论文总字数:21373字
目 录
摘要 1
Abstract 2
1 绪论 3
2 基础知识简介 4
2.1 量子理论发展概述 4
2.2 量子计算术语 4
2.2.1量子叠加 4
2.2.2 量子纠缠 4
2.2.3 量子比特 5
2.2.4 量子逻辑门 5
2.3经典的机器学习聚类算法 6
2.3.1 k-means聚类算法 7
2.3.2 k-近邻聚类算法 8
2.3.3 决策树算法 8
3量子聚类算法概述 9
3.1量子流形嵌入 10
3.2量子层次聚类 10
3.3基于最近距离的量子聚类算法 11
4 基于最近距离的量子k-means算法 11
4.1空间中点与距离的量子表示 11
4.2算法步骤 12
4.3效率分析 14
5 基于近邻距离的量子聚类算法及其改进 15
5.1 Wiebe算法回顾 15
5.1.1 假设 16
5.1.2 算法步骤 16
5.2改进的Wiebe算法设计 18
5.2.1 算法思想 18
5.2.2 算法详细步骤 19
5.2.3 效率分析 20
6 总结与展望 21
参考文献: 21
致谢 23
量子聚类算法分析与研究
舒帆
, China
Abstract:Quantum clustering algorithm is a new algorithm developed on the basis of the classical clustering algorithm. It use quantum method to rewrite the clustering algorithm to solve the problem of slow speed and expensive cost when dealing with large amounts of data in high dimension. And bring exponential acceleration for classical clustering algorithm. In this paper, we first introduce basic knowledge, including the classical clustering algorithm and quantum computing. After that, on the basis of the further study of quantum clustering algorithm , we proposes a quantum k-means algorithm based on the nearest distance. We construct the entanglement state of the centroid of cluster and the point to be classified, an auxiliary particle is adjoined. Then we measure the auxiliary particle and then get the distance between two points. Finally, we study the quantum clustering algorithm based on nearest neighbor and give out some improvement. By clustering sample points, we reduce the search scope of neighboring points, thus bring algorithm acceleration.
Keywords: clustering algorithm; quantum computing; k-means algorithm; k-nearest-neighbor algorithm; exponential acceleration
1 绪论
机器学习是人工智能的核心,是计算机科学的一部分。其主要目的是让机器智能地进行“学习”,以原有的经验来处理新的数据。机器学习在计算机科学,金融分析,机器人学,图像分析与处理,生物信息学等方面有巨大的应用。机器学习算法大体可以分为两种:有监督的机器学习算法和非监督的机器学习算法。对于有监督的机器学习算法,我们会在开始时就给出有特征标签的训练集,然后基于这些训练集,将新输入的数据进行分类。典型的有监督机器学习的例子就是垃圾邮件的分类。当一封邮件到来时,我们依据人们已经分类过的邮件的特征来确定其属于垃圾邮件还是有用的邮件。而对于非监督的机器学习算法,我们在开始时并没有给出带特征标签的训练集来做为分类的标准。非监督学习不用对数据实例进行标记或其他形式的指导训练发现数据的结构。这就使得非监督学习在容易获得数据但标记的花费昂贵或很难标记的情况下,有着诱人的应用。在没有指导下的学习算法,必须自己根据数据实例确定数据的结构。也许最明显的方法是着手研究数据的特征向量,观察特征空间中的最普遍的方向。非监督机器学习的一个例子就是从一幅画中找出哪些像素属于物品,哪些像素属于背景。
