论文总字数:23705字
目 录
一、绪论 1
1.1引言 1
1.2词袋模型的发展和研究现状 2
1.3课题内容与意义 2
1.4论文内容结构 3
二、算法分析 4
2.1整体分析 4
2.2功能分析 4
2.3过程分析 5
2.4应用程序分析 5
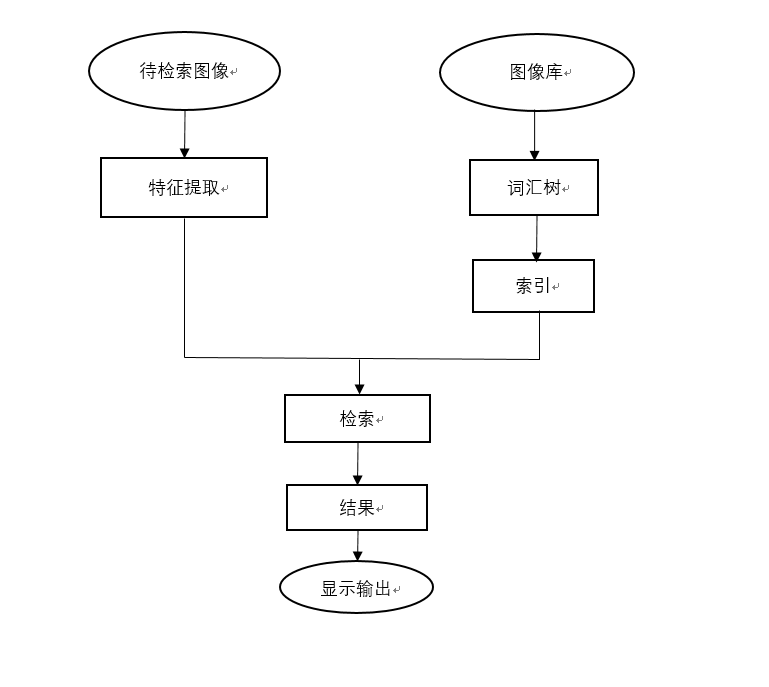
2.4.1选取图像库与待检索图像 5
2.4.2图像库处理 5
2.4.3图像检索 6
2.4.4结果显示 6
三、模型介绍 7
3.1词袋模型 7
3.2词袋模型在图像检索中的使用 7
3.3 BOW图像检索的一般步骤 9
3.3.1特征提取 9
3.2.2词典构建 10
3.2.3建立索引 11
3.2.4图像检索 12
四、算法核心 12
4.1总体概述 12
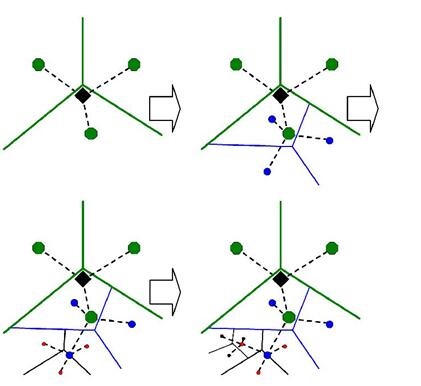
4.2词袋模型的改进——词汇树 13
4.2.1词汇树结构 13
4.2.2词汇树的构建 13
4.2.3词汇树的存储 15
4.2.4词汇树的优势 16
4.3 索引结构 16
4.3.1索引结构 16
4.3.2索引存储 17
4.4图像检索 17
4.4.1检索原理 17
4.4.2相似度量化 18
五、算法与程序实现 19
5.1语言 19
5.2实现环境 19
5.3相关支持插件 19
5.4算法与应用实现 19
5.4.1 SIFT特征提取 21
5.4.2 K-means聚类 21
5.4.3构建索引 22
5.4.4图像检索 22
5.5应用实现 22
5.5.1界面 22
5.5.2界面数据处理 24
六、算法效用分析 26
6.1检索准确性 26
6.2检索时间 27
6.3图像库处理耗时 28
6.4辅助文件占用空间与读写性能影响 28
七、总结与展望 30
7.1总结 30
7.2展望 30
参考文献 31
致谢 33
一、绪论
1.1引言
随着互联网的普及,新的图像会不断出现于网络中,这在丰富了互联网图像资源的同时,也不可避免地造成了图像信息的泛滥,因此现今的人们往往具有搜索类似图像的需求,即“以图搜图”形式的图像检索。
“以图搜图”正是当今计算机视觉领域与图像处理领域一直非常重要的课题,随着互联网服务的不断推进,现在世界多家互联网服务提供商都构建了自己的图像检索系统,并提供了便捷的入口,向广大互联网用户提供图像检索服务。例如国内的百度识图、著名的GazoPa引擎在国内建立的寻图网,国外的谷歌识图、必应、Tineye等平台。这些平台除了拥有成熟的图像检索系统与算法外,基本上都拥有成熟的互联网图像提取能力,通过维护一个庞大的动态图像资源数据库,以满足用户对于互联网图像的搜索需求,这也是谷歌、必应、百度在图像搜索服务领域较为成熟的原因。
现今的图像检索方式主要有三种,基于文本的图像检索、基于内容的图像检索,以及结合文本与内容的图像检索。基于文本的图像检索通过人工对图像设置标签、关键词等实现检索,而基于内容的图像检索则是由计算机对图像内容进行分析归纳。“以图搜图”的图像检索方式属于基于内容的图像检索,目前主流的基于内容的图像检索,是借助图像中的颜色、形状、布局、纹理等全局视觉特征,以此归纳出图像的内容,通过内容进行图像分类,以此确定图像间的相似度,从而实现图像检索。在基于内容的图像检索中,词袋模型(Bag of Words)是核心思想之一,也是基于内容的图像检索中使用最广泛的检索模型之一。词袋模型在图像检索中的表现形式如图1-1所示。
图1-1 图像检索中的词袋模型
客观来说,目前基于内容的图像检索方式都是计算机对图像进行处理后的数据量化与对比过程,这与人类主观的图像感知过程存在差异,有时其结果也不足以令人满意。因此当前主流的图像检索平台都是采用文本标签与内容分析相结合的检索模式,从两个大方向共同入手,以实现准确性与便捷性的平衡。
1.2词袋模型的发展和研究现状
词袋模型,即Bag of Words模型,最初是用于文本分类的一种概念模型,通过将文本中的单词作为特征进行频率统计,从而对文本内容进行分类标识。
而后,词袋模型被引入计算机图像处理领域,Gabriella Csurka 等人在2004年提出将BOW模型应用于图像分类,并得到了良好的效果,他们证明了BOW模型对较为复杂的图像集仍具有相当的适应性[1]。
在BOW模型引入计算机图像领域的初期,研究人员与工作者大多将之应用于图像的内容分类中。由于图像中的形状及颜色特征具有相似性,通常将特征作为单词,利用单词的频率信息进行图像分类[2][3][4]。
近些年随着研究者对BOW模型研究分析的逐渐深入,BOW模型也逐渐成为了主流的图像分类和识别模型,被广泛应用于计算机图像相关领域。何友松等人在2009年将BOW模型应用于图像识别领域,他们提出将 SIFT 算法和 PLSA 分类算法结合,来实现汽车及行驶过程中的背景图像分类[5]。
BOW模型的基础是图像的特征提取,而各种图像特征提取算法的提出和发展,也让BOW模型的效用不断提升。David Lowe 在1999年提出尺度不变特征转换算法,即SIFT算法,并于2004年进一步完善总结[6]。Chao Zhu等人对SIFT特征维数较高的不足进行了改善,提出了一种快速局部特征DAISY来对图像进行特征提取,并使用BOW模型进行处理,验证了其性能较SIFT特征更为出色[7]。Abdullah A等人对图像SIFT特征数目较大时性能欠佳的问题进行了改进,通过结合多种特征,并将两个整体分类器结合进行分类,使图像分类的性能得以提升[8]。而后一系列相对于图像的不变局部特征的提取方法也陆续被提出[9][10][11]。
现今对词袋模型的研究方向,逐渐从特征提取方法转向对词典构建方法的探讨与优化,以及对其分类方法的研究。一些基于BOW模型的改进图像分类及检索模型也相继出现,其中David与Henrik等于2006年提出的词汇树模型[12]正是其中具有卓越效果的方案之一,也正是本论文算法中所采用的词袋模型改进形式。
