论文总字数:34490字
摘 要
近些年来,随着移动通信技术和计算机科学技术的高速发展,数据量也正以一种突飞猛进的速度在增长。面对如此海量的数据,仅仅依靠人力处理已经太不现实,因此迫切需要一种高效的处理数据的方法。利用机器来模拟人类的学习过程进而对数据进行分析处理无疑是一种高效的解决办法,从而机器学习应运而生。而Naïve Bayes分类是机器学习中的一种简单易行并且实用性强的分类方法,在生产与生活实践当中,具有很深刻的研究意义。
本文对Naïve Bayes分类算法进行研究。首先,在绪论中,本文介绍了机器学习产生的大背景并引出Naive Bayes分类算法。然后,在第二章,本文先简要介绍了Naive Bayes分类的算法思想,然后给出了朴素贝叶斯分类器的Matlab实现以及一些重要的实现细节。第三章是本文的核心部分,主要是对实验部分的介绍,先介绍了实验所需的数据集,然后在不同的数据集上对朴素贝叶斯分类器进行了训练与测试,之后,还进行了Naïve Bayes算法与决策树算法对比实验并对两者在预测精度方面的差异进行了比较分析。最后,是本文的致谢部分。
关键词:朴素贝叶斯,决策树,机器学习,数据挖掘
Research on the Naïve Bayes Classification Algorithm
Abstract
In recent years, with the rapid development of mobile communication technology and computer science technology, the amount of data also grows in a very high speed. Faced with such vast amount of data, just relying on the processing of human is too unrealistic, so we urgently need a highly efficient method to process data. There is no doubt that it is really a highly efficient solution to use machine to simulate the learning process of human and use this way to analyze the vast data. As one of the simplest and practical classification methods in machine learning, it is interesting to analyze the properties of Naïve Bayes in solving real-world learning problems.
This paper is based on the Naïve Bayes Classification and it has four chapters totally. In the first chapter, it makes a concise account of the background of the machine learning and then leads to the Naïve Bayes Classification Algorithm. In the second chapter, it explains the theory of the Naïve Bayes Classification Algorithm and introduces some important details of the implementation of the Naïve Bayes Classification in this paper. The third chapter is the kernel of this paper, it mainly introduces the part of the experiment. In this chapter, a Matlab implementation of Naïve Bayes classifier is implemented, whose performance is evaluated on 12 different data sets. In addition, comparative studies against the Decision Tree algorithm are conducted to analyze the predictive performance of the two algorithms. In the end, the thank part of this paper is represented.
Keyword: Naïve Bayes, Decision Tree, Machine Learning, Data Mining
目录
 I
I
摘要 I
Abstract II
第一章:绪论 1
1.1 研究背景 1
1.2 研究意义 1
第二章:Naïve Bayes分类 3
2.1 Naïve Bayes分类算法 3
2.1.1 贝叶斯分类算法 3
2.1.2 Naïve Bayes分类器 4
2.2 本文的实现 6
2.2.1朴素贝叶斯分类器主要数据结构 6
2.2.2朴素贝叶斯分类器程序主要文件 9
2.2.3 对于不同数据的处理方法 11
2.2.4 获取应用于WEKA J48决策树算法的训练集和测试集的数据 14
第三章:实验 16
3.1 数据集的介绍 16
3.1.1 属性值离散并且数据完整的数据集 16
3.1.2 属性值连续并且数据完整的数据集 20
3.1.3 数据不完整的数据集 21
3.2实验过程 23
3.2.1 朴素贝叶斯分类器实验 23
3.2.2 决策树对比实验 25
第四章:结语 32
参考文献(Reference) 33
第一章:绪论
本章主要介绍Naïve Bayes 算法的研究背景以及其研究意义。
1.1 研究背景
21世纪是一个信息爆炸的时代,各种各样的信息、数据几乎已经完全渗透到了我们的生活之中,每个人甚至每种事物每一天都会产生大量的数据,可想而知,面对如此庞大的人口基数与没有休止的时间范畴,产生的数据的量的是我们无法想象的。
在大数据时代这本书中提到大数据将逐渐成为现代社会基础设施的一部分,就像公路、铁路、港口、水电和通信网络一样不可或缺。但是就其价值特性而言,大数据却和这些物理化的基础设施不同,不会因为人们的使用而折旧和贬值[1]。由于数据的这个特征,所以对于这些数据的分析是具有永久的利用价值的。但是面对如此海量的数据,仅仅依靠人类脑力的计算已经完全不能满足社会进步的需求,因此人类需要一种更加高效的分析数据的方法,自然而然的我们想到了利用机器代替人脑进行智能化的数据分析,从而机器学习被提上了人类现代化进步的日程当中。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能[2]。
