论文总字数:22676字
目 录
摘要: 4
关键词: 4
第一章 绪论 6
1.1 研究工作的背景与意义 6
1.2 国内外研究现状 6
1.3 本文的主要研究内容 8
1.4 本论文的组织结构 9
第二章 总体设计及相关理论研究 10
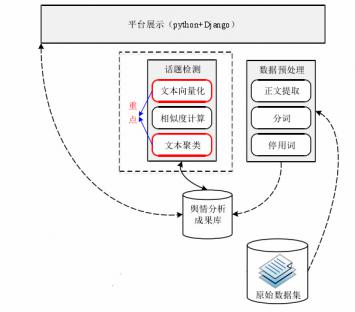
2.1 系统总体设计 10
2.1.1 网络舆情分析系统概述 10
2.1.2 网络舆情跟踪系统的框架组成 11
2.1.3 本系统总体设计 12
2.2 文本预处理技术 13
2.2.1 中文分词 13
2.2.2 停用词去除 14
2.3 文本表示模型 14
2.3.1 向量空间模型(VSM) 15
2.3.2 分布式表达的词向量模型(word2vec) 16
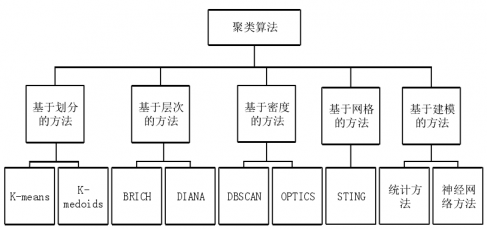
2.4 文本聚类算法 19
2.4.1 聚类算法简介 19
2.4.2 聚类算法的分类 19
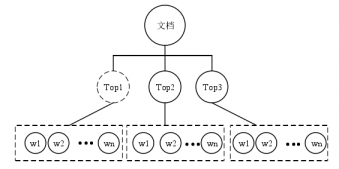
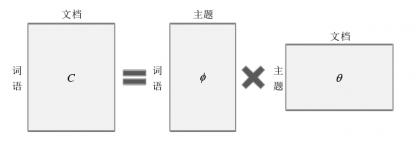
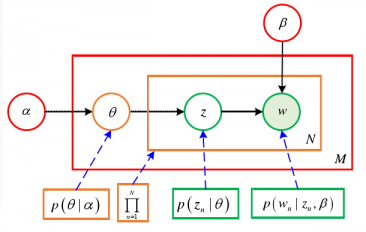
2.5 LDA主题模型 21
2.6 本章小结 23
第三章 系统的实现与测试 24
3.1 数据库设计 24
3.2 功能模块设计 26
3.2.1 文本预处理模块 26
3.2.2 主题检测模块 27
3.2.3 系统管理模块 27
3.3 模块实现 28
3.3.1 系统开发环境 28
3.3.2 用户信息管理模块 29
3.3.3 系统主界面 30
3.3.4 文件处理模块 31
3.4 运行结果 33
3.5 系统测试 35
3.5.1 测试内容 35
3.5.2 测试结果 35
3.6 本章小结 36
第四章 总结与展望 37
4.1 本文总结 37
4.2 未来展望 37
参考文献 38
致谢 39
针对气象灾害的微博舆情跟踪系统
刘永瑞
,China
Abstract:
As China gradually enters the era of Internet , the Internet has become the main form of communication in people's daily life, and the cost of communicating via the Internet is also gradually decreasing. With the gradual development of the network, the influence of network information is gradually expanding. This information is amazing on the breadth and speed of the network. At the same time, the growth rate of this information is equally impressive. How to track valuable hot topics timely and accurately in these massive, rapidly growing, non-directional data is a hot topic in the field of natural language processing. In this study, we selected Weibo, a social software platform with a large number of domestic users, high user activity, and increasing influence, as the research object, and analyzed the Weibo data obtained within a certain period of time using web crawler technology, get hot topics on weather disasters during the period and track them.
The main contents of this study are : text representation model and text clustering algorithm in topic detection. For the speciality of extracting text data from Weibo, this paper uses the LDA topic generation model (Latent Dirichlet Allocation) to process the initial data, obtain the main topics in the grab data, and perform data visualization to provide easy-to-understand public opinion trends.
