论文总字数:22112字
目 录
1.绪论 1
1.1研究意义 1
1.2国内外研究现状 1
1.2.1 网络爬虫的研究现状 1
1.2.2 情感分析研究现状 1
1.3论文结构 2
2.爬虫相关概念和技术介绍 3
2.1 网络爬虫程序 3
2.2 Scrapy爬虫框架 3
2.2.1Scrapy组件 3
2.2.1 Scrapy运行流程 4
2.3 数据库简介 5
2.3.1 Redis的特性 5
2.3.2 mysql数据库 6
2.4 反反爬策略介绍 6
3.情感分析相关概念和技术介绍 8
3.1 文本预处理技术 8
3.1.1 中文分词 8
3.1.2 停用词去除 8
3.1.3 词性标注 9
3.2 基于机器学习的情感分析 9
3.2.1 基于朴素贝叶斯的情感分析 9
3.2.2 snowNLP简介 11
4.系统设计与实现 12
4.1爬虫程序整体结构设计 12
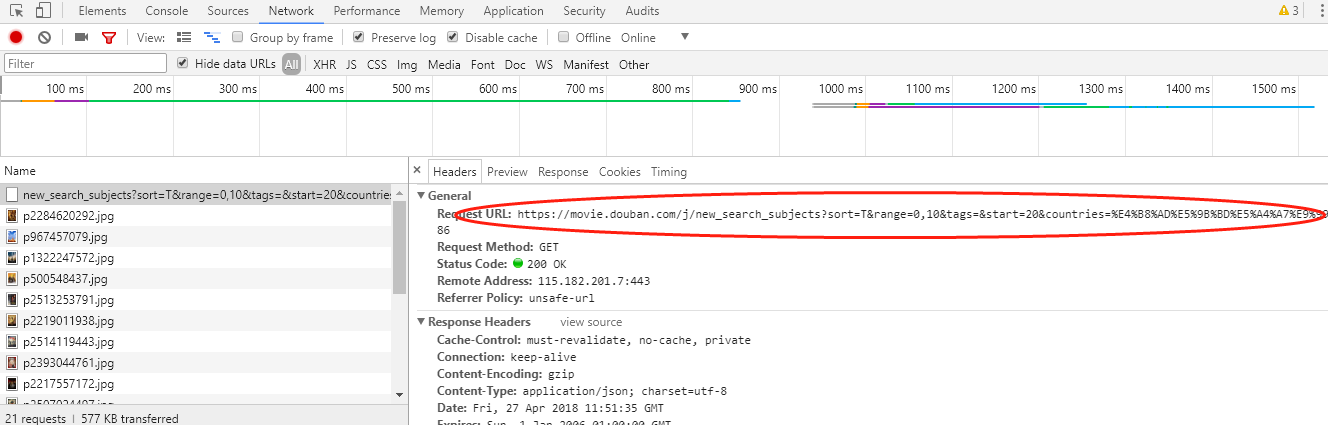
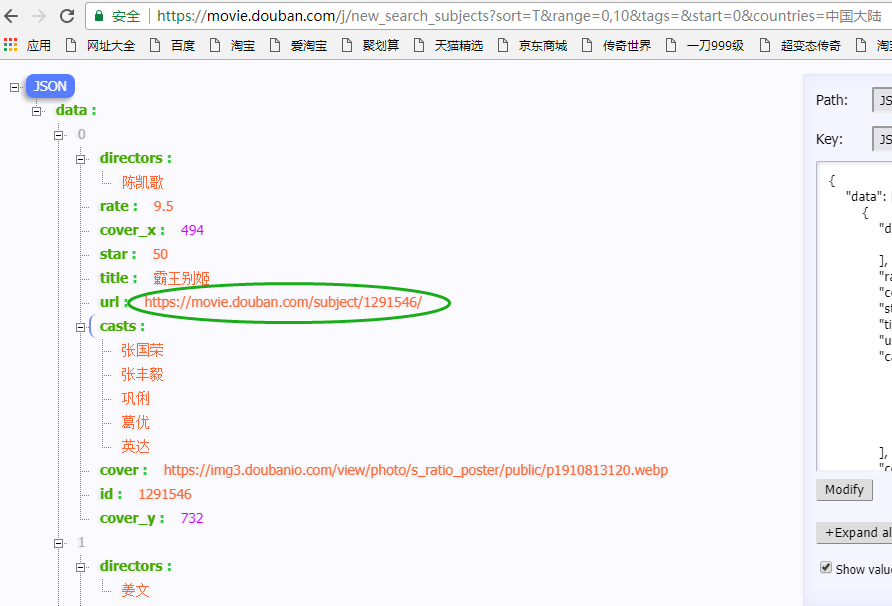
4.2获取关键url 14
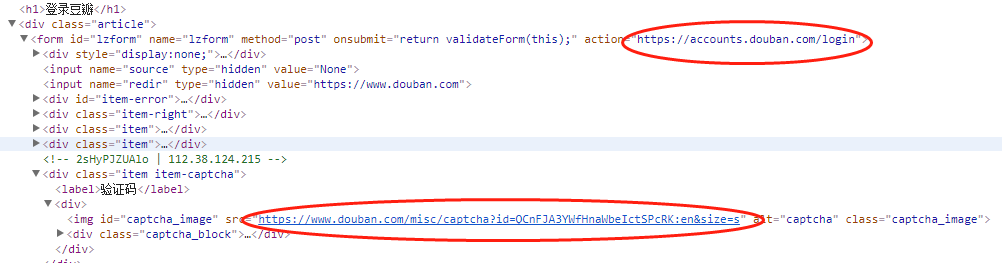
4.3 豆瓣登录 15
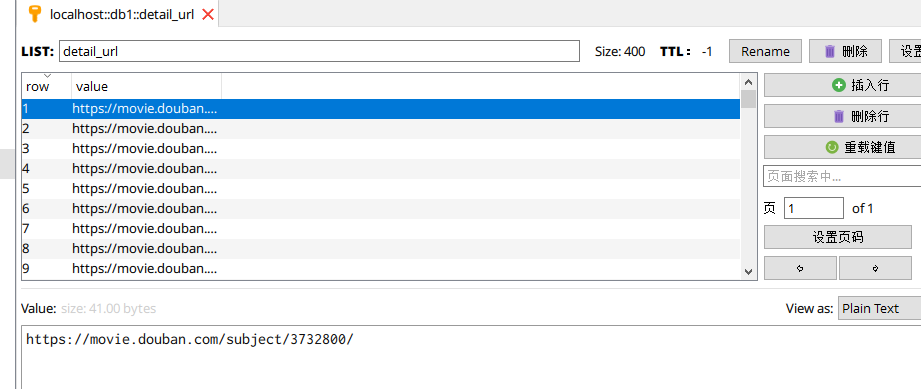
4.4 数据库设计 17
4.5 编写Scrapy爬虫 17
4.5 情感分析模块 20
5.结论 25
6.讨论 25
参考文献 26
致谢 27
基于网络社交平台的情感数据抓取与分析
赵政昕
,China
Abstract: In recent years, various social networking platforms have become an important channel for people to communicate. In these platforms, users can create contents themselves and express opinions and emotions. Sentiment analysis based on social networks has also become a hot spot.The purpose of this topic is to use python to write reptile crawling douban movie comments data, most of which are used as corpus, training it into a corpus, a small part as a test set, and then use SnowNLP to conduct a sentiment analysis of the test set based on a trained corpora. .
The main research work of this article includes:
