据库中的所有数据装进索引一一建立具有特色行的倒排索引 | 对于一般的数据库查询来说,使用不到索引的 |
匹配效果 | 数据装进索引时,Lucene早已用自带的切词工具将数据切成许多个词,方便快捷的提高了匹配的准确性 | 数据库查询单个或连续的数据时,不太容易出错;但一旦进行模糊查询时,效果便不尽如人意 |
匹配度 | 自带匹配算法,将匹配度高的排在前面,也可以自定义按照哪种方式排列 | 没有涉及到匹配程度,对于数据库中重复存在的数据显示效果一般 |
结果输出 | 可以按照用户自定义的方法,也可以根据自带的算法排序,输出匹配度比较高的项 | 返回所有的ResultSet,输出时需要消耗大量的内存 |
续表1.1 | ||
Lucene全文索引引擎 | 数据库 | |
可定制性 | 通过不同的语言分析接口实现,用户能够非常方便的定制自己想要的规则算法:输出匹配算法,输出排序规则,本文中还使用到了根据自己所要的专有名词来扩展分词词典里的词典,大大的提高了分词的准确性,可以说Lucene可定制性很强 | 数据库严密的封装性不提供接口,也就意味着其不具备可定制性 |
结论 | 在数据量比较大时,更适合使用Lucene来查询数据 | 在查询规则比较单一或者数据量比较少时,使用数据库查询相对比较简单 |
1.3.3 Ajax
Ajax异步刷新的特点深受用户和网站开发者的宠爱,用户喜欢是因为其相对整个页面来说只操作部分页面,不干扰用户其他操作,用户体验度高;而网站开发者则是因为Ajax可以节省带宽,降低系统资源的消耗,减少网站的维护成本。
在用户体验方面,Ajax的技术简直是一种艺术,既实现了用户请求触发的功能,又没有影响到页面里用户的使用记录或数据,大大的提升了用户体验。一般传统的网页(没有使用到Ajax)如果请求更新数据,必定会使得整个页面重新加载一遍,对于只需要输入一点点的数据操作时,用户尚可接受;但关于一些其他使用时,用户必然怨声载道,比如观看某段网页视频时,突然跳出来一些验证请求消息,刷新了整个页面必然导致视频重新加载且没有恢复到原播放进度部分,严重影响了用户的使用,这也正是异步刷新的魅力所在。
1.3.4 Jsoup
对于解析Html元素来说,Jsoup可以说是得心应手,本系统中,Jsoup提供的选择器功能可以方便快捷的进行Dom方式的元素解析,用Document类来接收解析到的数据供开发人员使用;而元素检索方面,Jsoup可以使用简短的select选择语句就可以实现强大的元素检索。Jsoup的亮点之处还在于他可以在一定范围内组合选择器用法,以及还支持正则表达式等之类的表达式,使得选择器功能更加强大。
1.3.5 Selenium
Selenium是企业用于网页应用程序测试的工具。Selenium测试可以直接运行在浏览器中,就像真正的用户在操作一样,支持自动录制动作和自动生成。本次系统中,也是使用了这个原理,使原本只有Ajax的页面外不存在其他超链接的网页自动跳转到所需的具体页面,方便数据的采集,帮助数据采集工作人员减轻了需要制定复杂网络爬虫的负担。
1.4 论文结构
论文的中第一章,主要讲述了搜索引擎发展的背景,本次聚焦搜索引擎设计系统的主要功能,以及系统中用到的关键技术;紧接着在第二章里重点分析了系统的功能需求、性能需求以及可用性和可靠性要求。论文中的核心功能在第三章中做了详细的描述,阐释了系统功能的模块划分,以及数据库的逻辑设计;在此基础上,利用第四章重点论述了详细设计实现的功能以及解决的主要问题,还总结了系统设计与实现中相关问题的解决办法和收获。最后,在第五章中完成系统的实现及展示了系统运行时的相关截图。
2. 功能需求
2.1 功能需求
由于网络数据的繁杂,当用户使用一般搜索引擎搜索数据时,由于网站开发建设需要成本,网站会将某些盈利性的信息放在首页且页面甚至会加载广告,不仅降低了搜索的精准性,同时网页资源的过多加载必然会消耗系统资源以及严重降低了用户的体验度,如用户在百度搜索某一字段时,搜索结果会首页显示相关的百度推广,接下来的搜索结果里还可能包括百度知道,贴吧等用户不关心的内容;另一方面,由于某些网站对数据的保护,搜索引擎有时并不能搜索到关于此关键字的所有数据,此时需要做到的是针对用户所需,去相关权威网站抓取相应的数据存进数据库,便于用户可以站内精准搜索到所需内容。
剩余内容已隐藏,请支付后下载全文,论文总字数:17543字
相关图片展示: