论文总字数:21412字
目 录
1. 引言 1
1.1研究背景 1
1.2国内外研究进展 1
2. 数据来源与预处理 2
2.1数据来源 2
2.2数据预处理 3
3. 特征选取 4
3.1卡方检验 4
3.2似然比卡方检验 6
4. K近邻算法 8
4.1 K近邻算法介绍 8
4.2 K近邻算法实现 9
5. C5.0决策树 10
5.1 C5.0算法的基本原理 10
5.2基于Clementine C5.0决策树的判别预测结果分析 13
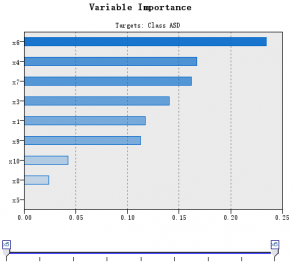
5.2.1重要变量 13
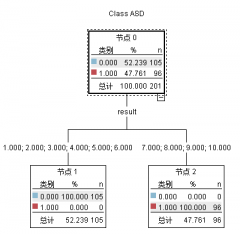
5.2.2决策树 14
5.2.3规则集 15
5.2.4模型评价 16
6. 支持向量分类机(SVC) 17
6.1 SVC的基本原理 17
6.2 基于Clementine SVC的判别预测结果分析 20
6.2.1重要变量 20
6.2.2模型评价 20
7. 总结 21
参考文献: 22
致谢 27
基于自闭症儿童数据集的分类算法研究
梁军君
,China
Abstract:There is increasing number of children with autism (ASD) in China, the easy-to-implement ASD discriminating methods with high efficiency are of great significance, which can help professionals and inform individuals whether they should conduct formal clinical diagnosis. In order to improve the diagnosis process of ASD patients, this article uses data of 292 children with autism as research objects, focusing on three typical classification algorithms of machine learning, which are K-Nearest Neighbor algorithm, C5.0 decision tree algorithm and Support Vector Sorter. 12 important features were selected through Chi-Squared Test and Likelihood Ratio, then use them to establish K-Nearest Neighbor model, C5.0 decision tree and Support Vector Sorter, their prediction accuracy rates are 95.60 %, 90.11% and 98.9%, respectively. According to the result of prediction, the Support Vector Sorter has the best classification prediction effect, followed by the K-Nearest Neighbor algorithm and the C5.0 decision tree algorith.
Key words:Autism; K-Nearest Neighbor ; C5.0 decision tree; Support Vector Sorter
1. 引言
1.1研究背景
自闭症谱系障碍(ASD)是一种大脑神经发育障碍,也称孤独症,伴随着智力障碍、言语障碍、运动协调障碍、情感障碍,同时有多动症、重复行为等症状 。尽管ASD有其遗传根源,但主要通过社交互动,想象能力,重复行为和沟通等行为指标进行诊断。与其他婴儿组相比,ASD儿童在早期发育上遇到了更为严重的困难,影响早期学习以及与他人交往。
。尽管ASD有其遗传根源,但主要通过社交互动,想象能力,重复行为和沟通等行为指标进行诊断。与其他婴儿组相比,ASD儿童在早期发育上遇到了更为严重的困难,影响早期学习以及与他人交往。
绝大多数ASD诊断都依赖手工制定的规则,这些规则使用分数的数学总和公式来提出适当的诊断。因此,除了正确度之外还需要专家或临床医师的评估。更重要的是,大多数现有的ASD诊断工具需要大量的时间才能产生完整的诊断结果,并且程序不符合成本效益。Kim SH 表明,家长参与早期治疗的干预会对长期的学术发展产生层次影响。说明早期诊断可以显着减少这些疾病。随着我国ASD儿童病例数日益增多,因此,时间效率高且易于实施的ASD筛查方法具有重要意义,且能够帮助专业人员并告知个人他们是否应该进行正式的临床诊断。
