论文总字数:15008字
目 录
一 绪论…………………………………………………………………5
1.1 选题背景………………………………………………………………………………5
1.2 本文的研究目标和内容………………………………………………………………5
二 相关技术和理论……………………………………………………7
2.1 web数据挖掘…………………………………………………………………………7
2.1.1 web数据挖掘内容………………………………………………………………7
2.1.2 WEB数据挖掘分类………………………………………………………………7
2.1.3 WEB数据挖掘面临的问题………………………………………………………8
2.2 XML……………………………………………………………………………………10
2.2.1 XML定义……………………………………………………………………………10
2.2.2 XML特点……………………………………………………………………………10
2.2.3 XML比起HTML的优点………………………………………………………………11
2.2.4 XML在WEB挖掘领域的应用………………………………………………………11
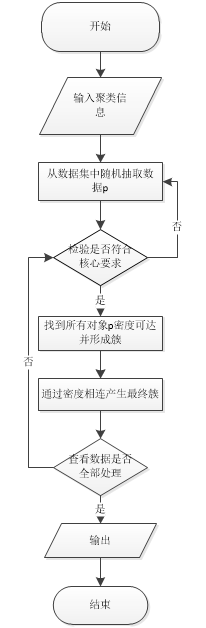
三 基于DBScan算法的网页聚类……………………………………13
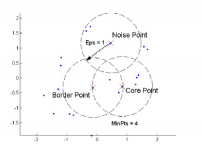
3.1 DBScan算法概念………………………………………………………………………13
3.2 DBScan算法运算过程…………………………………………………………………14
3.3 DBScan算法优势………………………………………………………………………16
3.4 DBScan算法用于网页聚类……………………………………………………………16
四 实验和分析…………………………………………………………17
4.1 实验数据的提取………………………………………………………………………17
4.2 WEB页面转化…………………………………………………………………………18
4.3 评价指标………………………………………………………………………………19
4.1 实验结果与分析………………………………………………………………………19
五 总结…………………………………………………………………24
参考文献………………………………………………………………25
致谢……………………………………………………………………26
基于DBScan算法的网页聚类分析
沈逸帆
,China
Abstract:This paper introduces the basic knowledge of data mining, Web data mining and XML, expounds the application of XML technology to Web data mining, and constructs the Web data mining system structure based on XML. Based on the data mining in WEB, referred to the DBScan algorithm, and DBScan algorithm is used to introduce web page clustering, put forward a system structure based on DBScan technology, and try to apply this operation to a large number of web pages clustering analysis. And test the accuracy of the actual application of the algorithm.
Key words:WEB DATA MINING;DBScan algorithm;DATA MINING;Web Clustering;
