论文总字数:21821字
目 录
1 绪论 1
1.1 研究背景 1
1.2 研究意义 2
1.3 研究现状 2
1.4 文章结构 2
2 用户画像 3
2.1 用户画像的简介 3
2.2 用户画像的分类 4
2.2.1 明确的用户画像 4
2.2.2 模糊的用户画像 4
2.2.3 混合的用户画像 4
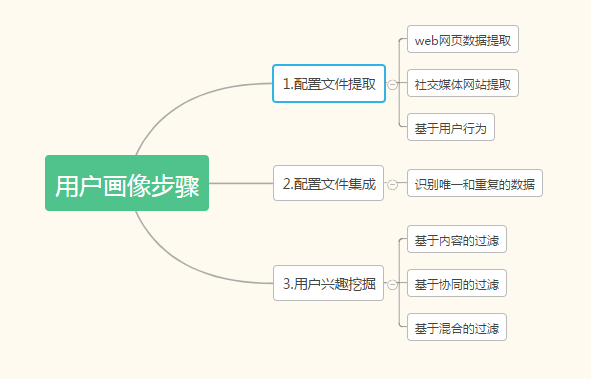
3 用户画像的步骤 5
3.1配置文件提取 5
3.2 配置文件集成 6
3.3 用户兴趣挖据 6
3.3.1基于内容的过滤 7
3.3.2基于协同的过滤 8
3.3.3基于混合的过滤 9
4 聚类分析 10
4.1 聚类分析与聚类模型 10
4.2 聚类算法 11
5 k-means 13
5.1 k-means算法 13
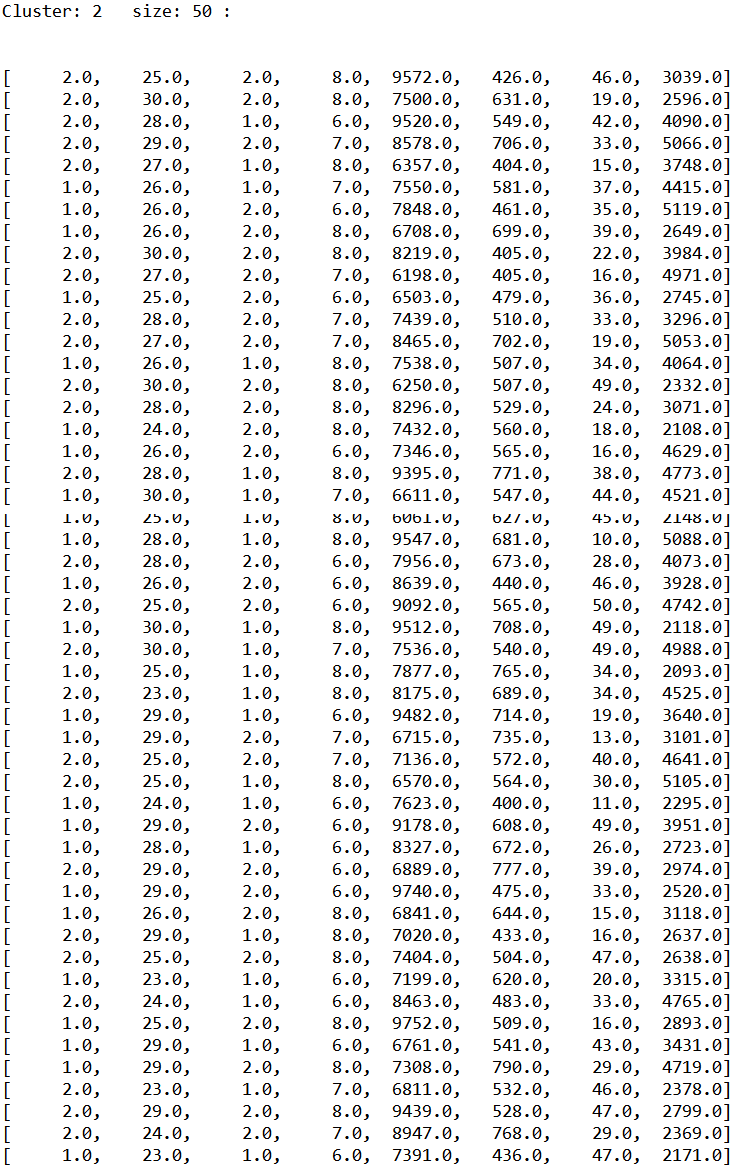
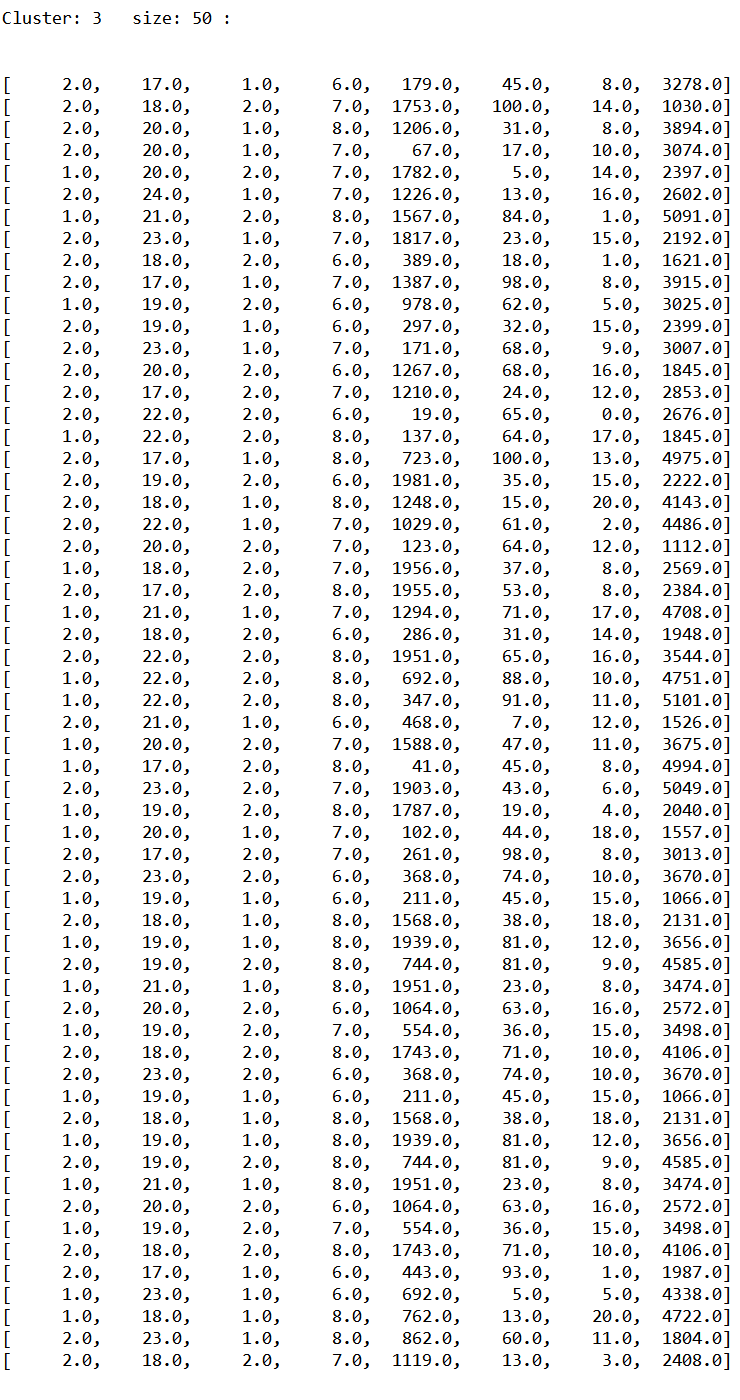
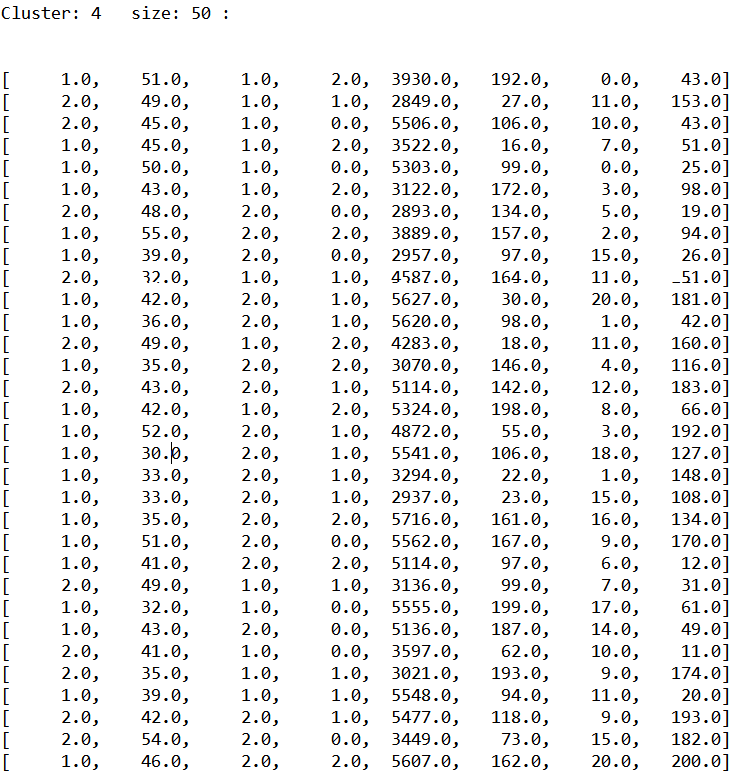
5.2 k-means实例 13
5.3 k-means代码解析 17
6 总结与展望 23
参考文献 24
致谢 26
用户画像及其实现技术
费淼玉
,China
Abstract: The rapid spread of mobile Internet and smart phones not only has brought convenience to consumers, but