论文总字数:20445字
目 录
1. 绪论 7
1.1 研究问题的提出 7
1.2国内外研究现状 7
2. 分类 9
2.1 分类技术基础 9
2.2 分类器的评价标准 9
3. 数据流 10
3.1 数据流定义 10
3.2 数据流上的应用 11
4. 数据流上的分类 12
4.1 数据流上的数据挖掘 12
4.2 数据流上的分类的描述 12
4.3 数据流分类的应用 14
5. 数据流上的分类算法 14
5.1 数据流静态分布的分类方法 14
5.1.1 VFDT 14
5.1.2 ID3 16
5.2 数据流带概念漂移的分类算法 16
5.2.1 FLORA框架 16
5.2.2 CVFDT 18
5.2.3 C4.5 18
5.2.4 组合分类器分类法 19
5.2.5 贝叶斯数据流分类算法 19
6. VFDT算法的实现 21
6.1 VFDT算法的描述 21
6.2 VFDT算法运行环境 22
6.3 VFDT算法实现 23
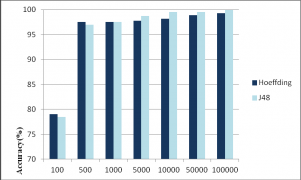
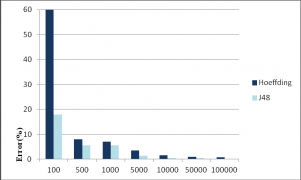
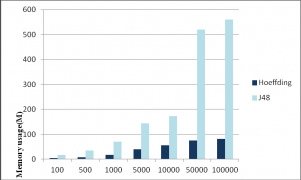
6.4 算法运行结果分析 24
7. 总结 25
7.1 数据流分类算法的分析和比较 25
7.2 研究心得 26
参考文献 26
致谢 28
数据流分类算法的研究
石岭峰
,China
ABSTRACT: In the background of computer networks and the era of big data, there has been a flood of data in the form of data stream. In addition, the classification is an indispensable data mining technology research. Classification is one of the most successful technology practical application of technology in data mining. Thus, the classification algorithm based on data stream model has become a hot research topic researchers, is central to this paper. This paper describes data streams concepts, introduces the specific application of the data stream classification and analyzed and compare a variety of data stream classification algorithm such as VFDT, CVFDT, CD4.5 and the like. So, we can facilitate data with different data characteristics of different classification algorithms. Finally, I used the weka to achieve the classification algorithm VFDT. And I compared VFDT and CD4.5 and received a more accurate comparison of results.
Keywords: Data Stream ; Classification ;Data Mining; VFDT
1. 绪论
1.1 研究问题的提出
当今时代正处于飞速发展的信息时代,人们的一言一行都会产生出数之不尽的数据信息。科技的发展大大提高了我们的生活水平,方便我们生活的同时也产生了大批数据,人们可以随时随地接触和制造许许多多的数据,电话、上网、电视到各种银行存取,手机支付等,背后都隐藏着大量的数据。海量的数据给人们带来方便的同时也带来了许多问题:第一,数据信息量太大,导致数据难以处理;第二,信息真实性难以保证,网络诈骗等行为时有发生;第三,信息安全性难以保证;第四,信息的形式各不相同,难以统一。为了解决这些问题,数据挖掘技术成为人们对数据研究的一大热门。
数据挖掘( )[1]是从大量的数据中挖掘出有价值的信息的过程,对人们在大量数据中提取有价值的信息有着巨大的作用。数据挖掘的一般步骤分为以下三部分:数据准备、数据挖掘和识别与评价,具体步骤如图1所示。
)[1]是从大量的数据中挖掘出有价值的信息的过程,对人们在大量数据中提取有价值的信息有着巨大的作用。数据挖掘的一般步骤分为以下三部分:数据准备、数据挖掘和识别与评价,具体步骤如图1所示。

图1 数据挖掘的一般步骤