一.绪论
1.1选题背景
这些年来,随着计算机网络的普及,因特网也成为了世界上最大的信息网,它含有着无法计算数量的数据量。但是随着WEB的急速发展,WEB有着信息巨大但匮乏有用知识的弊病。目前WEB上的信息,已经我们无法用我们能使用的方法来进行计算了,而且它的数量每年还在不断地增加,所以如何从中找出我们需要的信息,以及如何发现这些信息之后我们看不见的具有价值的知识,对于目前我们来说还是无法完成的。信息检索有着很多搜索引擎,比如说谷歌和百度,它们比较部分地解决了我们需要发现资源的问题,但是这些搜索引擎只能通过关键词和超级链接来解决我们的需要,但是这对于现代的我们来说已经远远不够我们的需求了。
数据挖掘,即DATA Mining DM,是最近随着人工智能以及数据库技术的不断成长而诞生出的一种全新的信息技术。在W.J.Frawley和G.P.Shapiro等人的定义下,我们使用者可以从大量不完全随机的数据中,提炼出隐藏在我们人类并不知道但却有着潜在有用知识的过程就是数据挖掘。数据挖掘由分类、聚类、特征以及偏差、关联规律的挖掘和趋势分析等种类所包含。
我们使用数据挖掘能达到不少目的,而其中的主要是为了提高市场决策能力以及检测异常的模式,从而能在过期的经验基础上预言未来发展趋势。Web上的数据量随着目前互联网的急速发展,也是急速地膨胀,所以对于我们来说,把数据挖掘技术以及目前火热的Web联系到一起的WEB数据挖掘便是一门热门技术。
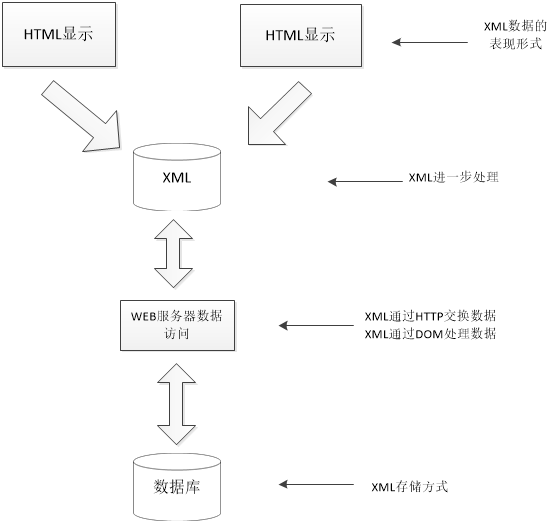
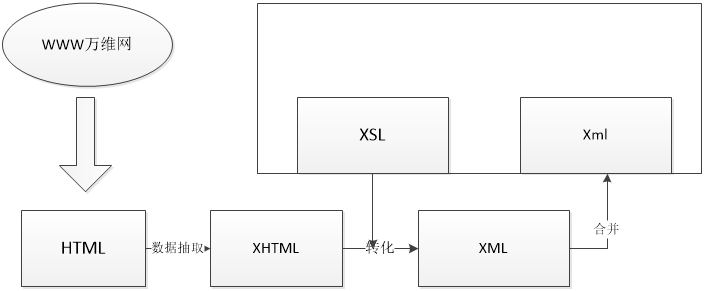
比起web数据挖掘来说,传统的数据库里的数据有着强结构性,而Web上的数据则具有半结构化的性质。所以目前的数据库技术的一项研究大热门就是如何对WEB上的海量数据信息进行复杂应用。而以XML技术作为基础的新一代的WWW环境就直接接触WEB数据,它不但可以兼容目前的WEB应用,并且能更好实现WEB中信息共享与交流,是未来的主流趋向,所以对于我们来说,研究基于XML的WEB数据挖掘技术对于当今我们来说就有十分重大的意义。
1.2本文的研究目标和内容
我们可以把网页分为一类,或者分为多个类别,比如说我们可以把“新闻”分为“体育新闻”和“娱乐新闻”或者“财经新闻”等,所以我们为了理解机器学习的算法是如何对网页进行分类的,就必须首先看人是如何对事物进行分类的,比如说为了辨别某食品是不是健康的,就可以参考这个食品的特征,比如说饱和脂肪、胆固醇、糖钠的含量等。如果这些值有过高的便会被识做是“不健康食品”,而反之其中都是符合健康的要求的话,便是“健康食品”。网页的分类也是如此,我们首先要对网页的整个项目集合中找出重要的特征,然后从每个待分类的项目中寻找特征,而从抽取中的特征中组合证据,最后根据组合证据,并按着某种决策的机制来分类项目。对网页进行分类,则是利用网页中的文本、URL或者网页输入链接的锚点文字等信息对其分类。但是如果并没有确定的目标类别,我们就需要与网页分类不同的技术,这技术叫网页聚类。分类算法需要训练数据,就是需要把数据分好类,而聚类则是并没有监督的学习,我们需要在没有标记的数据中对其进行处理,并寻找相近的结构。而我们便是需要做到,将相类似的东西组织到一起,而被组织到一起的东西,被成为“簇”,而我们在本文,便是需要利用算法并结合新兴的XML技术对特定的网页组进行聚类统计。
二 相关技术和理论
2.1 WEB数据挖掘
Web数据挖掘是数据挖掘技术在WEB信息应用的一个全新的范畴,它由传统数据挖掘发展而来。
2.1.1 WEB数据挖掘
WEB的数据和传统数据库的数据有着明显的区别,主要是传统数据库都拥有必然的模型,使用数据模型,我们可以对具体数据进行描述,但是WEB的数据就与其不一样,它并没有着同一的模型,每个站点都被分开独立设计;而且,站点中的数据都在不断地变化,所以传统数据挖掘技术就并不能适用在WEB挖掘上。但由于WEB有自己的构造,所以总体来说,站点结构互相差异都并不是特别大,所以我们把WEB数据当作一种半结构化数据,以上便是WEB数据的另一个重要特点。