分类问题是机器学习中的基础内容,同时也是最重要的内容之一。其实,在我们的日常生活当中,我们每天都在解决各种各样的分类问题。比如,我们走在大街上,观察来来往往的行人,根据他们的穿着打扮,他们的言行举止,潜意识中可能就会判断他的职业,身份等;买东西的时候,根据商品的包装,价格,或者用户体验等特征我们会判断这个商品的质量是好还是坏,进而还会判断我们是买还是不买;这些都是我们生活中常见的分类问题,也是每天都会发生在我们生活中的小小插曲,所以对于分类问题的研究是具有很深刻的现实意义的。在一个分类问题中,输入数据通常被称为“训练数据”,每组训练数据有一个明确的标识或结果,在建立预测模型的时候,分类器会建立一个学习过程,利用从训练数据那里学习到的分类规则不断地对预测模型进行调整,最后利用该模型对未知的实例进行分类。实际上,就是根据其学习经验对新的实例进行分类,这里的学习经验很明显是从训练数据中的获得的。那么如何构建有效并且准确的分类器呢?因此又转到了对高效的分类方法的研究,贝叶斯分类具有坚实的数学基础并能综合先验信息,成为当前数据分类的热点之一。Naïve Bayes分类是贝叶斯分类的中基于特定假设下的一种实用并且简单的分类方法。
1.2 研究意义
Naïve Bayes分类是贝叶斯分类算法中的一种简单易行并且实用性特别强的方法,它是基于给定目标值(即相应分类)时各个属性值之间相互独立这一假设的一种贝叶斯分类方法,不仅大大简化了计算各个假设出现概率时所需要的计算量,而且经大量实验证明,该方法对于最终的分类结果的准确性不会产生太大的影响。特别地,各类条件特征之间的解耦意味着每个特征的分布都可以独立的被当作一维分布来估计。这样减轻了由于高维数带来的阻碍,当样本的特征个数增加时就不需要使样本规模呈指数增长,所以Naïve Bayes的分类算法的研究对于海量数据的智能分析以及人工智能技术的发展都具有积极可靠的现实意义。
第二章:Naïve Bayes分类
2.1 Naïve Bayes分类算法
Naïve Bayes分类算法是贝叶斯分类算法中最常用的一种,是一种简单而又非常有效的分类方法。它以经典的数学中的贝叶斯理论为基础,基于假设的先验概率,给定假设下观察到不同数据的概率以及观察到的数据本身,然后来计算显式的假设概率,是一种基于概率的学习方法。
本章先简要介绍一下Naïve Bayes分类算法的基础:贝叶斯分类算法,然后再具体介绍Naïve Bayes分类算法基本思想,最后再介绍本文实现的Naïve Bayes 分类器的一些重要的数据结构以及一些重要的实现细节。
2.1.1 贝叶斯分类算法
贝叶斯分类算法的基础是贝叶斯定理,贝叶斯公式是:
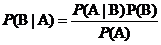
其中A和B分别表示两个事件,并且A发生的概率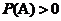 ,
,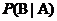 表示在事件A发生的条件下事件B发生的概率,也称为事件B在给定事件A发生的条件下的条件概率。由公式可以看出:事件B在事件A发生的条件下的概率,与事件A在事件B发生的条件下的概率是有一定的数学关系的,所以说贝叶斯定理提供了一种基于假设的先验概率来计算假设的后验概率的可行方法。
表示在事件A发生的条件下事件B发生的概率,也称为事件B在给定事件A发生的条件下的条件概率。由公式可以看出:事件B在事件A发生的条件下的概率,与事件A在事件B发生的条件下的概率是有一定的数学关系的,所以说贝叶斯定理提供了一种基于假设的先验概率来计算假设的后验概率的可行方法。
为了更好的说明贝叶斯分类算法,首先说明一些符号。用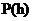 代表还没有训练样本数据前,假设h拥有的初始概率,也就称为h的先验概率,它反映了我们所拥有的关于h是一个正确假设的机会的背景知识。类似的,
代表还没有训练样本数据前,假设h拥有的初始概率,也就称为h的先验概率,它反映了我们所拥有的关于h是一个正确假设的机会的背景知识。类似的,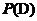 代表将要观察的训练样本数据D的先验概率,也可以说是,在没有确定某一个假设成立时D的概率。接下来是
代表将要观察的训练样本数据D的先验概率,也可以说是,在没有确定某一个假设成立时D的概率。接下来是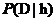 ,它表示假设h成立时观察到数据D的概率。在机器学习中,很明显,我们感兴趣的是
,它表示假设h成立时观察到数据D的概率。在机器学习中,很明显,我们感兴趣的是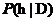 ,也就是给定了一个训练样本数据D,判断假设h成立的概率,这也称为后验概率,它反映了在看到训练样本数据D后假设h成立的置信度[3]。
,也就是给定了一个训练样本数据D,判断假设h成立的概率,这也称为后验概率,它反映了在看到训练样本数据D后假设h成立的置信度[3]。
由贝叶斯公式,我们可以计算出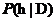 :
:
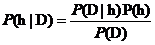
要判断给定数据D之下对应的分类,需要考虑候选假设集合H,并在其中寻找当给定训练数据D时的可能性最大假设h,称为极大后验假设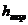 ,此时该假设h就是给定数据D时所对应的分类。
,此时该假设h就是给定数据D时所对应的分类。
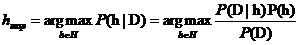
因为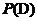 是不依赖于h的常量,所以该式子可以等价变换为:
是不依赖于h的常量,所以该式子可以等价变换为:
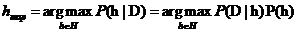
2.1.2 Naïve Bayes分类器
Naïve Bayes 分类是贝叶斯分类中的一种简单有效的方法,它是基于实例中各个属性值之间是相互独立这一条件独立假设的分类方法。尽管实际上条件独立假设常常是不准确的,但实践证明,该分类器的分类效果往往是令人惊奇的,其性能通常可以与决策树、神经网络相聘美。
朴素贝叶斯的条件独立性假设如图2-1表示,其中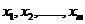 表示m个属性节点,y表示目标类节点。此时y由决定并且是相互独立的。
表示m个属性节点,y表示目标类节点。此时y由决定并且是相互独立的。
y
剩余内容已隐藏,请支付后下载全文,论文总字数:34490字
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