Key words:Internet public opinion analysis; Text clustering; Topic detection
第一章 绪论
研究工作的背景与意义
自1994年互联网在中国落户之时,我们并未预想到互联网的发展速度能够达到如今的程度。互联网被称为现今新兴的第四媒体,在如今的社会生活中举足轻重。按照中国互联网中心(CNNIC)2018年1月31日公布的第41次《中国互联网络发展状况统计报告》指出:截至2017年12月,我国网民规模达7.72亿,普及率达到55.8%,超过全球平均水平(51.7%)4.1个百分点,超过亚洲平均水平(46.7%)9.1个百分点。2017年全年新增网民4074万人,增长率为5.6%。其中我国手机网民规模达7.53亿,网民中使用手机上网人群的占比由2016年的95.1%提升至97.5%。[1] 中国网民的规模已经达到一个巨大的数字,并且随着我国互联网建设进度的推进,这个数字仍然会稳步上升。由此可知,“网民”已经成为中国社会发展中一个具有巨大影响力的群体。这个群体通过例如微信、微博之类的国内普及程度较高的社交网络平台传达自己的观点态度、情感意愿,是一股不可忽视的言论力量。
而在当下流行的社交媒体平台中,由于用户规模大、活跃用户比例多、影响力高等特点,微博已经成为国内首屈一指的存在。根据新浪微博2017年12月发布的季度财务报告显示:2017年的月活跃用户数(MAUs)较上年同期净增约7900万,达到3.92亿。93%的月活跃用户为移动端用户。到2017年12月,新浪微博的平均日活跃用户数(DAUs)较上年同期净增长约3300万,达到了1.72亿。[2] 数据表明新浪微博已经成为国内重量级的社交媒体平台。每时每刻都有海量的新消息在微博上产生,并在其数量级巨大的用户关系网络中快速广泛传播。如何在海量的数据中挖掘出目前的热点话题并了解热点话题趋势和走向,是自然语言处理领域的一大热门研究点。
由于微博作为社交网络平台本身的局限性不便于对信息进行过滤和区分,如果想要得到精确的主题趋势,需要通过微博舆情分析系统,通过对微博大量文本信息的分析研究,得出当前人们社交生活中的热点话题,帮助政府部门掌握公众舆论趋势,以便于在重大公共事务发生时及时做出响应。
国内外研究现状
在互联网高度发达的今天,网民已经成为公共舆论体系中一个举足轻重的组成部分,舆情的产生方式也随之变动,不再是媒体的专利。作为现代信息传播的主要方式,网络舆情已经成为对社会舆情的主要影响方。因此国内外有越来越多的学者开始研究网络舆情跟踪分析中,并取得了巨大的进展。
在网络舆情预测分析技术的研究领域,国内外学者均获得了一系列成果。其中,国外学者的主要通过评测会议,诸如“话题检测与追踪”、“文本信息检索”、“情报检测专业组”等来推动发展。在此等条件下,国外研究学者获得的主要成果是三种较为成熟的网络舆情分析模型,分别是文本数据自动分析模型、调查问卷模型以及 Web 数据自动分析模型。而国内此方面研究与国外相比起步较晚,在2007年9月刘毅发表了国内第一本关于网络舆情方面的概论书籍,《网络舆情研究概论》。该书结合我国实际国情,将理论与实际相结合,详细的阐述了我国网络舆情现状,并仔细分析了其主要特点、传播途径等,为我国的网络舆情研究开创了先河。国内学者在其后的研究下也获得了一系列成果。下表1-1是我国目前较为知名的一些网络舆情系统。
表1-1 国内知名网络舆情系统
舆情系统名称 | 开发单位 |
利盾网络舆情监控 | 上海昂声信息科技有限公司 |
军犬网络舆情监测系统 | 中科点击(北京)科技有限公司 |
Rank网络舆情监测系统 | 北京飞科达软件有限公司 |
谷尼微舆情监测系统 | 谷尼国际软件(北京)有限公司 |
本果网络舆情监控系统 | 北京本果信息技术有限公司 |
邦富互联网舆情监控系统 | 广州市邦富软件有限公司 |
鹰隼网络舆情监控 | 北京本果信息技术有限公司 |
在网络舆情分析跟踪技术中,话题检测与跟踪 (Topic Detection and Tracking, 简写为TDT)是一个重要的研究方向,起源于早期面向事件的检测与跟踪(Event Detection and Tracking,简写为EDT)。这项技术的目的是帮助人们处理日益严重的互联网信息规模爆炸问题,对新闻媒体信息流进行新出现话题的自动识别和已知的话题的持续跟踪。话题检测(Topic Detection)是其中非常关键的一个环节,其主要分为两个步骤:第一步,将非结构化的文本数据切割成结构化数值向量,以便于计算机机器学习算法的识别与操作;第二步,根据文本数据的特性选择合适的聚类算法,将某一话题相关的文档归于同一类别。
在文本数据处理过程中,向量空间模型(Vector Space Model, 简写为VSM)是较为普遍使用的一种处理方式。VSM将文本数据转化成空间向量,其每一维度的分量取值对应着特征词的权重。另外潜在狄利克雷分配 (Latent Dirichlet Allocation, LDA)主题模型也是一个热门的研究方向。LDA主题模型降低了向量维度,有优秀的话题分类能力,在各种自然语言处理领域被广泛使用。
剩余内容已隐藏,请支付后下载全文,论文总字数:22676字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