1.3课题内容与意义
本课题的主要内容是设计并实现一个基于视觉词典模型的图像搜索算法,实现日常图像检索的需求。
本课题的主要意义是提出了一个基于传统BOW模型的改进型图像检索算法,它是词袋模型图像检索的进一步发展,通过将传统BOW模型中的词袋替换为词汇树,从而得到更好的检索效果。
由于BOW模型在图像检索中已经被广泛使用,因此基于传统BOW模型的图像检索算法潜力已经相当有限,而单纯基于BOW模型的图像检索也很少会被单独使用,通常会与其它图像检索模型,如LSH模型[13],以及基于文本的图像检索[14]方式等结合使用。同时一些基于传统BOW模型的改进型图像检索方法[15][16]也被提出,本论文中借助词汇树结构实现的这一算法正是此类改进型图像检索算法的一种。
1.4论文内容结构
本论文较为全面地展现了基于视觉词典模型的改进模型,即词汇树模型图像检索算法的内容与实现,包含算法描述、算法结构、算法实现、算法效果等,还包括本人开发的桌面应用程序。
论文共包含七章:
第一章绪论部分表述了本课题的研究内容与基本情况,从课题目标与背景上介绍了本图像检索算法的意义。
第二章是对算法整体功能与应用程序流程的分析,包括算法的目标与应用的运行步骤,是算法与应用设计的必要环节。
第三章着重介绍了BOW模型的结构,以BOW模型应用于图像检索的四个主要步骤为要素,将词袋模型图像检索的过程进行了详细的介绍。
第四章对本算法的核心内容进行了说明与展示,包括词汇树模型的结构特点,本算法中对词汇树的构建及使用方式,相似度量化的具体内容等。
第五章是算法的具体实现,介绍了算法的实现环境,项目结构,和以该算法为基础的图像检索程序的基本要素。
第六章对于该算法的执行效果进行了分析,包括图像匹配度、检索耗时、图像库训练时间、辅助文件占用空间等方面的分析。
第七章对整个课题内容进行了一个全面的总结,并表达了一些我对于计算机视觉领域的认识。
二、算法分析
2.1整体分析
基于视觉词典模型的图像搜索算法属于基于内容的图像检索(Content-based Image Retrieval,简称CBIR),是基于内容的信息检索范畴。区别于以关键字或标签等人工分类方式进行检索的图像检索方式,检索所需的人工支出基本为零,全部由计算机运行算法实现。
“内容”是计算机对图像所包含信息进行获取、处理、抽象得到的分析结果,是计算机对图像进行识别与表示的中间形式。通常来说,计算机对于图像内容的识别与人类对图像的直观感知结果有很大不同,但两者根本上都是对图像的一种处理与分析。计算机得到的图像“内容”是其辨识图像间相似度的依据,而基于内容的图像检索正是依靠计算机对比图像间的相似度,以此来得到符合要求的检索结果。
2.2功能分析
本算法的设计目的是实现基于内容的图像检索,即满足检索者“以图搜图”的客观需求。在给定检索图像库与待检索图像的条件下,能够检索出符合一定相似度标准的图像集。基于内容的图像检索方式如图2-1所示。

