论文总字数:28968字
目 录
1 引言 1
1.1 课题的研究背景与意义 1
1.2 研究现状 1
1.3 本文研究内容 2
1.4 本文组织结构 3
2 深度学习与卷积神经网络 3
2.1 深度学习 3
2.2 CNNs(Convolutional Neural Networks) 4
2.2.1 基本原理 4
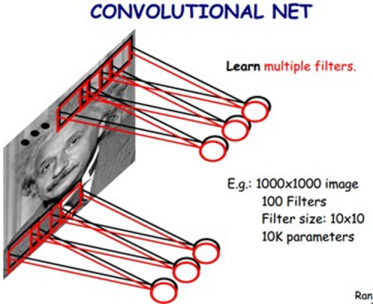
2.2.2 卷积 5
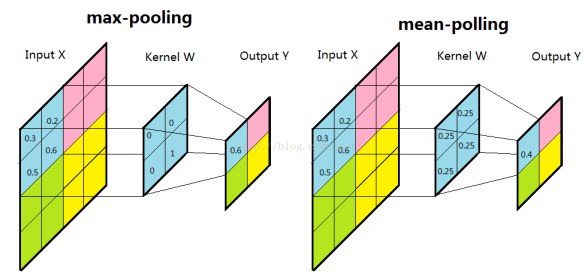
2.2.3 池化(pooling) 6
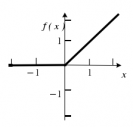
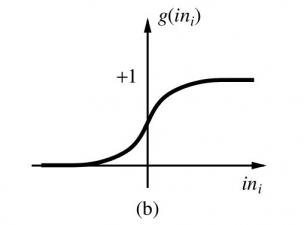
2.2.4 ReLU (Rectifier Linear Units ) 7
3 基于卷积神经网络的微笑检测 8
3.1 使用的数据集 8
3.2 人脸检测与提取 8
3.3 网络模型构建 10
3.3.1 损失函数 10
3.3.2 优化函数 10
3.3.3 Dropout 14
3.3.4 模型改善 15
3.4 数据集扩充及测试 18
3.5 本章小结 18
4 基于三维卷积网络的微表情AU检测 19
4.1 使用的数据集 19
4.2 特征提取与记录 19
4.3 分类与对比 21
4.3.1 特征归一化 23
4.3.2选择核函数和参数 23
4.4 数据集扩充及测试 24
4.5 本章小结 24
5 总结与展望 25
5.1 工作总结 25
5.2 未来展望 26
参考文献 26
致谢 29
附录 30
基于深度学习的微笑及微表情检测
葛宝尧
, China
Abstract:Facial expression plays a key role in analyzing human emotions and behaviors. Smile detection is a special task in facial expression analysis. Its application is embodied in medical monitoring, photo selection, user experience analysis and so on. Micro expression recognition is a more challenging research field and a promising technology. In this paper, based on the principle of deep learning and the convolution neural network as the main theoretical foundation, we have realized the detection of smile and micro expression. By training a large number of data sets, comparing different operating methods and network structures, and testing the expanded data set, a smile detection model with faster recognition speed is constructed, and the accuracy rate is up to 90%. Micro expression detection uses the C3D network to extract the features of the micro expression AU, and makes it possible to extract the features of the micro expression. Using SVM to classify, after network tuning and testing, the accuracy of the four-classifications in the expanded data set reaches over 48%. Experimental results show that convolution neural network model can be applied to image and video classification effectively.
