论文总字数:22562字
摘 要
近年来,数字化进程加速的多媒体资源使得网络音乐数据的数量激增,基于web2.0的音乐数据库也变得越来越庞大,伴随而来的是音乐检索的越发困难。这样的窘境已经使研究人员将研究重点放在如何快速精准地从海量数据库中查找出音乐。鉴于近年来,用户对于音乐检索的需求从传统的基于内容(文本标注,如歌曲名称,专辑,演唱者等等)的音乐检索,发展到希望用截取的音乐片段进行检索,本文研究了基于样例的音乐检索技术。
本文采用了matlab编程技术,做了如下工作:
通过对音乐信号基本理论的研究,提出了利用相邻音符过零率描述音乐旋律特征的方法,并基于短时能量对音乐的音符进行了划分。
对于音乐片段进行分帧和加窗的处理,以便从WAV文件中提取音符过零率和短时能量特征。
采用n_gram算法对音乐旋律的特征字符串进行划分,以便扩充查询集合,使查询速度加快、查询结果更加精准。
进行数据库设计,将歌曲和特征保存在MICROSOFT ACCESS数据库中,通过ODBC数据源连接MATLAB。
将样例的N-Gram片段和特征库中的WAV N-GRAM特征片段进行匹配,返回查询结果,并计算响应时间。
关键词:音乐样例检索;特征提取;特征匹配;短时过零率;短时能量;N-GRAM;音符切分
SAMPLE BASED MUSIC INFORMATION RETRIEVAL
Abstract
The article is mainly about the sample based music information retrieval system.
The system returns retrieval a result and response time to user after they put a music sample in.
The system is divided into three layers: the database layer, the feature extracting layer and the feature matching layer. The database layer stores the feature data, which use mat format. The feature extracting layer extracts features such as the short time zero-crossing rate and the short-time energy, then identifies each note and calculates the short_time zero-crossing rate for each note, besides, use strings to describe the music sample’s feature, which called N-Gram algorithm. The feature matching layer match the sample’s feature with all the feature data in database.
KEYWORDS: sample based music information retrieval system, feature extracting, feature matching, the short time zero-crossing rate , the short-time energy.
目录
基于样例的音乐检索 II
摘 要 II
第1章 绪论 6
1.1 基于样例的音乐检索的背景和意义 6
1.2 检索算法早期研究及近况分析 7
1.3 研究内容与论文结构 8
第2章 基于样例的音乐检索综述 10
2.1 音乐检索的基本概念 10
2.2 音乐旋律的特征提取 11
2.2.1 音乐信号的预处理 11
2.2.2 第一层级音乐特征提取 12
2.2.3 音乐旋律的特征表示 13
2.3 音乐的特征匹配 13
第3章 系统概述及具体实现 15
3.1 系统开发工具概述 15
3.1.1 matlab开发语言..........................................................................15
3.1.2 Microsoft Access数据库 15
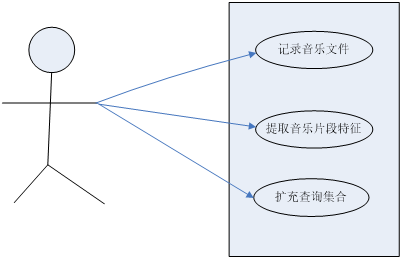
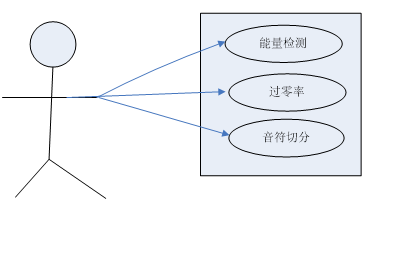