图2-1基于内容的图像检索
2.3过程分析
基于内容的图像检索算法,初始所需的输入变量有两个,待检索图像与检索图像库,算法的输出结果是图像库中符合检索需求的图像集。其基本过程是,用户提供一张待检索图像,根据图像检索算法,在既定的图像库中进行查找与匹配,输出搜索结果,这就是基于内容图像检索的一般过程,如图2-2所示。
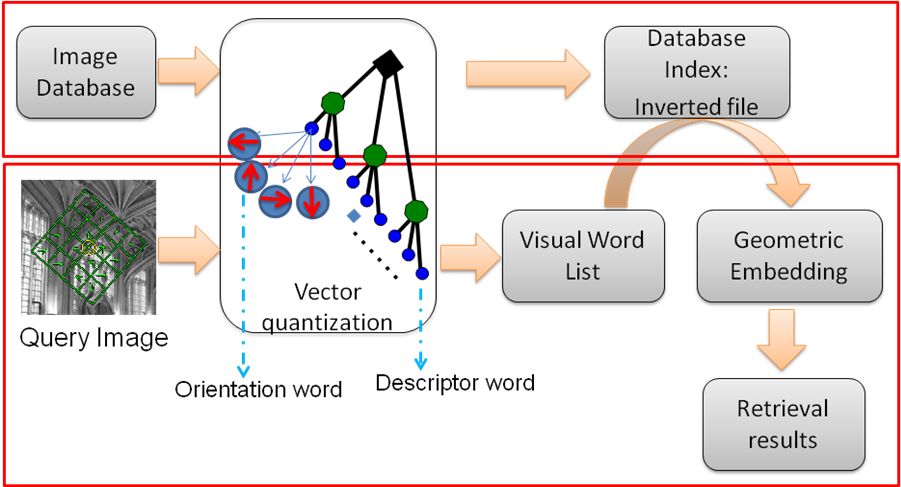
图2-2 基于内容的图像检索过程
2.4应用程序分析
在实现算法的同时,编写一个可交互的桌面应用也是课题的目标。图像检索算法是程序的核心,但该应用的运行过程并非完全按照算法的步骤划分,应用的运行流程应当包含这样一些步骤。
2.4.1选取图像库与待检索图像
这是算法的输入步骤,通过选择路径来选取图像库与待检索图像。一旦选取图像库文件夹,会在应用的根目录下创建一个对应序号的文件夹,用以存放该图像库的词袋结构与索引文件。为了管理图像库与对应文件夹序号间的映射,使用一个文本文件来存储映射信息。
2.4.2图像库处理
对于输入的图像库,对其进行处理,准备好图像检索的必要条件,从而使图像库中的图像得以直接被算法调用并参与检索。对一个已知图像库的处理结果是唯一的,只需要图像库(中的图像)确定后,图像库处理流程就可以进行。考虑实际的图像检索服务需求,应当保证在使用现有图像库对检索需求进行应答之前,已经完成图像库的处理流程。当用户提交检索需求时,可以直接进行检索步骤得到结果。而从用户的角度来说,图像库处理的具体过程是被屏蔽的,是一个用户不必关心的过程。
2.4.3图像检索
进行图像检索,得到结果。对于用户来说,这可能是最主要的步骤,但对于整个检索流程而言,这只是获取结果的一步而已。依靠已经建立的图像库检索条件,在图像库中进行相似度对比,筛选出的符合条件的图像集即为检索结果。我通过设置一个相似度阙值来控制输出的图像数量与质量,只有相似度达到阙值的图像才会被加入检索结果中。
2.4.4结果显示
检索得到的匹配图像集会在界面上显示出来,用户可以通过与界面的交互,在系统默认的应用中查看这些图片。
应用包含的以上功能步骤与算法的执行步骤间存在一定的对应关系,实际上算法内容包涵于应用的图像库处理与图像检索的部分中,具体的关系我会在第五章中进行说明
三、模型介绍
3.1词袋模型
词袋模型即BOW模型,英文表述为Bag of Words,最早是一种文本分类概念模型,其基本思想是:将文档表示成一系列单词构成的集合。对于一个文本语句,我们忽略它的词序、语法和句式,仅仅将其看作是一些词汇的集合,这些词汇都是彼此独立的。一篇文章中会有很多语句,而这些语句都是由词汇构成的,这些词汇的集合即为我们所说的“词袋”,或“词典”。
剩余内容已隐藏,请支付后下载全文,论文总字数:23705字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