表明,家长参与早期治疗的干预会对长期的学术发展产生层次影响。说明早期诊断可以显着减少这些疾病。随着我国ASD儿童病例数日益增多,因此,时间效率高且易于实施的ASD筛查方法具有重要意义,且能够帮助专业人员并告知个人他们是否应该进行正式的临床诊断。
分类算法主要分为Lazy和Eager两种类型 。Lazy算法的思想是从局部出发,延迟对训练样本的总结过程,直到测试样本出现,如K近邻算法、局部加权回归算法等。而Eager算法的思想是从全局出发,在测试样本出现之前,由训练样本整合出相似判别的目标函数,这个目标函数应用于训练样本集和测试样本集,例如决策树算法、神经网络算法、支持向量机算法等。为了改善ASD的诊断过程,本文将以Lazy算法中的K近邻和Eager算法的决策树和支持向量机对自闭症儿童数据集进行判别预测。针对每种算法,本文通过分析实验数据得出他们在自闭症儿童数据集上的分类效果。并选出最优方法,以达到提高病例的诊断时间,提供更快速的判别筛查服务,改善诊断准确性。
。Lazy算法的思想是从局部出发,延迟对训练样本的总结过程,直到测试样本出现,如K近邻算法、局部加权回归算法等。而Eager算法的思想是从全局出发,在测试样本出现之前,由训练样本整合出相似判别的目标函数,这个目标函数应用于训练样本集和测试样本集,例如决策树算法、神经网络算法、支持向量机算法等。为了改善ASD的诊断过程,本文将以Lazy算法中的K近邻和Eager算法的决策树和支持向量机对自闭症儿童数据集进行判别预测。针对每种算法,本文通过分析实验数据得出他们在自闭症儿童数据集上的分类效果。并选出最优方法,以达到提高病例的诊断时间,提供更快速的判别筛查服务,改善诊断准确性。
1.2国内外研究进展
目前,国内外已经有相当多的ASD筛查与诊断的方法和多种分类方法,ASD筛查与诊断的方法主要是诊断量表、团队诊断、机器学习等。常用的诊断量表有 :克氏小二自闭症行为诊断(Clancy Autism Behavior),儿童期自闭症评定量表(Chlihood Austism Rating Scale,CARS),日本名古屋大学教育部编制的“名大式自闭症儿童发展评定量表” (NAUS); Mesibov (1988) 编制的青少年和成人心理教育量表(AAPEP)
:克氏小二自闭症行为诊断(Clancy Autism Behavior),儿童期自闭症评定量表(Chlihood Austism Rating Scale,CARS),日本名古屋大学教育部编制的“名大式自闭症儿童发展评定量表” (NAUS); Mesibov (1988) 编制的青少年和成人心理教育量表(AAPEP) ,Wing等1990年编制的交往和交流障碍诊断访谈量表(DISCO)及其多次修订版
,Wing等1990年编制的交往和交流障碍诊断访谈量表(DISCO)及其多次修订版 。
。
决策树分类算法能够较好地处理不均衡数据,但只对规模较小的训练样本集有效;支持向量机分类算法正确率较高,复杂度较低,但在处理大数据时,分类的速度较慢。针对这些问题,文献[8]批判性地分析近期关于自闭症的调查研究,还提出了增强机器学习在ASD研究的概念化,强调实施和数据方面的使用。文献[9]利用贝叶斯和决策树分类算法的优点,提出将决策树算法和贝叶斯算法相结合的混合分类算法,比仅仅使用决策树或贝叶斯算法的分类速度更快,正确率更高。文献[10]提出了一种缩减数据集得以提高训练速度的算法,确保了分类正确率,并有效提高了分类速度;文献[11]提出一种能提高分类正确率、速度以及样本的规模,并能加强SVM泛化能力的BS-SVM算法;文献[12]中提出了基于脑网络社团结构和深度学习的自闭症诊断方法,通过建立NMI统计矩阵将所有被试的脑网络社团结构特征缩小到一个低纬度的矩阵中,从而对自闭症和对照组进行区分,得到更加准确的诊断结果,且时间成本低。对未来数据做出预测是困难的,因此得分的分解是评估预测表现的有用工具,文献[13]提出广义分位数偏差修正得分分解,在一定感兴趣条件下的允许详细预测评估的局部评分分解。
2. 数据来源与预处理
2.1 数据来源
本文以加州大学欧文分校(UCI)提供的292个儿童数据为对象。数据集共有21个特征值,由于其中一个特征值为常量,予以删除,现剩下20个特征值,其中 -
- 是行为特征,剩下的10个为个体特征。数据集中有141个自闭症儿童,151个健康儿童。男孩和女孩人数分别为208和84人,比例为2.476:1,男女患病的百分比分别为45.24%和49.52%。
是行为特征,剩下的10个为个体特征。数据集中有141个自闭症儿童,151个健康儿童。男孩和女孩人数分别为208和84人,比例为2.476:1,男女患病的百分比分别为45.24%和49.52%。