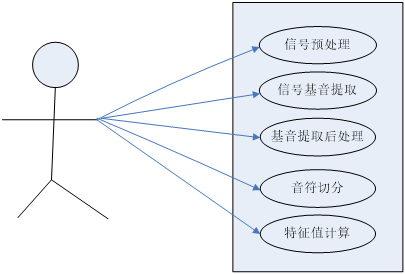
3.2 系统用例图 16
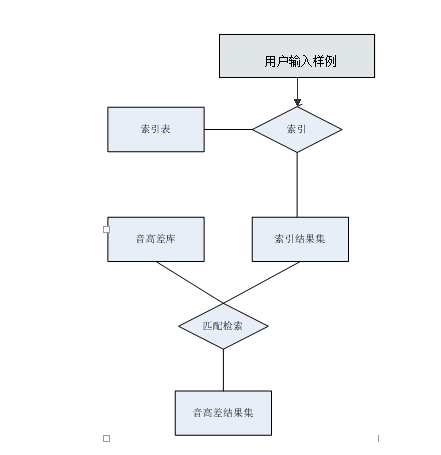
3.3 数据库逻辑设计 18
3.3.1 概念模型设计 18
3.3.2 数据库观念模型设计 19
3.4 系统总设计 20
3.5 数据库详细设计 21
3.5.1 用户输入样例音乐信息表 21
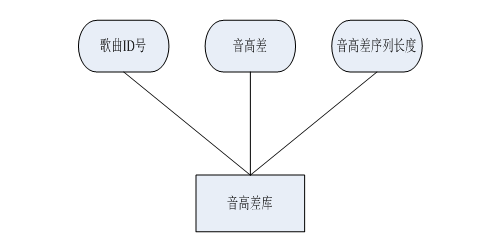
3.5.2 WAV特征库设计 22
3.5.3 索引表 22
3.5.4 索引结果表 23
3.6 功能详细设计 23
3.6.1 WAV特征提取 24
3.6.2 样例片段特征提取 28
3.6.3 N-Gram算法扩展查询 28
3.6.4 哈希索引 28
3.6.5 N-Gram快速匹配算法 29
3.6.6 系统响应时间计算 30
第4章 实验结果与分析 31
4.1 系统功能测试 31
4.1.1 WAV音乐文件特征提取测试模块 31
4.1.2 N-Gram算法测试模块 32
4.1.3 哈希索引表测设模块 32
4.1.4 检索匹配测试 33
4.2 原因分析 34
第5章 总结 35
参考文献 36
致 谢 39
绪论
基于样例的音乐检索的背景和意义
音乐是如此宝贵的精神食粮,当历史发展到21世纪的今天,互联网和丰富的多媒体资源走进我们生活的今天,音乐已经成为我们生活中必不可少的元素。随着多媒体资源的数字化,CD,磁带等等音乐载体已经被数字化的音频所取代。网络上有着海量的数字化音乐,如何在浩如烟海的音乐数据库中检索到我们想要的音乐,成为了一个非常有意义的课题。
目前主流的音乐检索系统,如百度,Google等都是基于内容的音乐检索,主要是根据歌曲名称进行检索,或者根据人工标注进行检索,如演唱者,专辑等等。这种检索方式虽然传统,简便,但是同时存在许多问题:首先,对歌曲进行标注就是一件因人而异的主观性很强的工作,对标注者的专业素养有一定要求,并且不同的人对同样的歌曲有着不同的描述;其次,某些音乐的特征,如歌曲的旋律,音调,音质等是无法用文字进行描述的;另外,现实生活中的一些实际情况也让用户对于音乐检索提出了一些别的要求:大家可能经历过这样的事情,在某个场所听到一段音乐旋律,在不知道乐曲名称的情况下想要在网上查找到这段音乐,此时就需要基于样例的检索技术;另外,互联网的音乐版权问题一直都是用文字信息进行监测,但是这样并不能够精确地检测出盗版问题,在此也需要基于样例的音乐检索技术。正是出于以上种种的迫切需求,基于样例的音乐检索技术成为解决这些问题的好方案并成为这些年研究的热点。有了这种检索技术,音乐的检索可以不仅仅局限于文字的标注,用户对于音乐的直接感官体验,如音色,音调,旋律等等都可以作为检索的依据。
并且,基于样例的音乐检索技术应用前景广泛:主要表现在以下几个方面:
- 信息检索方式多样化
不停留于传统的通过文本标注进行搜索的方式,提供用户通过音乐样例进行搜索的功能,满足了多样性的用户需求,提升了用户体验。
- 内容完整性校验
内容完整性校验主要是检测原始音乐有没有受到恶意修改。将现有音乐的特征与原始音乐储存在特征库中的特征进行匹配,就可以检测出音乐内容的完整性。
- 音乐共享平台专业化
网络多媒体资源的爆炸性增长带来了网络资源的泛滥和冗余,因此经常出现多媒体资源名称和内容不匹配的现象。而通过音乐样例检索技术,可以实现对音乐内容的校验,过滤重复歌曲,并解决音乐名称和内容不匹配的问题。
- 版权保护
通过音乐样例的检索技术,可以对音乐电台、电视中所播放的音乐进行监控,以达到音乐版权保护的目的。
- 其他应用
基于样例的音乐检索技术具有非常大的商业价值。有个项目叫做‘Music Genome Project’,该项目是由美国政府的研究部门设立的,而基于这个项目开发的Pandora网站,提供非常便捷的音乐检索服务,该服务项目为该网站赢利颇丰。再举一个例子:有另外一个用户众多(在全球200多个国家拥有超过两千万的用户)的音乐发现网站,名叫‘Last.fm’,也提供了非常优质的音乐检索服务,也取得巨大效益。另外,‘Google Music’登录中国市场之后,致力于在中国成立一个亚洲最大的音乐数据库,这个数据库预期将于2012年中期投入使用,该音乐库提供超过200万首正版音乐的付费下载。
检索算法早期研究及近况分析