数据挖掘涵盖了多个学术领域,包括数据库、人工智能、机器学习、统计学、知识工程、信息检索和数据可视化等。
此外,如今数据流的大规模出现对原本数据挖掘中的多次查询数据源中数据,甚至是历史数据的方式提出了挑战。数据流模型所包含的几乎无限的数据以及可能产生概念漂移等性质使得传统的数据分类算法无法针对数据流模型进行有效分类。
正是由于上述的一般数据的分类算法不能在数据流模型上得到良好的分类成果,这就有了本文研究的主题,数据流分类算法。
1.2 国内外研究现状
1988年左右数据挖掘技术出现,到了1990年后有了蓬勃的发展,目前数据挖掘领域已经取得了空前成功的研究成果[14]。正是如此,数据流的分类工作作为数据流挖掘工作中的不可缺少的一部分,基于数据流模型的分类同样是数据挖掘技术中的热门研究领域,也是本文的研究对象。
FL0RA[2]是由Widmer等人提出的第一个能处理概念漂移的数据分类系统。该系统使用了称为描述项的值对集合对概念进行描述,并且随着窗口不断向前进行滑动,不断对描述项进行动态地添加或删除。然而,FLORA框架同样有其难以解决的缺点,由于FLORA中包含的数据量很大,这就导致模型更新的代价很高,因此该系统无法满足处理具有实时性特征的数据流的要求。
Wang等[3]提出一个被命名为AWE[13]的模型,用于专门解决带概念漂移的问题。正是因为他们发现目前被提出的各类数据流分类算法都难以处理概念漂移,因此提出这个模型来对数据流进行有效分类,且通过实验证明AWE有很强的精确分类能力以及很好的解决概念漂移的能力。
Ganti等[4]开发出能在数据或是记录进行插入和删除等操作时很好地维护模型的算法,另外在各类增量数据挖掘模型中都可以使用这种算法。这种算法使用一类通用的架构,即两个数据集在经过数据挖掘后分别对其进行变化的检测。此类技术被定义为为两个算法:GEMM算法与FOCUS算法。这两个算法在决策树(Decision Tree)和频繁项集(Frequent itemsets)中能够起到很好的作用。
Domingos[5]等提出了VFDT算法。VFDT是一种基于Hoeffding树的决策树算法,这类算法将最佳属性定义为中结点,检验的规定是检验数据项个数是否符合Hoeffding边境的统计量。伴随着数据流的动态流向,CVFDT检验决策树中所有中间点,当一个结点的分裂属性能够被更好地替代时,可将此结点用以新的属性为根结点的子树替代。反复进行此步骤,使得不适用的结点不断被取代,CVFDT算法将动态调整相应决策树的结构以处理数据流的概念漂移现象。
 等[6]提出
等[6]提出 (
( ) 算法,即用于在传感器网中找出有趣的类型。这是一种扫描一次即可得出结果的增量更新算法,此方法的空间复杂度为
) 算法,即用于在传感器网中找出有趣的类型。这是一种扫描一次即可得出结果的增量更新算法,此方法的空间复杂度为 ,其中序列的长度用N表示,此外使用小波系数表示压缩信息并用来测试数据结构,并在小波域范围内利用线性回归模型进行预测。
,其中序列的长度用N表示,此外使用小波系数表示压缩信息并用来测试数据结构,并在小波域范围内利用线性回归模型进行预测。
W. Fan[8]研究的是对数据流分类时如何对历史数据进行准确使用的技术,且为了解决这一难题,开发出一种综合分类器的分类方式。每当有新的流动数据流入时时,将快速比较下列分类器的分类精度并选择—种分类精度高的分类器:先前使用的分类器、学习到的新型分类器、从分类完成的数据中选取与新流入的数据集相似的数据学习到的分类器以及从新数据中选取与分类完成数据相似的数据学习到的分类器。
国内外虽然在数据流分类的研究领域投入了大量的研究精力,但数据流分类中的难点以及挑战还是相当严峻的,各种算法的准确率都不能得到很好的保证。人们对于数据流分类不断增长的使用需求将推动着这个研究领域不断取得新的研究成果,不断取得重大研究突破。
2.分类
数据分类是数据挖掘中一个至关重要的步骤,也是如今所有数据挖掘技术里投入实际使用取得效果最好的技术之一。分类的目的是根据训练样本集学习一个分类器,使用这个分类器将数据集中的数据分配为特定的类别。
2.1 分类技术基础
数据分类[7]的具体实现过程具体可以被分为两个部分,如图2所示。
第一部分,建立可用的模型,用具体模型确定给定的数据集。在这个过程中,模型可以通过分析数据库元组(训练样本)的属性来构建。假设每一个数据库元组分别被定义为一个类别,则可以分别用一个类别号表示具体元组。由于这部分操作给定了每个数据元组的类别号,所以被称为“有指导的学习”。
第二部分,使用已经建立的模型分类具体样本。首先,我们必须对已经建立的分类模型进行精度预测。分类模型精度预测的方法有很多,包括:保持法、k字交叉验证法、分层交叉验证法和留一法等。分类模型对所给定的样本上的预测精度是被正确分类的样本占分类样本总数的百分量,若分类模型的预测精度在可以承受的范围内,那么该模型就能够被用于新样本的分类。
剩余内容已隐藏,请支付后下载全文,论文总字数:20445字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