(1) Based on python's scrapy framework for douban‘s domestic movie pages, combined with redis to design and compile a crawler program, which can simulate douban log in and automatically capture the movie reviews of a large number of movies in douban domestic movie pages, and store it in mysql database, The crawler adopts a certain anti-recovery strategy and possesses certain robustness and flexibility.
(2) Study machine learning based on Naive Bayes classification, python-based SnowNLP class library, write sentiment analysis program, use crawled film review to make corpus, train corpus, and conduct sentiment analysis on some of the captured film reviews.
Key words: Spiders; Sentiment Analysis; SnowNLP; Naive Bayes; Scrapy
1 绪论
1.1研究意义
近年来,社交媒体网站蓬勃发展,随着书籍、电影、音乐等社交网站以及各种购物网站的不断出现,这些网站上的用户评论已经成为一种重要的信息载体,大量的用户在社交媒体网站上发表自己的主观性看法。早在2004年,美国的一项调查就显示,该国的服装业、旅游业等行业中有超过40%的消费者会先去查看某商品的评论信息以决定是否购买该产品。
用户的评价对于商家、用户和政府的决策等都有很重要的参考意义,目前用户评价被广泛用于:①帮助用户做出决策;②给予商家用户的反馈;③舆情监测;④金融预测。
豆瓣拥有大量的用户群体,并拥有极其庞大的影评数据,而且热门短评中的评论相对微博评论等较为书面,且长度适中、重复率低,这些特点使得对于豆瓣影评的情感分析具有更高的准确率及更好的研究意义。豆瓣拥有打分系统,分值可以一定程度体现该评论的情感极性,同时豆瓣拥有大量的评论,这使豆瓣影评十分适合用来制定情感语料库。
综上所述,本文设计并编写了针对豆瓣影评的爬虫及情感分析程序,其意义在于基于豆瓣影评进行情感分析,并熟悉从数据抓取、入库、语料训练到情感分析的整个流程,为以后的进一步深入研究打下基础。
1.2国内外研究现状
1.2.1 网络爬虫的研究现状
网络爬虫是搜索引擎组成中一个不可获缺的部分,它可以自动的爬取和保存相关网页的内容。从上个世纪90年代就有很多人开始从事网络爬虫的开发工作,至今爬虫技术已经较为成熟。在网络爬虫的开发中,python是使用最为广泛的程序语言。Python为爬虫编写提供了丰富的开源类库和框架,scrapy就是其中的一种,基于scrapy,我们将不再需要从零构建一个完整的搜索器,而是只需要针对需要爬取的内容定制爬取规则,就可以很方便的进行开发。
1.2.2 情感分析研究现状
互联网的飞速发展,使得社交网络平台例如微博、豆瓣等出现了大量的使用者发布的主观情感性文本,这些主观性的文本的数量在急剧增长,假定使用人力去分析的话,显然成本巨大且难以实现,因此编写算法程序,让程序自动分析这些文本所表达的情感,就成了很多情感分析工作者的目标,这个研究领域称为文本情感或者意见挖掘[2]。
McKeown等人[1]将解释文本情感分析为:通过文本内容的分析、推理以及归纳等对特定的主观性文本进行分析,这些文本包含用户的观点、情感等。情感分析是一个涉及多种学科的研究方向,它与自然语言处理、机器学习、计算机语言、AI等领域都有着密切的联系[2]。情感分析根据分析粒度不同,划分为基于词语的情感分析和基于语句的情感分析两类,本文研讨的是基于词语的文本情感分析[9]。
基于词语的情感极性的识别是情感分析的一个基本方法。一般是使用区间[-1,1]间的某个数表示词语的情感倾向程度的权重,由此定量的计算词语情感极性[2]。当这个权重比0大时,代表这个词语是褒义的;当这个权重比0小时,代表这个词语是贬义的。情感的极性程度可以通过权重的绝对值体现出来。基于词语的情感极性分析有基于语料库的情感分析和基于词典的情感分析两大类[2]。
基于语料库的情感分析使用的办法一般是通过词语之间的连词和统计特征来判断词语的情感倾向极性值。Mckeown等人[1]通过词语的统计特征和词语之间的连词来判断词语的情感倾向程度,以此鉴定了以词语为粒度的情感分析的基础。国外方面,Go等人[3]较早的研究了朴素贝叶斯分类、最大熵、支持向量机等方法。国内方面,张靖等人[4]建成了情感信息倾向的特征模型,它基于二元语法的依赖关系,根据机器学习对分类器进行训练,使分类器能够自己识别词语的情感倾向极性。基于机器学习的情感分析不再过分的依赖于完善的情感词典,但是依赖巨大的人工标记的语料库[2]。
基于词典的情感分析的方法是通过人工整理的方式将大量的文本素材建立成情感词典库,里面包括连词和副词词典、领域特点词汇词典等,然后进行文本的分句分词,最后通过加权取和综合每个情感极性单元获得整体文本的情感值。国外方面,Cho等人[3]使用数据驱动的方法,过滤并整合了多个领域的情感词典,有效的提高了基于词典情感分析的准确度。国内方面常用的情感词典主要有哈工大情感词典、知网情感词典和大连理工情感词典等。
1.3论文结构
本文将分为4个部分。
第一章是绪论。用来介绍本文的国内外研究现状、研究意义等。
第二章主要用来介绍爬虫程序的相关概念和技术。着重介绍了网络爬虫、scrapy爬虫及爬虫模块中所使用的数据库等。
第三章介绍了情感分析有关的概念和技术。对snowNLP、朴素贝叶斯分类算法进行了分析描述。
第四章为实验部分,进行爬虫和情感分析模块的设计与实现,并从模拟豆瓣登录、爬虫代理、情感分析流程等几方面展开描述。
第五章总结本文展开的工作,并提出以后可以深入进行研究或者修改完善的地方。
2 爬虫相关概念和技术介绍
本章对爬虫模块中的概念和一些关键技术进行了介绍。首先对网络爬虫程序进行简单的阐述,然后对scrapy框架进行介绍,主要从scrapy框架描述、scrapy组件和scrapy运行流程等方面进行描述,之后对爬虫模块中所用到的数据库也进行了介绍。
2.1 网络爬虫程序
如今互联网信息爆发式增长,从大量网页中提取出有效信息愈加困难,而爬虫是一种可以自主化的搜集有效网络信息的计算机程序,其被广泛的应用在各类系统当中。
网络爬虫的流程大致为:获取到首个网页的URL地址,然后解析该网页中的内容,提取出该网页中我们所需要的下一级URL链接,去除重复的url链接后,以同样的方式获取下一级URL,以此类推,直至获取到我们最终想要的内容。
剩余内容已隐藏,请支付后下载全文,论文总字数:22112字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