WEB数据挖掘有以下几个内容:服务器日志数据(Logs);在线业务数据;WEB页面中的文本;WEB上的多媒体数据;WEB页面超级链接关系(URLS);用户注册其他信息等。而比起WEB数据,传统的数据库拥有很强的数据结构性,但WEB的数据的最大特性就是半结构化,所以对半结构化数据的研究便是一个全新领域。跟着网络的不断成长,WEB的数据的半结构化的特点也是越来越得明显,所以这个问题也跟着扩展到了WEB范畴,所以最后提出了特定于WEB数据模型的问题。
在这最开始,我们便必须解决半结构化数据模型的查找以及集成问题。所以我们为了解决WEB上的异构数据的查找以及集成问题,便需要我们有一个能清晰地描述WEB的数据的模型。而以上问题的关键点,就要我们针对WEB上数据的半结构化的特性,寻找一个有半结构化特性的数据模型来表达它。而且我们还要拥有一种能自动从现有数据中将这个模型抽取出来的模型抽取技术,以及把半结构化数据模型以及半结构化数据模型抽取技术作为面向WEB数据挖掘的前提。
2.1.2 WEB数据挖掘的分类
1.WEB数据由以下三类组成:HTML标记的WEB文档数据、WEB文档内的结构数据和用户访问日志数据,而WEB数据挖掘也能被分为三个种类:内容挖掘(WEB CONTENTMINING)、结构挖掘(WEB STRUCTURE MINING)和用户使用挖掘(WEB USAGE MINING)。如:图1
(1). Web内容挖掘是从文档的内容或其描述中提取我们需要的知识的过程,其以Web内容为基础,自动导航在线信息,并且可以提取内容。 其对象可以是文本或非文本数据,它可以是图形,图像等多媒体数据; 不仅从结构化数据的数据库,以及使用HTML标签或半结构化数据和自由文本的XML标记Web内容挖掘不仅可以帮助用户搜索信息,还可以根据用户 搜索条件删除无用的信息。
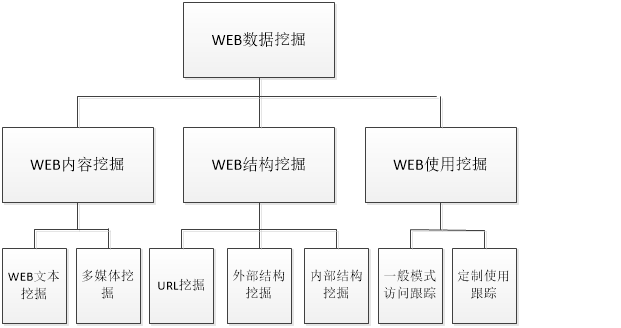
图(1)WEB数据挖掘分类
(2). WEB结构挖掘是从WEB组织结构,WEB文档结构和链接关系导出知识的过程。 WEB内容挖掘主要使用内部文档,但WEB结构的外部结构主要是超链接使用超链接结构。 挖掘页面结构和WEB结构可用于指导页面排序和集群,并找到权威页面,以提高搜索性能,指导页面收集和提高收集效率。 WEB结构挖掘的目标是探索页面和用户访问模式和习惯之间有趣的链接,轻松更好地布局和使用页面。 结构挖掘WEB允许我们得到很多信息。 一般来说,假设一些页面具有特定的关系,那么这些页面可能具有相同的结构或类似的内容。 XML可以帮助我们轻松找到上述页面的相同和区别。
(3). Web使用挖掘是从用户登录的日志中提取我们需要的知识或从服务器记录的浏览信息的一种方式。当我们浏览互联网时,WEB将能够获取一些数据,并利用WEB挖掘这些数据挖掘所需的信息来预测用户的在线行为,在三种WEB数据挖掘中,最受关注的是WEB服务提供商通过使用WEB挖掘将能够根据实际用户浏览实际情况调整站点的网页链接布局和内容,从而使用户得到更好的服务;还在PROXY访问信息中分析用户导向模型,预测用户页面方向,从而提高WEB缓存的性能。 WEB服务提供商将能够分析这些数据,帮助用户了解隐藏在数据中的行为模式,进行预测分析,改进网站结构或为用户提供个性化服务。而目前的个性化网站正在上升,服务提供商可以利用WEB轻松挖掘用户的喜好,动态定制用户观看内容或提供建议,使网站更适合内容的用户使用。
2.1.3.WEB数据挖掘面临的问题
但是由于WEB上的数据结构最为结构化,所以与数据仓库相比,面向WEB的数据挖掘越来越复杂,我们需要解决的几个问题:①导航问题: 通过网站(3)数据提取问题:确保数据准确; ⑤数据整合问题:分离HTML; (2)数据提取问题:从这些页面提取数据; ③结构综合问题:④提取数据,提高结构; ⑤页面合并数据。 而要解决上述问题,首先要解决以下基本问题:
剩余内容已隐藏,请支付后下载全文,论文总字数:15008字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