最早基于音乐旋律对音乐的特征进行表示的方法提出者,是Chias等 [10]。他在95年的一篇论文中首次提出其基于音乐旋律的音乐检索技术的系统构架,并且详细地阐述了音高提取技术,即把相邻音符的音高变化表示为‘U’,‘D’,‘S’,即升高、降低、和相同。这种表示方法放弃了传统的全局频谱信息和语谱图特征点的方式,有别于音乐样例检索领域最最常用的philips和Shazam方法。他通过这样的特征表示方法,将音乐特征表示为一组字符串,接着采用经典的快速近似匹配算法,比较模式传和待匹配串的近似程度。当时Chias的音乐库中包含了接近两百首歌曲,据他的研究报告,这样的特征提取即匹配算法,能够带来100%的命中率。
在Chias的基础上,后人对这一检索方式又展开了大量的研究。其中值得一提的是R.J.McNab的研究 [11],他沿袭了字符串的音乐特征表示方式,并且采用了动态规划的方式来进行特征匹配,他的音乐数据库规模达到了将近一万首歌曲,遗憾是他在研究报告中并没有明确指出实验结果,如命中率及系统响应时间等等。
另外值得一提的还有Lie Lu 等人的研究[12]。他们认为单单凭借一个音高差特征就对音乐进行表示的方案不够精确,于是开创性地提出了三元特征的特征表示模型,三元即音高曲线,音高距离,持续时间。三元模型中的音高距离即为音高差,依旧用USD序列进行表示,而持续时间是指一个音符持续的时间,音高曲线刻画了音乐信号在时域上所具有的规律。而在匹配算法的选取中,他们使用了一种分层匹配的思想,即模糊匹配配合精确匹配进行。首先,他们使用DP算法对于音乐的音高差曲线特征进行一次模糊匹配,并且设定一定的阈值,当匹配结果小于这个设定的阈值的时候,再对剩余的两个特征进行精确匹配。当时的数据库中只有一百首歌曲,而命中率却并不高,只有74%,不过这种分层式匹配的思想给接下来的研究带来了新的方向。
关于音高曲线的匹配方法,Ó Maidín 等人[13]在传统的DP匹配方案之外还提出了一种基于二维的几何匹配法 。这样的方法在提取音乐音高曲线后,直接在二维空间内应用几何的方式计算两条音高曲线的相似度:用夹在两条音高曲线之间的面积表示两端音乐的相似程度,面积越大表示两段音乐的差距越大。
而Yongwei Zhu [14]等人则对传统的字符串匹配的检索方式提出了效率不高、鲁棒性有限的质疑:他们提出,由于变调的原因,导致传统的匹配方式效率低下,他们建议用音阶来对音乐的旋律进行特征表示。在论文中,音乐的音阶、大调和小调等音乐特征得到了建模,基音则作为音乐检索的主键值。他们的数据库中包含大概3000首歌曲,命中率达到85%以上,并且搜索时间是传统方法的三分之一。
近期研究的重心则主要放在音乐检索的实际应用上:致力于解决音乐检索技术在实际应用中所遇到的问题以及在不同的环境中检索音乐的问题。
比较有趣的是Keiichiro Hoashi [15]他们提出的根据用户的音乐喜好来检索音乐的方法:目的是能够让用户有机会检索到自己可能喜欢但却从未听过的歌曲,采用的方法是粗略描述喜爱派别再参考用户反馈,即首先根据用户对不同歌曲流派的偏好生成用户的个人偏好信息,再根据用户的相关操作来修改和完善其偏好。他们使用TreeQ 树储存代表用户偏好的向量,以方便存储、查询和匹配。
近期还有Cheng yang [16]基于P2P网络对音乐特征表示和提取方式进行改进的方案。传统的密集型的音乐检索技术在如今的P2P网络环境中并不适用,因此他提出了有效的音乐分解和并行化处理的方法,以适应P2P网络的需求,提高用户的检索效率以及利用用户的剩余资源。
研究内容与论文结构
本文针对基于样例的音乐检索技术,研究基于旋律的音高字符串特征表示及匹配算法及其中涉及到WAV格式音频的预处理技术、音频短时过零率及短时能量的提取技术、基于短时能量的音频的音符划分技术、相邻音符的音高差表示技术、N-gram字符串划分及匹配技术等。
论文结构安排如下:
(1)第一章:绪论。阐述了基于样例音乐检索技术的研究背景及研究意义,并且介绍了近年来的一些主要的研究成果。
(2)第二章:基于样例音乐检索综述:首先介绍了一般性的基于样例的音乐检索系统的架构;其次,介绍了音频特征提取的相关技术:音频信号预处理以及基于旋律表示音乐特征的几种方式;第三,介绍了对于旋律表示的特征,有哪些特征匹配技术。
(3)第三章:系统设计概要及具体实现:简述了系统的主要开发平台,用系统用例图描述系统需求,并且给出了数据库设计框架;接下来,给出了系统具体实现的细节与关键算法:包括数据库具体设计思路、音乐信号预处理、基于旋律的特征提取、N-Gram特征匹配算法等等。
(4)第四章:系统测试及分析:针对系统的特征提取模块、N-Gram特征串划分模块、哈希索引表模块,以及N-gram快速匹配模块进行了测试,并且对测试结果进行分析。还罗列了系统开发过程中通过调试所发现的问题及解决问题的方案。
剩余内容已隐藏,请支付后下载全文,论文总字数:22562字
相关图片展示: