论文总字数:24324字
目 录
摘要: III
1 绪论 1
1.1 选题背景与意义 1
1.2 国内外研究现状 1
1.3 本文研究内容 1
1.4 本文结构安排 2
2 相关理论和技术介绍 2
2.1 数据采集相关技术介绍 2
2.2 大数据相关技术介绍 3
2.2.1 数据存储 3
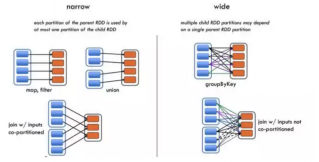
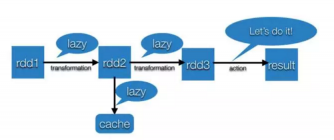
2.2.2 分布式计算 4
2.3 分类系统综述 6
2.3.1 文本分类介绍 6
2.3.2分类算法 7
2.3.2.1朴素贝叶斯 7
2.3.2.2逻辑回归 8
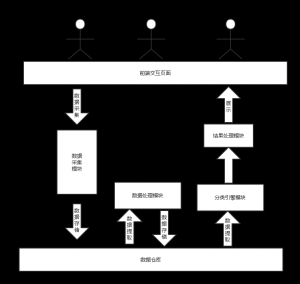
3 基于Spark的网络数据采集与处理系统的设计 9
3.1 系统背景 9
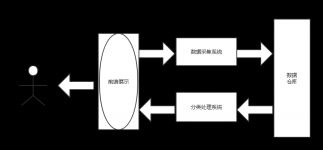
3.2 系统架构 10
3.2.1整体架构 10
3.2.2数据采集模块的设计 11
3.2.3数据处理模块的设计 12
3.2.4分类引擎模块的设计 12
4 基于Spark的网络数据采集与处理系统的实现 13
4.1数据采集模块的实现 13
4.2数据处理模块的实现 14
4.2.1 构建情感词典 14
4.2.2 进行文本分词 15
4.3分类引擎模块的实现 16
4.3.1朴素贝叶斯文本情感分类模型 16
4.3.2逻辑回归文本情感分类模型 19
5 实验结果与分析 21
5.1 实验环境 21
5.2 实验数据与结果 21
6 总结与展望 23
6.1 总结 23
6.2 未来展望 23
参考文献 24
致谢 30
基于SPARK的网络数据采集与处理系统设计与实现
孔炜
, China
Abstract:Along with the development of technology and economy, were collected and the amount of data storage and analysis showed explosive growth, facing such a magnitude data and common in real time using the data demand, driven by manual system to cope with. This gave birth to the big data and machine learning system, facilitate from data in learning and automatic decision. Data were input as a library collection and the writing of the crawler Tmall network of notebook computer product reviews, combined with Apache spark for data analysis tool mllib using suitable the machine learning algorithm and the existing network reviews as training data set, and on the data set for training, the training it is concluded that the classification model, and use cross validation method, using the training data set to evaluate the model in a new data set on the accurate rate and accurate rate reached 80%, get more accurate classification engine. The comment text classification engine, marking the output results, to achieve to grab the new comment text sentiment classification, distinguish from bad review.
Key words: Data acquisition; Spark; Cross validation; Text sentiment classification;
1 绪论
1.1 选题背景与意义
随着互联网的高速发展,大数据时代已经降临。随着“双十一”等热门事件的兴起,人们也逐步地意识到数据的价值性,并且尝试挖掘数据里所蕴含的巨大的价值。文本情感分析也是大数据挖掘中一项比较热门的研究。文本情感分析是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。其中,文本情感分类是文本情感分析中的关键问题。现在,人们越来越喜欢并习惯针对某一个热门事件或者物品发表自己的评论,也有越来越多的人们习惯结合他人的评论,对事件做出看法和决定,比如:微博上热门事件的评论,淘宝上商品的评论信息等。基于互联网的开放性,人们乐于提出本身的看法、分享自己的情感,同时也创造了新的价值。无论是个人还是企业,都可以通过研究这些信息,做出相应的决策。这些信息的增加与膨胀,也促使了文本情感分析成为了热门研究领域之一。
