论文总字数:19325字
目 录
1链路预测算法的意义和发展过程 1
2 ALP链路预测算法 4
2.1 ALP算法的定义 4
2.2链路预测算法的评价方式 5
2.3 ALP算法的预测准确性和结构一致性 6
3几种链路预测算法的比较 8
3.1其他的链路预测算法 8
3.2实验步骤 9
3.3实验结果 9
4总结 13
参考文献 14
致谢 16
链路预测算法中预测准确性和网络结构一致性的研究
熊杰
,China
Abstract:In the current theory and practice, the link prediction algorithm has a very important role, it can not only help us understand the process of change of real network, and in the biological field, science field or social areas, the link prediction algorithm contains a huge potential for development. This paper mainly discusses several important link prediction algorithms, and compares their performance on prediction accuracy and network structure consistency. This paper want to find a link prediction algorithm, which can have a good prediction accuracy, and in the network structure can have a good consistency. The design of this paper is based on MATLAB under the windows system. The main operation of the experiment is to calculate the prediction accuracy of each link prediction algorithm on the same complex network, and then reconstructs the network based on the link prediction algorithm, and finally compares the attribute difference between the original network and the reconstructed network.
Key words:Link prediction algorithm; prediction accuracy; structural consistency.
1链路预测算法的意义和发展过程
随着大数据时代的到来,各种互联网 事物的兴起,无论是国家,社会,个人都对大数据产生了高度的重视,而当前的各种大数据之间关系更是各类商家们争先研究的对象。由于数据之间很多都是有联系的,所以它们基本上都是通过相互之间的关系最终形成了一个复杂的网络。因此,通过研究这些复杂的数据网络中的关系,从而获取其中自己想要的信息,进而利用这些信息,来进行商业获利以及科学研究的工作,已经变成了目前社会热点讨论的话题。在研究复杂网络的工作当中,研究网络中的相互关系已然成为当前形势下重点讨论的对象。为了对这个问题进行深入的研究,已经在网络结构预测中有显著作用的链路预测算法就成为了人们重点研究的对象。
