论文总字数:13532字
目 录
1 绪论 4
1.1 研究的背景及意义 4
1.2 国内外研究现状 4
1.3 本文的研究内容及研究方向 5
1.4 本文的文本组织结构 5
2基于CNN的模型架构简介 6
2.1 深度学习进行识别的优势 6
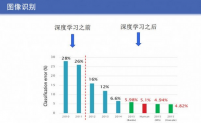
2.2 深度学习的思想 7
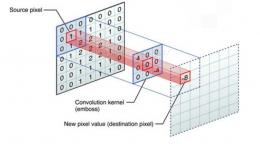
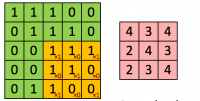
2.3 卷积操作 8
3 图像的简单预处理 8
3.1 二维点阵图像 8
3.2 图像校正 9
3.3 图形去噪 11
3.4 文字图像切分 11
4 文字的特征提取 12
4.1 字符的归一化处理 12
4.2 空间轮廓特征 13
4.3 方向线素特征 13
5建立CNN架构的训练模型 14
5.1  深层卷积网络 14
深层卷积网络 14
5.2 训练加速策略 15
5.3 实验结果分析 15
6 总结与展望 18
6.1 总结 18
6.2 展望 19
参考文献: 19
致谢 21
基于深度学习的文字识别
张琪
,China
Abstract: With the development of computers, the Internet and mobile communication technology, modern smart phones integrate high-pixel, high-resolution camera has become one of the important functions of mobile phones, which makes people at any time and place can shoot images, And even analyze, identify and process images based on the accumulated set of mass graphs in order to obtain useful information from them. Further, when image analysis, processing and recognition techniques are applied to large-scale textual data, this is a text recognition technology, such as a license plate recognition technology that has been widely recognized and applied. The traditional identification technology needs to manually extract the text features in advance, construct the feature library, and use this as a sample to identify the text through direct matching. The drawback of this kind of technology is that the labor cost is high and the font type difference is large. Low, can not meet the needs of practical applications. In this paper, the multi-level convolution neural network depth learning network architecture is established. Secondly, after the simple image processing of the printed image font, the feature data sets are extracted and the feature data sets are divided into training sets and Test set; third, the use of training set to CNN architecture self-learning and model. Finally, the trained CNN model is tested by using the test set. The experimental results show that the CNN text recognition model established in this paper is effective in terms of accuracy and recognition speed.
Key words:Deep Learning;image identification; CNN ;Text recognition
1 绪论
1.1 研究的背景及意义
最近这些年来,深度学习可以说火遍全球各个国家,似乎只要任何领域和它有所联系,就瞬间变得高端,变得大气,变得上档次。事实上,深度学习技术发展到今天也就十年出头的样子。人类作为高级动物,我们的感官视觉是一级一级来不断向上处理眼球捕获的信息。信息经过神经—中枢—大脑的一连串过程,最终我们可以判定看到的是什么物体。这个过程是一个不断向上、不断高度抽象的过程。深度学习简单来说就是模拟人脑的过程,用我们人脑解释看到的物体的视觉处理方法来处理输入的数据。处理后我们就得到了一些需要的特征,然后逐级提取,上面那层的的输出又作为下面那层的输入,不断这样进行层级提取,从而获得更抽象的特征表达。近年来,国内外大型高科技互联网公司如阿里巴巴、腾讯、谷歌、苹果、 等相继投入大批工程师进行与深度学习相关的技术开发,在无人驾驶、手势识别、图片搜索、流体模拟等领域取得可喜的进展。基于深度学习的文字识别是一项多学科的综合型课题,与多种学科千丝万缕的联系。一方面,各学科的发展给深度学习提供了工具,另一方面,深度学习的进一步发展,也势必将促进各个学科的综合发展。因此有着非常深远并且重大的研究意义。
等相继投入大批工程师进行与深度学习相关的技术开发,在无人驾驶、手势识别、图片搜索、流体模拟等领域取得可喜的进展。基于深度学习的文字识别是一项多学科的综合型课题,与多种学科千丝万缕的联系。一方面,各学科的发展给深度学习提供了工具,另一方面,深度学习的进一步发展,也势必将促进各个学科的综合发展。因此有着非常深远并且重大的研究意义。
1.2 国内外研究现状
计算机计算速度远超人类,如果把它应用到识别字符的话,就能减轻人们在生产和生活中的劳动量,提高了劳动效率。最开始提出光学文字识别的是德国的一位科学家,随后美国的另一位科学家提出可以利用计算机技术进行文字识别的理论。英文字符是由少量字符组成的,结构较为简单,最先进入到实用阶段。随着人工智能的跨越式的发展,文字识别技术也得到了飞跃的发展。从最开始的机器扫描的文档文件的识别,到后来的银行卡等证件的识别,再到技术已经很成熟的人脸识别和车牌识别,文字识别技术借助深度学习技术越来越提高识别率。国外方面, 年美国科技巨头公司谷歌提出来谷歌大脑计划,利用超多并行的
年美国科技巨头公司谷歌提出来谷歌大脑计划,利用超多并行的 训练深度学习模型,获得了巨大成功成功。前不久,发布了一项新的机器翻译技术,采用了
训练深度学习模型,获得了巨大成功成功。前不久,发布了一项新的机器翻译技术,采用了 而不是传统的
而不是传统的 ,正确率超越了此前被认为是龙头的谷歌机器翻译。而且速度上更是快了
,正确率超越了此前被认为是龙头的谷歌机器翻译。而且速度上更是快了 倍,创造了新的机器翻译的世界纪录。国内方面,
倍,创造了新的机器翻译的世界纪录。国内方面, 年
年 月,百度成立
月,百度成立 (简称
(简称 ),李彦宏作为百度的
),李彦宏作为百度的 ,亲自任院长。阿里巴巴的阿里云人工智能机器人小Ai也成功预测我是歌手的前三名。国内文字识别研究工作发展迅速,出现了清华紫光、汉王等一大批文字识别技术研究公司。目前文字辨别识取领域中
,亲自任院长。阿里巴巴的阿里云人工智能机器人小Ai也成功预测我是歌手的前三名。国内文字识别研究工作发展迅速,出现了清华紫光、汉王等一大批文字识别技术研究公司。目前文字辨别识取领域中 技术,作为最开始就被重点研究的方向技术,已经得到广泛使用,在实现海量银行业务凭单对账单识别、物流货物单批量识别、护照精准识别、身份证银行卡等识别方面已经很成熟。可以说,深度学习是近些年来来最为热门的研究方向。
技术,作为最开始就被重点研究的方向技术,已经得到广泛使用,在实现海量银行业务凭单对账单识别、物流货物单批量识别、护照精准识别、身份证银行卡等识别方面已经很成熟。可以说,深度学习是近些年来来最为热门的研究方向。
1.3 本文的研究内容及研究方向
本文介绍了多层次的卷积神经网络深度学习网络架构,然后介绍图像的基本处理以便于使后面的训练模型数据准确。最后介绍一种基于 的一种模型,以便于实现文字识别。
的一种模型,以便于实现文字识别。
1.4 本文的文本组织结构
第一章 绪论
本章简单介绍了选题的目的和意义、国内外的近年来的研究现状、本文的主要研究内容和主要研究方向。
第二章 基于 的模型架构简介
的模型架构简介
本章主要介绍了深度学习的优势,然后介绍深度学习的基本思想和原理。也对卷积神经网络中重要的卷积部分进行简单介绍。
第三章 文字的简单预处理
剩余内容已隐藏,请支付后下载全文,论文总字数:13532字
相关图片展示: