论文总字数:11189字
目 录
摘要 1
1.绪论 1
1.1引言 1
2.预备知识 1
2.1 马尔可夫链 1
2.2状态转移图 2
2.3 隐马尔可夫模型的主要内容 3
3.汉字马尔科夫模型的建立和应用 7
3.1转移概率矩阵 7
3.2马尔科夫模型主要代码 9
3.3马尔科夫模型的应用 11
3.4 纠正汉字输入顺序 12
4.结论 13
参考文献 13
致谢 14
汉字中的马尔科夫模型
刘兴鑫
China
ABSTRACT:Hidden Markov model is a kind of important prediction model. As a special kind of forecast, it is used in voice recognition and Grammar prediction. In this paper, we have summarized and refined it, including the corresponding algorithm and the derivation process of various problems, and the use of it to the Chinese characters, the establishment of Chinese characters Markov model.
Key words:hidden Markov model, forward algorithm, Markov prediction method.
1 引言
马尔科夫链是以安德雷 安得耶维奇 马尔科夫教授的名字命名的,马尔科夫模型是的一种重要的统计模型,在20世纪初被运用于股市中股票的浮动,当其结合布朗运动进行研究时,发现其满足时间与热量的某个函数方程,马尔科夫由此深入探讨,发现了马尔科夫时间离散过程与空间离散过程。进年来在排队系统,语音识别,库存系统,网页投票等方面都有重大应用。[1]其中在语音识别领域最早运用到隐马尔科夫模型,之后随着模型的不断发展和新的应用领域不断涌现出来。隐马尔科夫模型本质有两个状态类型,分别为可观测状态和隐藏状态。[2]本文通过对汉语马尔科夫模型的研究,实现了运用编程语言构造简单马尔科夫模型的可行性。并且实现了该模型在实际生活中的应用。它在建立汉字模型过程中起了非常重要的作用,无论在理论研究方面还是在实际应用方面都有着十分深远前景,如今对于该模型的暂留性,常返性,以及该过程中的大偏差原理都还在由各个领域的专家学者们探讨中,而对于本文建立的汉字马尔科夫模型有着计算量小、建模简单,分率高等特点。
由于人脑需要把顺序不正确的汉字重新排列,这样增加了人脑处理信息所需要的时间,还加大了人脑处理信息的负担。造成了阅读这些顺序不正确的汉字的句子,人脑发出疲劳信号。当然,汉字顺序颠倒错乱后,读者的阅读理解正确率仍为92%,这说明读者识别到那些词素位置颠倒的错词以后,仍能激活正确的词 ,从而获得语义。而计算机网络如果能建立模型,在这个模型中的任何时刻的状态都与上一时刻的那些时刻的状态无关,便能使计算机进一步向人工智能发展。
目前隐马尔科夫模型在国内外都有广泛研究,在学术方面目前最前沿的发展也有很多分支。列如从其本身结构改进,或从组合模型的角度出发,找到隐马尔科夫模型与其他模型的交织点。[3]而大部分国内外公司的研究则致力于将其运用于语音人工合成将自然语言转换成搜索指令,简化用户输入门槛,发展出真正意义上的神经心理学搜索引擎。
本文主要介绍了用隐马尔科夫模型的方法来推测汉字的输入习惯,隐马尔科夫模型基本概念和它的构造方法,还有如何解决纠正汉字顺序错乱的问题的方法。
2 预备知识
2.1马尔科夫链
马尔科夫过程是一种无后效的过程,它与某个系统的状态相对应,每间隔一段时间这些状态就要转变一次,而在此系统中的某个时刻的状态只依赖于它前一时刻的状态,不被其他时刻的状态变化影响。这样一来此随机过程中的每个下一时刻状态的概率都可以由当前状态确定下来,简而言之马尔可夫链模型是具有马尔可夫性质的随机变量序列,这种随机序列称为是非独立的且有记忆的。
严格形式定义如下:
设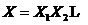 是一个随机序列。若对于任何
是一个随机序列。若对于任何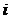 ,都有
,都有
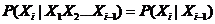
则称X为马尔科夫链。
若对于任意时刻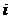 ,都有
,都有
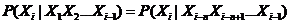
则称X为n-阶马尔科夫链。
2.2 状态转移图
普通的马尔科夫链可以由如下两个结构表示:
(1)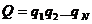 含马尔科夫链的N个状态。
含马尔科夫链的N个状态。
(2)由转移概率pij组成的矩阵:每个pij表示从该状态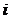 转移到状态j时的概率 :
转移到状态j时的概率 :
P=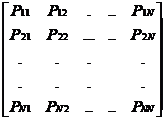
可用状态转移图表示,例如
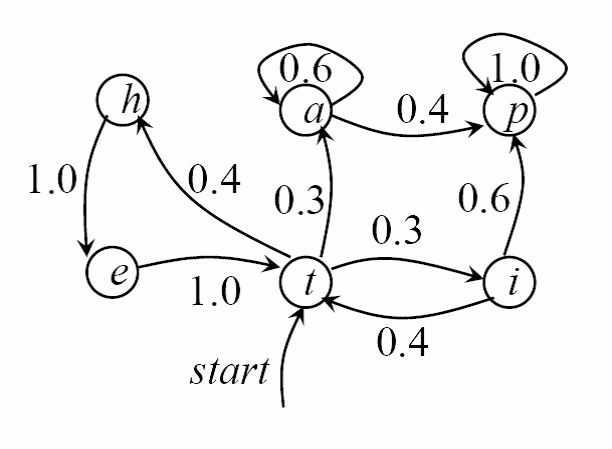
综上所述,状态转移用从一个状态指向下一个状态的箭头表示,状态对应的转移概率用图中指向下一状态的箭头上的数字表示。可以看出:给定随机过程中的状态概率,对于状态集合(h,e,t,a,p,i)中的任一元素,该元素指向下一个元素的箭头上的概率相加等于一。由此可以得出,马尔科夫模型可看作是独立于过去且仅仅由随机过程中的当前状态概率决定的非确定有限状态自动机。
2.3 隐马尔可夫模型的主要内容
隐马尔科夫模型在生物信息学,语音识别以及其他许多领域都有广泛应用。简单马尔科夫链中状态是直接可见的,但在隐马尔科夫模型中,状态不直接可见,需要通过输出符号来判断其下一个隐藏状态。在这个随机过程的状态变更中,其主要考虑两种状态,包括可观测状态与隐藏状态。在隐马尔科夫模型中可观测符号与潜在隐藏转移没有一一对应关系。[5]因此,仅仅通过查看生成的观测符号不再能分辨模型处于哪一个隐藏状态。标准的隐马尔科夫模型通常用以下五个元素来描述:
(1)模型中状态的个数。
(2)隐藏状态的所有可能的观测符号。
(3)状态转移概率矩阵。
(4)隐藏状态的观察概率分布。
( 5 ) 初始概率分布。
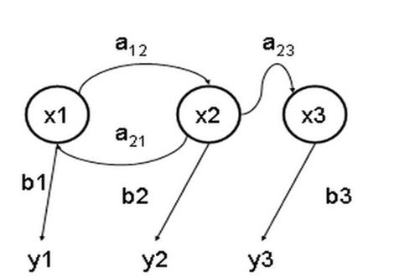
上图是简单的隐马尔科夫模型的状态转移图,图中圆圈表示隐藏状态,可观测序列用y表示,a表示状态转移概率,b表示输出概率。
当隐马尔科夫模型作为随机有限自动机处理更为复杂的观测序列时,其构成如下:
(1) 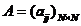
表示状态转移概率矩阵
(2) 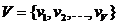
表示隐藏状态的观察符号集合。
(3) 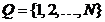
表示隐藏状态集合。
(4) 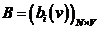
表示观测似然度矩阵
(5) 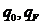
表示Q之外的两个状态:开始状态与结束状态。
上述隐马尔科夫模型符合如下三个假设:
(1) 输出独立性假设:隐藏的状态和可以观察的符号之间有某种概率上的联系。任意时刻,隐藏状态决定了该观测符号的概率分布,不被除此之外的因素变化影响: 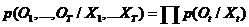
(2) 马尔科夫假设:状态构成一阶马尔可夫链: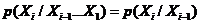
(3)不动性假设:状态与具体时间无关:
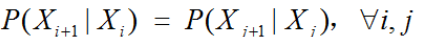
则上述定义的隐马尔科夫模型可表示如下:
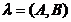
隐马尔科夫模型中的难点是从可观察的随机序列中确定该过程的隐含参数(如:隐藏状态的观察概率分布,状态转移概率矩阵等),然后利用这些参数来作进一步的分析。
剩余内容已隐藏,请支付后下载全文,论文总字数:11189字