网络中的链路预测(Link Prediction)的意思是使用已经知道的网络节点消息和网络结构的属性值,进而预测网络中还没有边相连的两个节点之间产生链路的可能性[1]。如下图1是链路预测算法的流程图。首先,我们得到一个原始网络,我们将这个网络拆分为训练集和测试集。之后,我们使用链路预测算法来处理训练集,处理之后我们会得到一个相似矩阵,矩阵中的每条边都有一个权值,我们从中选出top条链路,top的值是测试集中链路的个数,而且选出的链路不能是训练集中的元素。然后,我们将选出的链路和训练集重构成新的网络,最后,我们比较原始网络和重构网络的属性值,进而判断一个链路预测算法的好坏。
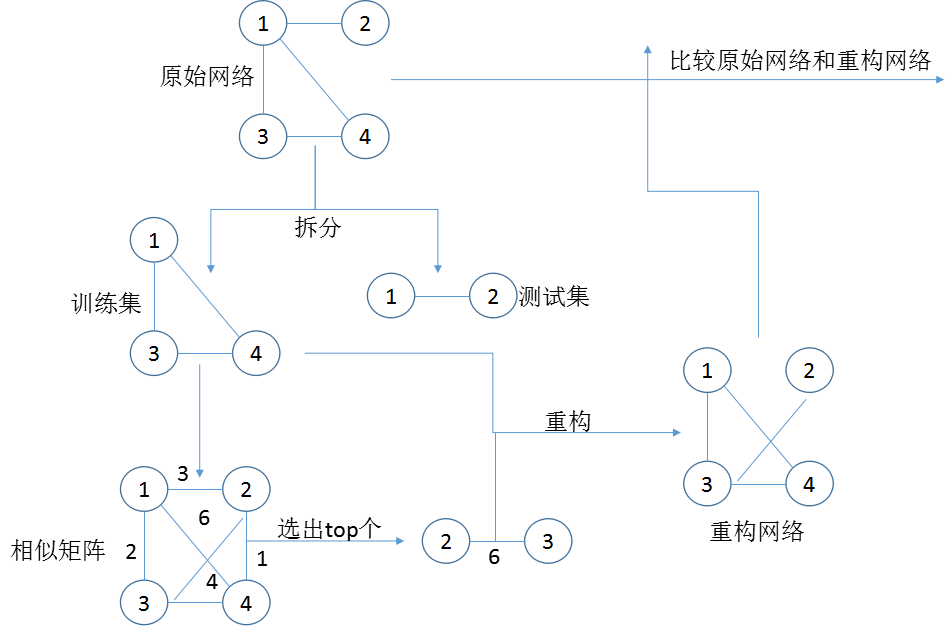
图1 链路预测算法的流程图,圆圈中的数字表示的是第几号节点,每条边上的数字代表权值。
链路预测的核心分为两个方面,第一个方面是在完整的网络上,通过链路预测算法的预测,我们希望它能够获得一个预测结果,这个预测结果代表的是在未来的一段时间内,该网络可能会发生的变化,主要是网络连边的添加。意思是使用预测算法计算之后,之后网络中可能会有哪些新的边被添加到网络中。接着是第二个,在一个原本完整的网络中,由于某些原因,原本存在于网络中一些连边丢失了。为了找回这些丢失的边,我们希望使用链路预测算法计算之后,能够尽可能准确的找到这些丢失的边。这两个功能好比是预报功能与恢复功能,预报功能是通过当下的一些条件,猜测未来可能发生的事情,这就类似于现在的天气预报和灾害预警。恢复功能就像是灾害之后的重建工作,而链路预测算法在其中就充当了重建规划图的功能。
网络的发展,许许多多的东西也是被数据化,格式化。比如,社会可以被描述成一个网络,学校可以被描述成一个网络,学生可以表示成一个节点,而学生之间的各种关系就可以表示为丰富的连边等等。链路预测算法的应用体现在社会中,最明显的就是现在的各种推荐系统了,比如QQ的好友推荐系统,网易云音乐的音乐推荐系统,淘宝的商品推荐系统等等。这些平台都拥有很好的东西,但是在推荐系统出现之前,它们仅仅就是将自己拥有的东西摆在这个平台上面展示而已,顾客在这个平台上面寻找东西,往往都是根据自己确实需要的东西而进行查找,局限于顾客知识面的狭窄,很多好的东西并不能第一时间呈现在顾客面前。而当前,基于链路预测算法的推荐系统不光能够第一时间推荐与顾客相关的商品,而且还会根据每位顾客不同的购物习惯进行精准的推荐。这样的推荐系统基本上已经能够充当现实世界导购员的职位了,这样不仅大大方便了顾客,而且也为商家提高了销售量。在这之中,链路预测算法就充当了参谋的作用,分别为不同的顾客推荐商品进行出谋划策。当然,链路预测算法的作用还不仅仅是推荐系统,在其他的许多方面也有应用。在生物学领域,许多代价昂贵的实验可以经由链路预测算法来削减预算。通过了解一部分网络节点的类型信息,链路预测算法可以预测出剩下的节点的信息--这可以判断一篇论文的类型[2]。为了检测网络中的异常数据,链路预测算法也常常被用来进行非法资本操作的预测等等。
链路预测算法不单有以上的应用价值,而且在理论上,也同样有着不可或缺的重要价值。网络是复杂多变的,我们常常根据网络中的各种属性来描述这个对象,比如节点的个数,网络中边的个数,该网络是有向图还是无向图等等。但是这么多的属性,往往只能描述网络的部分特点,我们很难从一个整体的思想来给网络建立一个模型。链路预测算法的本质就是要找出网络节点之间边的产生原因和驱动力,而且这也是网络演化模型一直在寻求解决的问题[3]。直接比较网络演化模型好坏,存在着很多困难。理论上来说,一个网络的演化模型原则上都可以用一种链路预测的算法来对应,于是我们就能够通过评估不同链路预测算法进而评估不同的网络演化模型。链路预测算法的最终的目的是能够找到一种相对较好的算法,它不仅能够很好的还原最初网络,同时也能够较为准确的预测复杂网络的发展。链路预测算法不仅局限于推测网络链路的变化,它也可以应用到相关的算法的优化。例如,由金超等人提出一种基于链路预测的图聚类算法,它的核心就是利用局部相似性指标(RA)的链路预测算法来优化边介数的计算,从而提高了图聚类算法的效率[4]。当前在链路预测算法的研究上,相似性分数指标是一个有着重要作用的预测工具。链路预测算法的核心就是给出一种相似性分数的概念,然后判断这种给分的概念是否能够准确的描述一个网络中节点之间的联系,从而进一步研究网络中的结构特点。链路预测算法中的这种相似性指标对于复杂网络研究有着积极的推动和借鉴作用。
链路预测算法其实很早以前就出现了,之前的研究就曾出现在数据挖掘领域和机器学习领域。本文下面描述的链路预测算法的发展历程引用了科学网中吕琳媛老师的博客文章《复杂网络观察:链路预测的研究现状及展望》。文章中提到的链路预测发展过程都逐一引用了对应的参考文献,文章中提到:关于链路预测算法的研究,最初是将网络的链路预测以及路径的分析通过马尔科夫链来进行[5]。仅仅是理论研究还不够,还需要将它扩展到现实世界中去。紧接着,这种预测方法便应用到自适应性网站的预测中[6]。预测链路的方法开始迅速应用,它开始在学术研究的网络中对科学文献之间的相互引用联系进行预测等等。马尔科夫链的网络链路预测终究存在着局限性,之后便有人提出了使用网络的结构信息和节点间的属性值创建一种局部的条件概率模型,通过这种模型进行链路预测[7]。
目前为止,链路预测算法的延伸很宽,已经产生了几种类型的预测方法。首先是基于结构信息的相似性预测方法,目前为止它已经成为了研究最多的一种方法,其次是基于最大似然估计的方法和基于概率模型的预测算法,虽然它们的研究较少,但是它们的重要地位是不会变的。尽管它们进行预测的角度分别不同,但是都是使用已知的数据信息,最大程度上的描述网络结构的演化过程[8]。这其中的相似性链路预测方法受到越来越多的重视,这种算法的核心就是两个节点间给出的相似性分数越大,那么节点有边相连的可能性就越高。所以,定义相似性变成了研究重点,相似性分数的定义多种多样,可以是节点之间的平均最短路径长度,当然也可以是节点附近的邻居个数等等。虽然定义很多,但是都是可以分类的,基于网络结构相似性得分的概念的不同定义,这些指标可以被分为基于节点和基于路径的两类[9]。随着链路预测算法的研究深入,越来越多的相似性方法被提出。其中周涛等人提出了两种新指标:资源分配指标(RA)和局部路径指标(LP)[10]。之后张成军提出了一种基于局部路径指标的权重局部路径(weighted local path)[11]。不久之前,赖大荣等人提出了一种在复杂网络中的基于模块化的置信传播的链路预测算法(BMPA)[12]等等。链路预测算法的研究受到多方面的关注,同时一系列的成果也是发表出来。比如,基于概率模型的引入效用函数分析的社交网络链路预测方法也在今年提出,该算法以决策分析的理论将效用函数引入链路预测的分析[13]。相信在未来的发展过程中,还会有更多优秀的链路预测算法被发表,而且发展趋势良好,关于链路预测算法的理论研究将逐渐的形成一套完整的体系,并最终作用于社会生活之中。
目前链路预测算法的研究工作很多都是基于节点间的相似性,研究学者们试图获得网络中节点的信息,进而提高预测算法的准确性,但是其中的过程却是曲折的。首先是网络中的数据往往是非常巨大的,光是存储数据就要花很大功夫。其次是网络数据的获取也不容易,网络的大数据大部分掌握在商业公司手里,属于商业机密。然后是数据的可靠性,很多的网络数据都是虚假的,大部分网民在网上的使用信息都是编造的。最后,即使获得的数据是真实的,我们怎么确定该数据是否对于算法有用。另外,很多研究者将链路预测算法的重心放在提高预测的准确性上面,忽视了该算法对于网络结构的影响。一个好的链路预测算法不仅能够准确的预测缺失的链路,同时也能够尽可能使预测后网络的结构和原始网络相近。如果一些未知链路被错误的识别成缺失链路添加到网络之中,那么网络系统的结构和功能将会产生巨大的改变。当然,也有一些研究是关于移除网络中的这些错误链路,但是有关在链路预测算法中的错误链路的移除的系统性研究还没有进行过。当前一些预测准确度高的链路预测算法在保留网络结构属性上并不一定比一些预测准确性低的算法效果好。而且大部分的链路预测算法在重构网络上都存在一定程度上的网络结构和性能的失真。基于节点的相似性算法已经有很多了,但是还没有算法性能和网络结构特征之间关系的较深入的研究。
剩余内容已隐藏,请支付后下载全文,论文总字数:19325字
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