由于本文研究对象为儿童自闭症患者,因此年龄为分类型变量,取值分别为4-11岁(整数);所以这20个特征值全为分类型变量。其中Class ASD为判别变量,剩余的变量为解释变量。由文献[14],可得到各个变量的具体含义,如表1所示。
表1 变量含义
变量名称 | 分类含义 | 含义 |
| {no,yes}={0,1} | 他经常注意到别人听不到的小声音 |
| {no,yes}={0,1} | 他通常把大部分注意力的放在整个画面上,而不是细节上 |
| {no,yes}={0,1} | 他很容易和几个不同的人谈话 |
| {no,yes}={0,1} | 他很容易在不同的活动之间来回走动 |
| {no,yes}={0,1} | 他不知道怎样和同龄人保持对话 |
| {no,yes}={0,1} | 他擅长社交聊天 |
| {no,yes}={0,1} | 读一个故事时,他发现很难理解角色的意图或思想 |
| {no,yes}={0,1} | 在幼儿园时,他喜欢玩与其他孩子假装玩的游戏 |
| {no,yes}={0,1} | 他通过看别人的脸就能轻易知道别人在想什么 |
| {no,yes}={0,1} | 他很难结交新朋友 |
age | 4, 5, 6, 7, 8, 9, 10, 11 | 4-11岁 |
gender | {女,男}={0,1} | 性别 |
ethnicity | 1-10(见附件) | 种族 |
jundice | {no,yes}={0,1} | 是否有黄疸 |
austim | {no,yes}={0,1} | 家人是否患有自闭症 |
contry | 1-52(见附录) | 所属国家(52个国家) |
used app before | {no,yes}={0,1} | 之前是否使用过此App |
result | 1-10 | App的检测结果 |
relation | 1=父母,2=自己,3=亲属,4=医疗保健人员 | 回答者与测试者关系 |
Class ASD | {no,yes}={0,1} | 测试者是否患自闭症 |








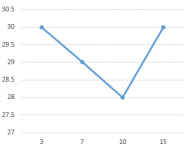
图1是各解释变量与判别变量的条形图,从图中可以直观的看到各解释变量的分类里患病(红色)和不患病(蓝色)人数的大概比例。比如age这个变量,可以清楚的看到众数为4岁,患病与不患病的比例大致相等,可以推断该变量与是否患自闭症无多大关系,后面的特征选取结果也证实了该观点。同样的,还有变量result,我们也可以看出人数被明显的分成两类,可以推测该变量对是否患自闭症有重大联系。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| ||
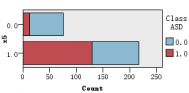
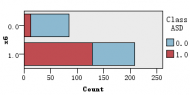
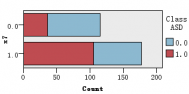
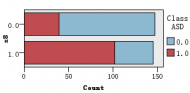
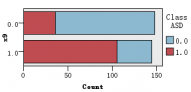
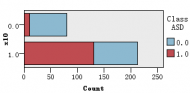
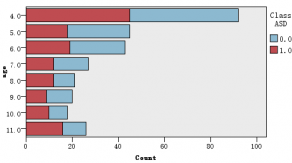
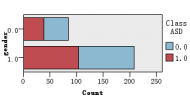
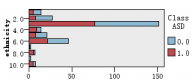
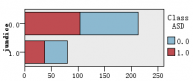
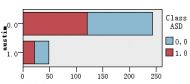
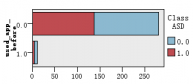
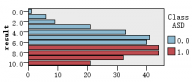
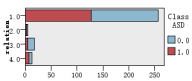
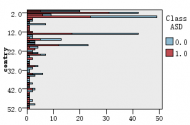
图 1 各解释变量与判别变量的条形图
2.2 数据预处理
数据无异常值,但有90个缺失值,含缺失值的变量有3个,分别为age、relation、ethnicity,因为变量都为离散型,所以采取众数替补法。从上图知,变量age的众数为4岁,变量relation的众数为“1(父母)”, 变量ethnicity的众数为 “3(白种人)”,分别代替他们各自的缺失值。
为了更快的了解本文的结构,可参考图2的流程图。
剩余内容已隐藏,请支付后下载全文,论文总字数:21412字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