大数据是用来描述和定义蓬勃发展的经济和科技所产生的海量的数据,而电子商务的海量数据就是典型的代表之一。随着电子商务的蓬勃发展,越来越多的人们习惯并喜欢网上购物,几乎每时每刻都会有新的在线商品交易记录、商品评论等信息产生,同时,这些数据还在呈现出指数级上升的趋势,这也促使了电商网络上产生的数据符合大数据的部分特征。发展到今天,电商网络的数据已经达到了PB级别,并且规模还在不断增长。在这样的背景下,依靠人工处理已经跟不上发展,结合机器学习和统计模型等方法更适合对海量的数据进行挖掘。
为了处理海量的数据,无论是效率还是规模,单机分析算法都已经难以满足需求,需要研究出适合大数据分类任务的计算模式。在这一点上,云计算是个很好的选择。通过在集群上搭建分布式架构,可以弥补单机上的不足,并且效率和规模上都可以得到一定的提升。
1.2 国内外研究现状
随着计算机科学的进步,文本情感分析的研究得到了长足的发展,国内外很多的企业、学术机构以及个人对其进行了许多研究与应用。国内北京大学的李素科教授提出了一种针对文本的半监督式的分析方式,Alibaba将文本分析技术运用于电商领域;国外的 Google利用文本分析技术对邮件服务Gmail中的垃圾邮件进行了很好的识别, Square也用分类技术将信用卡持有者分为不同的风险等级;。
1.3 本文研究内容
由于在庞大的数据量下,单机的分类算法并不是很高效,需要新的计算模式对情感来分类。因此,本文运用机器学习算法,结合当今比较热门的云计算技术,搭建Spark计算框架来处理文本的情感分类问题。通过整合已有的情感词典,进行词语级别的情感识别,利用朴素贝叶斯算法和逻辑回归算法,构建出情感分类模型,并在测试数据集上对模型进行评估。最后,对新抓取到的网络数据执行情感分析。
1.4 本文结构安排
本文通过构建分布式平台,结合Spark的MLlib,对大规模的网络数据的文本情感分类系统进行设计与实现。本文的结构安排如下:
第一章:绪论。阐述选择Spark框架的优势,并且探讨国内外的研究状况,对本文的研究内容以及结构进行阐述;
第二章:介绍构建基于Spark的数据收集与处理系统所需的理论知识和开源技术,包括网络爬虫技术、分布式文件系统HDFS、Spark的原理和核心以及机器学习中的分类算法;
第三章:介绍基于Spark的系统的设计,包括整体架构的设计、数据采集架构设计、文本分类模块的设计等。
第四章:介绍基于Spark的系统的实现,使用Python语言完成网络爬虫的编写,同时基于朴素贝叶斯算法和逻辑回算法,并结合Spark的MLlib库,实现分类引擎。
第五章:在集群上结合较大数据集,运行编写的Spark程序,测试模型的准确率,并且预测新的数据,得出结论。
第六章:总结与展望。
2 相关理论和技术介绍
2.1 数据采集相关技术介绍
我们进行文本情感分类,需要大量的文本数据。除了已有的公开数据集之外,我们可以通过编写网络爬虫程序来抓取公开的网络数据。本文选择编写网络爬虫程序来抓取公开的网络数据——天猫网上的商品评论数据。我们使用Python语言,结合应用框架Scrapy来进行数据的爬取。Scrapy使用了Twisted进行网络通讯,架构的如下图所示:
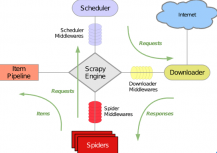
图2-1 Scrapy架构图
其中,Scrapy Engine是整个框架的核心,进行数据的处理;Scheduler接受Scrapy Engine的请求,决定要抓取的URL;Downloader用来下载网页的内容;Spiders是实体,用来从页面取得所需信息;Item Pipeline用于Item的实体化,并且剔除不必要的信息。
2.2 大数据相关技术介绍
2.2.1 数据存储
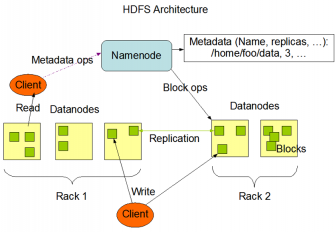
当用爬虫程序抓取到数据后,我们需要将数据进行存储,由于Spark是一个开源框架,并且能够兼容Hadoop生态系统,因此关于数据存储,我们选择Hadoop分布式文件系统HDFS。如下图所示,HDFS也是按照Master和Slave结构,主要分成NameNode、SecondaryNameode和DataNode这几个角色。其中,NameNode是整个文件系统的Master节点,主要功能有:进行数据块的管理映射、处理client端的读写请求、完成副本策略的配置、进行HDFS名称空间的管理;SecondaryNameode是NameNode的备份节点,负责合并fsimage和fsedits,然后再发给NameNode;DataNode是Slave节点,主要功能是负责存储client发来的block,并且完成block的read和write操作。
剩余内容已隐藏,请支付后下载全文,论文总字数:24324字
相关图片展示: