论文总字数:14562字
目 录
1 绪论 1
1.1离群数据挖掘技术 1
1.2 研究背景及意义 1
1.3 国内外研究现状 1
1.4 本文的结构安排 1
2信息熵定义 2
3 SLOM算法的简介 3
3.1 相关定义 3
3.2 SLOM算法的分析 5
4 LDOF算法的简介 5
4.1 相关定义 5
4.2 LDOF算法的分析 6
5信息熵加权算法 6
5.1 信息熵加权定义 6
5.2信息熵加权算法 7
5 .3信息熵加权算法的优势 8
6实验分析 8
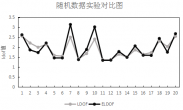
6.1 随机数据实验 8
6.1.1 随机生成的20个数据 8
6.1.2 实验具体步骤 9
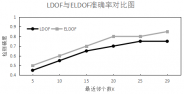
6.1.3 实验结果分析 10
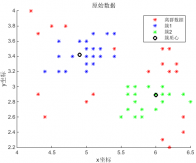
6.2 两个簇数据实验 11
6.2.2 FCM算法简介 12
6.2.3 实验具体步骤 12
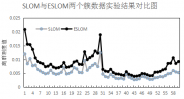
6.2.4 实验结果分析 14
6.3 实验总结 17
7 结论 17
参考文献 19
基于信息熵加权的离群点检测研究
冯超
ABSTRACT:Outlier detection is one of the important research directions of data mining technology. Outlier detection techniques can find those outlier data that are not consistent with the majority data in the whole data.This kind of technology is widely used in intrusion detection. This paper is to study the correlation algorithm of outlier data mining.This article increases the entropy calculation based on SLOM and LDOF algorithm. That is, when calculating the distance use information of entropy theory to calculate the weighted distance, the accuracy of detection of outliers is improved, and therefore require more spending at the expense of some space, the attribute weight vector based on the properties of information entropy calculated is stored in these spaces Finally, experiments are completed to prove our opinion.
Key Word: Outlier;Information entropy;Weighted;SLOM;LDOF
1 绪论
1.1离群数据挖掘技术
离群数据,可定义为与数据群体中大部分数据所不一样的、脱离数据群体特征的数据,离群数据的挖掘就是在一个数据集中把那些远离数据集中心的样本数据给找出来。离群数据挖掘的实现算法目前有很多种,包括本文接下来用来对比实验的SLOM算法、LDOF算法、FCM算法、还有参考文献[12]所提出来的在FCM算法的基础上进行改进的WSRFCM算法等等,可以实现离群数据挖掘的算法确实多种多样,但是每个算法都各有他们自身的优势和劣势,现在所需要做的就是在已知算法的基础上提出改进使得算法对于离群数据挖掘的准确率可以进一步提高。
1.2 研究背景及意义
离群点的检测是数据挖掘技术重要研究方向之一,离群点检测技术可以在众多数据中发现与大多数据不一致的那些离群的数据,在现实生活中该技术被广泛的使用,如网络入侵检测、信用卡恶意透支等,这些离群点检测技术应用的领域都是深入广大人名群众的生活,与普通大众息息相关的。
除此之外,对于大量数据的处理操作,若使用离群点检测技术还可以最大化的利用机械作业,有效地减少人工分析数据工作量以及人工分析的经验成分。
综上所述,离群数据的挖掘算法的研究具有相当重要的现实意义。
1.3 国内外研究现状
目前,不管是我国还是国外,都有很多的学者在研究离群数据的挖掘技术,国内外学者对于离群点检测的算法已经提出了很多种方案,有与聚类相关的FCM算法,有与加权关联规则相关的算法,还有与权重值相关的算法,可以说,随着时间的推移,广大的学者不仅仅是在研究新的算法,也在不停的研究如何使得已经提出的算法得到改进从而获得更好的离群点检测结果。
本文探讨的离群数据挖掘的研究是针对已有的离群点检测算法提出改进意见,从而达到提高原有的离群点检测技术的检测精度的目的,使算法得到有效改善。
1.4 本文的结构安排
第一章:从离群数据挖掘技术的研究背景、生活中的多个方面需要离群数据挖掘技术的支撑和国内外对于离群数据挖掘技术的研究现状这几个方面来阐明数据挖掘技术的重要性,最后我们给出了本文的结构安排。
第二章:介绍信息熵算法以及相关的概念的定义。
第三章:介绍SLOM算法以及相关概念的定义。
第四章:介绍LODF算法以及相关概念的定义。
第五章:介绍信息熵加权的相关概念以及信息熵加权在SLOM和LODF中的具体运用。
第六章:实验比较分析运用信息熵加权的优势。
第七章:文章的小结。
2信息熵定义
设离散信源是一个由M个符号组成的集合,其中每个符号 按一定的概率
按一定的概率 独立出现,且有
独立出现,且有 ,则
,则 所包含的信息量分别为:
所包含的信息量分别为: ,可以通过计算得出每个符号所含信息量的统计平均值,公式如下:
,可以通过计算得出每个符号所含信息量的统计平均值,公式如下:
因为 和热力学中的熵的形式十分的相似,所以通常又称它为信息源的熵,单位为
和热力学中的熵的形式十分的相似,所以通常又称它为信息源的熵,单位为 。由信息熵的定义可以发现,信息熵的取值仅仅取决于对象出现的概率 ,所以该方法为处理有出现概率的非数值对象提供了一个很好的选择。
。由信息熵的定义可以发现,信息熵的取值仅仅取决于对象出现的概率 ,所以该方法为处理有出现概率的非数值对象提供了一个很好的选择。
信息上有以下几个性质,这些性质对下文公式的推导有一定的帮助:
1)非负性:
2)确定性:
3)可加性:信息熵的和等于和的信息熵。
4)极值性:
首先给出条件熵的定义:假设Y是一段时间序列的集合 ,其中
,其中 表示的是每一个审计事件,若X是这个集合Y中的一段子序列
表示的是每一个审计事件,若X是这个集合Y中的一段子序列 ,那么事件X出现之后,事件Y中剩下的审计事件的不确定度则称其为条件熵,记做
,那么事件X出现之后,事件Y中剩下的审计事件的不确定度则称其为条件熵,记做 。
。
下面给出相对条件熵的定义:
设 和
和 是定义在
是定义在 和
和 之上的两个不同的概率分布,那么和之间的相对条件熵可以用公式计算得出:
之上的两个不同的概率分布,那么和之间的相对条件熵可以用公式计算得出: 相对熵越小则说明这两个数据集合的规律性是越相近,相反的如果相对熵为0,那么则意味着两个数据集具有相同的规律性。
相对熵越小则说明这两个数据集合的规律性是越相近,相反的如果相对熵为0,那么则意味着两个数据集具有相同的规律性。
自信息熵 的定义为:某事件
的定义为:某事件 发生所含有的信息量。
发生所含有的信息量。 其中,
其中, 是事件
是事件 发生的概率。
发生的概率。 ,那么对于存在多个属性的记录
,那么对于存在多个属性的记录 来说,信息熵得计算公式如下所示:
来说,信息熵得计算公式如下所示: 如果记录的各个属性之间相互独立,由性质3可知,
如果记录的各个属性之间相互独立,由性质3可知, 
3 SLOM算法的简介
3.1 相关定义
SLOM算法是Chawala等人在2006年的时候提出来的度量离群性的离群点检测方法,参考文献[9]对SOLM算法进行了简介,本文现在根据参考文献[9]先对相关定义做出如下解释:
定义1:定义对象o和他的领域N(o)中对象的距离的最大值为

定义2:邻域距离度量
剩余内容已隐藏,请支付后下载全文,论文总字数:14562字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