聚类算法在机器学习中发挥重要的作用。有监督的聚类算法包括k-近邻算法,支持向量机等。非监督的聚类算法包括k-means算法等。然而,近些年,随着信息的迅猛发展,全球每一年数据的增长都达到了20%左右,高达几百艾字节[1]。数据的规模越来越大,同时数据的特征也更加多维。近些年的研究和应用尤其关注于大数据机器学习问题。机器学习任务经常包括在高维度空间中操纵并分类大量的向量。用经典的算法来解决这一问题需要花费向量数量和空间维度的多项式的时间,暴露出了耗时长,能耗大的问题。量子计算机擅长操纵大张量积中的高维向量。为了解决经典聚类算法的这些问题,人们想到了用量子计算,提出了量子聚类算法来为经典算法带来加速。
在过去的十年中,物理学家已经证明了量子系统在信息处理方面强大能力。大量的量子机器学习算法被提了出来。比如量子人工神经网络[2,3,4],绝热算法[5],量子K-近邻算法[6,7,8]等。本文我们讨论量子k-means算法和量子k-近邻算法。
在第二章我们介绍了本文所需的基础知识,包括经典的机器学习算法,如k-means算法,k-近邻算法,决策树算法,量子理论的一些基础知识以及发展过程。在第三章,我们给出了一种量子版本的k-means算法。第四章中我们介绍了量子k-近邻算法的特殊形式,量子最近邻居算法,并给出了我们的一些改进。第五章我们给出了结论。
2 基础知识简介
2.1 量子理论发展概述
量子理论起源于经典物理学体系中出现反常现象,即黑体辐射,原子稳定性等。1900年,普朗克在两条特殊的热力学假设下,推导出了与实验现象相吻合分布定律,这就是普朗克黑体辐射定律,并由此提出了能量子假说,为量子理论的建立打下了基础。1905年,爱因斯坦提出了光量子假说,1913年玻尔提出的定态原子理论大大加速了量子论的发展。1923年德布罗意提出了德布罗意物质波理论。1925年海森伯等人建立了矩阵形式的量子力学。1926年,薛定谔从哈密顿-雅可比方程出发,建立了波动力学,量子理论得以建立。但到20世纪90年代,量子理论才引起了人们的注意。Short量子因子分解算法[9,10]和Grover搜索算法[11]的提出,推动了量子理论的研究。这两个算法也展现出了量子计算机在处理信息和数据计算方面的强大能力。量子的并行计算为经典算法带来了极大的加速。最近几年,量子加速因解决因式分解,量子模拟和最优化问题而被人们所知晓。量子计算在数据处理,机器学习和分类等方面都展现出了较好的能力。
2.2 量子计算术语
2.2.1量子叠加
量子态的叠加性源于微观粒子“波粒二象性”的波动“相干叠加性”,是将一个以上的信息状态累加在同一个微观粒子上的现象。量子态可以叠加的物理特性是实现量子并行计 算的基础。例如 就是两个量子比特的叠加。
2.2.2 量子纠缠
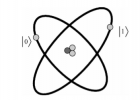
量子纠缠状态指的是两个或多个量子系统之间的非定域,非经典的关联,是量子系统内各系统或各自由度之间关联的力学属性。(一个以上的微观粒子因微观系统的特性相互交缠在一起的现象)。量子态能够纠缠是实现信息高速的不可破译通信的理论基础。
当量子比特列的叠加状态无法用各量子比特的张量乘积表示时,这种叠加状态就称为量子纠缠状态。例如,有一量子叠加状态
(2-1)
无论采用怎样的方法都无法写成两个量子比特的乘积。这个叠加状态就称为量子纠缠状态。量子纠缠状态是量子信息理论中特有的概念。尽管处在纠缠的两个或多个量子系统之间不存在实际物质上的联系,但不同的量子位却会因为纠缠而彼此影响。正是由于“纠缠”的神秘性,使得一个量子的状态将同与之发生纠缠的另 一个量子的状态相关,似乎在它们相互之间的关联性比紧密结合的两个原子还强。
2.2.3 量子比特
相对于经典信息的基本存储单元比特(bit),量子信息的基本存储单元为量子比特(qubit)。在经典二进制存储中,我们用经典状态0和1来表示数据。而在量子系统中,我们用两个极化状态 和
和 来对应经典状态中的0和1。量子比特通常处于两个极化状态的线性叠加状态,即
来对应经典状态中的0和1。量子比特通常处于两个极化状态的线性叠加状态,即
 (2-2)
(2-2)
公式中α和β是一组复数,被称为量子概率幅。α和β满足归一化规则,即
 (2-3)
(2-3)
剩余内容已隐藏,请支付后下载全文,论文总字数:21373字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