Key words:Deep Learning、CNNs、AU、C3D、SVM
引言
课题的研究背景与意义
在日常生活中可以通过多种方式来获取信息,例如文字、图片、音乐、视频等。而在人际交流中情感表现则成为信息获取中不可或缺的一部分,人脸的表情是其中最重要的体现。心理学家Mehrabian的研究[1]表明,在人与人的沟通中语言所传达的有用信息仅占到 7%,声调的有用信息占到了38%,而55%的有用信息则是通过面部表情来传达的。
表情识别是人脸识别中的一个重要研究课题,其涉及到人类行为心理学、生物社会学、计算机视觉、人工智能等多个领域。在心理学的应用中,表情分析能够成为医院诊断病情的重要手段。通常的心理诊疗主要依赖于语言,而通过人工面部表情分析,可以更深层次地了解患者的精神状态,提供多角度的参考依据,从而提高诊断的准确率。微笑是最常见的面部表情之一,它传达着快乐、幸福和满足的情感状态,例如在对具有潜在孤独性障碍的婴幼儿的社会性逗笑反馈实验中,微笑检测成为一项鉴别儿童是否患有自闭症的重要指标。在日常生活中,微笑检测还可以用于照片筛选,用户体验分析,创新游戏设计等,具有很高的实际应用价值。
微表情识别是更具挑战性的研究领域,因为相比人们有意识做出的表情,微表情的持续时间很短,一般只有0.25到0.5秒,而且大多数情况下是为了掩饰自己内心的真实想法而无意中表现出的一种不受控制的面部表情,通常本人和观察者都容易忽略。正因为如此,微表情才更能透漏出人们的真情实感。在很多欧美国家,关于微表情的研究已经成功地应用到了国家安防、政治选举和司法系统等领域。例如在罪犯审查中,配合微表情解读,能够捕捉其情感细节,获取更多有价值的信息来判断嫌疑人是否在撒谎。微表情识别是个前景非常广阔的新兴技术,将来必定会应用在更多领域,在人们的日常生活中起到更大的作用。
研究现状
随着人工智能科技的发展,人脸表情识别技术作为一门新型的学科己经受到了国内外众多机器学习人员的关注。人脸表情的机器学习包括训练与测试,一般使用国际通用的人脸表情数据库。到目前为止,常用的人脸表情图片数据库有: CK(Cohn-Kanade)数据库[2]、GENKI-4K数据集[3]、JAFFE (The Japanese Female Facial Expression)数据库[4]、CK (The Extended Cohn-Kanade Dataset)数据库[5]、FABO (Bimodal Face and Body Gesture Database)[6]、The Yale Face Database[7]等。
对于图片分类问题,Caifeng Shan[8]等曾提出了一种有效的方法,利用面部灰度图像中像素的强度差作为简单的特征,然后采用AdaBoost算法选择并结合基于像素差异的弱分类器,形成一个用于微笑检测的强分类器。L. An、S. Yang和B. Bhanu[9]等人利用局部二进制模式(LBP)[10],局部相量化(LPQ)[11]和面向梯度的直方图(HOG)[12]作为三种有效的代表面部特征的信息。M. Liu[13]等人用HOG代表人脸图像并用SVM[14]对标签进行分类。V. Jain[15]等人则采用了结合支持向量机的多尺度高斯导数(MGD)。
随着计算机视觉的发展,IBM Watson、谷歌的自动驾驶汽车和亚马逊无人机配送系统等许多智能产品都得到了发展。深度学习,特别是卷积神经网络,对这一成功做出了很大的贡献。卷积神经网络被认为是针对图像分类问题最有效的模型之一。从AlexNet[16], ZFNet[17],到非常深的CNNs,如VGG[18],谷歌Inception[19], ResNet[20]等,已经提出了各式各样的卷积神经网络模型。拥有8个参数层的AlexNet曾在ImageNet大规模视觉识别挑战ILSVRC中将图像分类的错误率降低到15.3%,而有19个参数层的VGGNet的分类错误率只有7.3%,现今最大、最深的ResNet有超过150个参数层,分类错误率仅为惊人的3.57%,这已经称得上是在图像识别领域上超过人类分辨能力的的突破性进展。最近的一些研究也开始将卷积神经网络应用到微笑检测。Chen[21]等人提出一种利用深度卷积神经网络从人脸图像中提取出高阶特征,之后利用SVM和AdaBoost分类器来处理分类任务的微笑检测方法。Zhang[22]等人提出了两种卷积网络结构来进行微笑检测。
微表情仍是一个新兴研究领域,不可避免地会遇到缺少相应的规范标准的问题,且对于数据库的创建仍然处于实践阶段。2011年傅小兰团队建立了微表情数据库CASME[23],提出了使用Gabor滤波器来提取特征,并使用Gentle SVM作为分类器,来实现微表情识别。2013年,在CASME数据库的基础上进行了升级,创建了CASMEⅡ数据库[24]。
对于视频解析问题,一般的思路都是提取局部特征,然后把每一帧的局部特征组合成一个一定维度的向量,之后用分类器进行分类。受深度学习在图像识别领域巨大突破的启发,近几年特征学习取得了飞快的进展,各种预先训练好的卷积网络模型被用于提取图像特征。这些特征通常是网络经过激活后几个完全连接层的输出,但这种基于深度特征的图像并不能很好地适用于视频因为将视频序列按帧切分,并直接对每一帧图像来提取特征,会忽略连续帧间的运动信息。为了有效的综合运动信息,提出了三维卷积的方法。利用3D卷积神经网络,能够捕捉到时间和空间维度都具有区分性的特征,弥补了二维卷积神经网络的不足。
本文研究内容
剩余内容已隐藏,请支付后下载全文,论文总字数:28968字
相关图片展示: