论文总字数:20814字
目 录
第一章 绪论 1
1.1选题的背景及意义 1
1.2国内外研究近况 1
1.3研究内容 1
第二章 需求分析 1
2.1系统功能分析 1
2.1.1数据采集与解析部分 2
2.1.2数据录入数据库部分 3
2.1.3界面显示部分 3
第三章 技术简介 3
3.1相关工具及环境简介 3
3.1.1 lxml简介 4
3.1.2 selenium简介 4
3.1.3 PyMySQL库简介 5
3.2 相关技术简介 5
3.2.1 selenium chromedriver 5
3.2.2 页面解析(XPath) 5
3.2.3 C#与python交互技术 7
第四章 系统设计 7
4.1系统结构设计 7
4.2功能模块设计 8
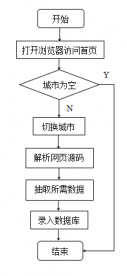
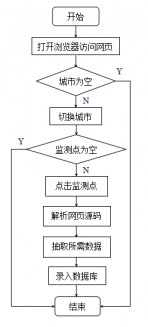
4.2.1抓取实时雾霾数据模块 8
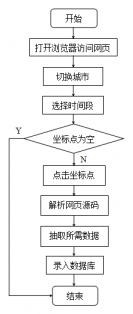
4.2.2抓取历史雾霾数据模块 9
4.2.3抓取全国城市排名模块 10
4.3数据库设计 10
4.3.1数据库E-R图设计 10
4.3.2数据库实体图设计 10
4.3.3数据库表设计 12
第五章 系统实现及测试 13
5.1系统实现 13
5.1.1系统结构实现 14
5.1.2数据抓取模块实现 19
5.1.3连接数据库实现 22
5.2 系统测试 22
第六章 结论与展望 26
参考文献 26
致谢 28
第一章 绪论
1.1选题的背景及意义
雾霾,从名字就可以听出来,将“雾”与“霾”组合起来,是一种空气污染现象,这种现象很早之前就已经存在,但它真正走进大众视野的导火索是2011年美国大使馆对PM2.5的持续播报行为。2014年1月4日,雾霾被正式确定为自然灾害其中的一种。2015年2月28日,《穹顶之下》第一次在人民网发布。这个由柴静自费推出的雾霾深度调查在国内引起轩然大波,人们开始更加深刻地意识到这种空气污染给社会发展及人类健康带来的严重影响。随着雾霾影响的范围越来越广,空气污染的形势愈发严重,对于雾霾问题的深入研究也显得愈发必要。全国各地建立了许多雾霾数据的监测站点,分析空气中形成雾霾的污染物浓度,发布雾霾相关信息。而在大数据时代,信息化的手段为雾霾相关数据的实时采集和汇总分析提供了便捷。雾霾地面监测数据采集与入库管理系统的建立使大范围长时间内庞杂的雾霾相关数据变得井井有条,便于推测雾霾天气的变化趋势,有助于对比发现雾霾变化的潜藏规律,为推进雾霾相关的深入研究提供数据支持。
1.2国内外研究近况
就数据抓取框架而言,目前比较流行的基于python的数据抓取框架有scrapy、pyspider等。Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。而Pyspider是一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器,是一套非常灵活的数据抓取框架。
就雾霾数据监测而言,目前,国内许多天气研究重点实验室开始尝试基于大数据与移动互联网提供气象服务,城市管理部门也根据初步的雾霾数据分析采取相应的治霾手段。而由微软亚洲研究院开发的Urban Air系统,可以通过大数据来监测整个城市当前时间的细粒度空气质量,并预测每个监测站未来时间的空气质量。目前该系统已经可以为全国七十多个城市预测空气质量,并且能够对一些城市群未来48小时的空气质量情况做出预测。
1.3研究内容
本文的研究内容是设计与实现一个雾霾地面监测数据采集及入库管理系统,实现将各个城市及监测点发布的雾霾数据解析、抓取并存入数据库的功能。
第二章 需求分析
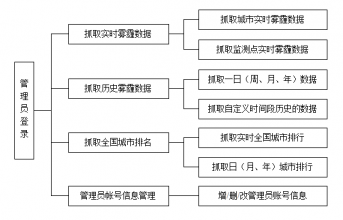
2.1系统功能分析
要设计与实现一个雾霾地面监测数据采集及入库管理系统,主要分为三个部分:数据采集与解析,数据录入数据库以及界面显示。
2.1.1数据采集与解析部分
需要准确地抓取真气网发布的相关雾霾数据,这部分数据由网站的三个不同模块中抽取出来,分别为实时雾霾数据、历史雾霾数据和全国城市排名表。具体功能需求如下:
- 抓取实时雾霾数据模块的的功能:
能够抓取网站首页显示的所有城市的实时雾霾数据,包括AQI指数、PM2.5浓度、PM10浓度、SO2浓度、NO2浓度、CO浓度、O3浓度、主要污染物和数据发布时间,数据在网站的显示如图2.1:
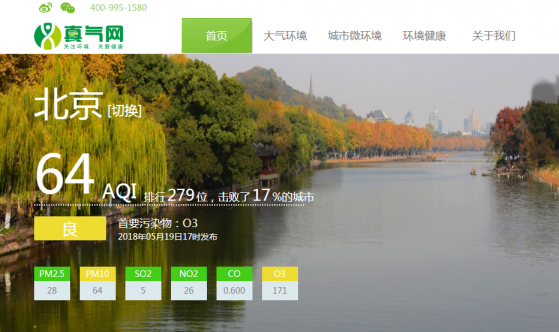
图2.1 网站首页的城市实时雾霾数据
能够抓取网站首页显示的所有监测点的实时雾霾数据,包括AQI指数、PM2.5浓度、PM10浓度、SO2浓度、NO2浓度、CO浓度、O3浓度、主要污染物和数据发布时间,数据在网站的显示如图2.2:
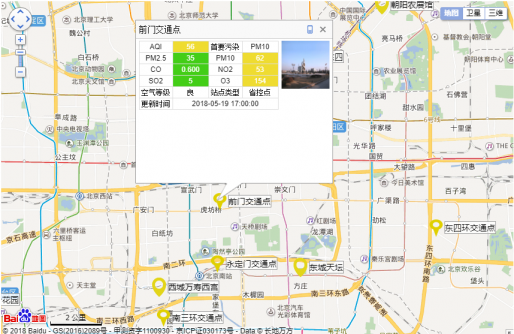
图2.2 网站首页的监测点实时雾霾数据
- 抓取历史雾霾数据模块的的功能:
能够抓取网站显示的24小时之内、最近一周、最近一月、最近一年的城市历史雾霾数据,包括AQI指数、PM2.5浓度、PM10浓度、SO2浓度、NO2浓度、CO浓度、O3浓度和数据发布时间,数据在网站的显示如图2.3:
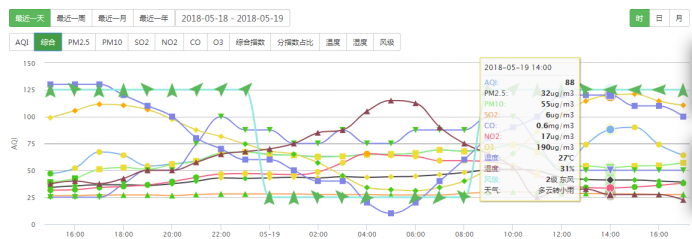
图2.3 网站的城市历史雾霾数据
- 抓取全国城市排名信息模块的的功能:
能够抓取网站显示的国内城市实时、日、月、年排序数据,数据在网站的显示如图2.4:
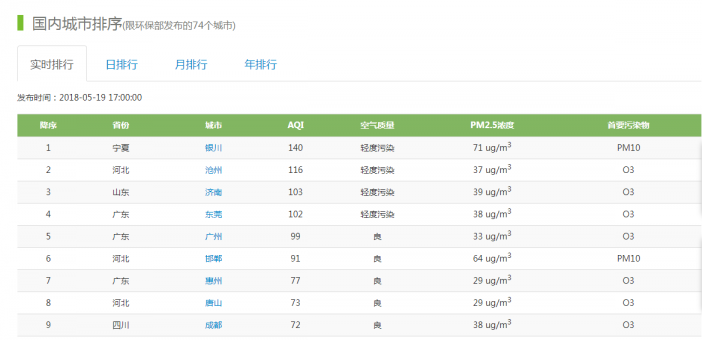
图2.4 网站的全国城市排行数据
2.1.2数据录入数据库部分
需要合理设计数据库,建立与抓取程序的连接,使抓取的数据及时存入对应的表中。
2.1.3界面显示部分
系统界面结构需清晰明了,不同功能分类需简洁易懂,能够进行基本的操作并展示操作的结果。
综合以上的分析,雾霾地面监测数据采集及入库管理系统的主要功能是实现从真气网上抓取发布的相关雾霾数据存入数据库,并且在系统界面可以显示抓取结果。
第三章 技术简介
3.1相关工具及环境简介
本次课题的编译环境情况如下:操作系统是Microsoft Windows 8.1,编程平台为PyCharm(编写python脚本)和Visual Studio2015(C#编写界面),所使用的编程语言是Python3以及C#,主要使用的第三方库有lxml库、selenium库、time库和PyMySQL库。
3.1.1 lxml简介
lxml是用于在Python语言中处理XML和HTML的功能最丰富且易于使用的库。它是第一个将libxml2快速强大的特性和python语言的易用性结合于一体的第三方库,解析网页具有比BeautifulSoup更高的性能。
Lxml既能够解析json又能够解析HTML,可以说是非常之强大。lxml这个库在解析HTML时,利用的是etree这个类。使用lxml.etree的方式:调用from lxml import etree
解析文本:
lxml.etree中提供了下列方法用于解析文本:
Fromstring() 用于解析字符串
HTML() 用于解析HTML对象
XML() 用于解析XML对象
Parse() 用于解析文件类型的对象
Xpath是XML路径语言,用于确定XML文档中的某个位置。本研究中就是使用Xpath来定位网页中所需的数据元素并进行抓取保存。XPath有其语法,有些许类似于正则表达式。在利用XPath获取网页文本时,如果对XPath了解不够深入,可以通过审查元素功能直接复制所需元素的XPath。
Lxml中支持一种类似于XPath的路径语言,叫ElementPath。里面提供了四种方法获取元素和文档树:
iterfind() 迭代所有符合条件的元素
findall() 以列表形式返回所有元素
find() 返回第一个元素
findtext() 返回第一个元素的text()
3.1.2 Selenium简介
Selenium是一个比较古老也比较流行的自动化测试库。它可以模拟真正的浏览器,在爬虫中主要被用于解决js渲染的问题。Selenium WebDriver直接通过浏览器自动化的本地接口来调用浏览器,如同是真正的用户在操控一样。Selenium库绑定提供了一个简单的API以使用Selenium WebDriver的编写功能或验收测试。Selenium提供了一个便捷的API来访问像火狐,IE,谷歌,Remote等浏览器。它目前支持2.7,3.5及以上的Python版本。Python中导入selenium库用于自动化网页浏览器交互。本研究中使用selenium chromedriver来调用谷歌浏览器打开网页抓取所需数据。在webdriver中,有专门的一个类,是用来进行鼠标、键盘的模拟操作的,那就是Actions类,以下与本文相关的Selenium WebDriver 中的常用事件:
(1)鼠标移动操作
Actions action = new Actions(driver);
action.moveToElement(Target);//移动鼠标至元素Target的位置上
- 鼠标左键点击操作
Driver driver=new Driver();
driver.findElement(By.xpath(xpath)).click();//通过XPath定位到元素并进行左键单击操作
或者:
Actions action = new Actions(driver);action.click();//鼠标在此时所在的位置做左键单击操作
action.click(driver.findElement(By.id(a)))//鼠标对通过指定的id值查找到的元素进行左键单击操作
- 使浏览器窗口最大化操作
driver.maximize_window()
(4)确保只在当前Target元素不可见的情况下才使其可见的操作
driver.execute_script("arguments[0].scrollIntoViewIfNeeded();", Target)
3.1.3 PyMySQL库简介
PyMySQL是在python3.X版本中用来连接mysql服务器并对数据库进行操作的模块。在本文的研究中与mysql数据库的连接操作以及对数据的处理也是以导入PyMySQL库为基础来进行的。
3.2 相关技术简介
3.2.1 selenium chromedriver
selenium是个很方便的自动测试框架,可以模拟出浏览器的行为,就像真正的用户坐在电脑后通过浏览器访问网站一样。selenium操控谷歌浏览器需要有chromedriver驱动的协助。通过chromedriver启动谷歌浏览器每次都是独立的,这样的启动模式非常适合自动测试环境。本文将使用selenium chromedriver的组合来操作浏览器以实现网页之间的跳转与控制。
调用selenium库的代码如下:
剩余内容已隐藏,请支付后下载全文,论文总字数:20814字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