also has promoted the vigorous development of big data. In the prevalence of big data, the term “user profling” has also been widely popular on the Internet. In this article, I mainly introduced the main contents of the user profiling, application and implementation methods, furtherly interpreted the clustering analysis technique on the bottom of the user profiling in detail, and used codes to analyze the current popular k-means clustering algorithm.
Keywords: user profiling;clustering analysis;k-means;
1 绪论
1.1 研究背景
据有关数据显示,2015年,全球大数据市域规模为384亿美元,其中,中国的大数据市域规模为115.9亿元人民币,预计在2017年全球大数据市域规模将会增长至721亿美元,而中国的大数据市域规模将会达到221亿元人民币。除了大数据增长的速率如此之快,移动互联网的增长速度也不容小觑,移动互联网正在以一种潜移默化的方式影响着我们社会生活的各个方面,互联网 行动更是受到了国务院的重视。有数据显示,2015年中国移动互联网的市域规模为3981.5亿元,同比增长约77个百分点,预计2017年时中国移动互联网的市域规模将会增长至9600亿元,其增速之快、规模之大是超乎我们想象的[1]。
移动互联网以其“小巧轻便”的特点决定了它和PC互联网的根本不同之处,PC互联网作为长久以来人们赖以使用的互联网自然是在不断发展的,但发展日趋平稳,毕竟,随着中国经济的快速发展,几乎家家户户都已经有了电脑,因此PC互联网基本上不会有太大的增长幅度,相反,移动互联网发展迅速,增速可观。随着人们使用智能手机越来越频繁,大部分人都是手机不离手的状态,人们产生的用户行为数据日益庞大。对于大数据的定义,不同的机构和个人都给出了不同的定义,我比较认同的是IBM提出的5V定义,参考图1,即Volume(数据规模很大)、Velocity(数据产生速度很快,具有时效性)、Variety(数据包括各种形态)、Value(数据的价值密度低)、Veracity(数据具有真实性)[16]。单纯的数据其实价值不大,在大数据时代之前世界一样存在很大规模的数据,但是,以前这些数据并没有带来那么多的经济效益。而今,很多走在大数据时代前列的企业都纷纷依托大数据获得很多经济利益,原因就在于,他们懂得对大量数据进行有效加工,然后对加工好的数据进行各种分析,把用户可能最想看到的或者最需要的内容推送给用户,用户体验更好了,那么经济收益自然也就增长了。因此,在大数据背景下对于用户的研究即用户画像的实现极为重要。
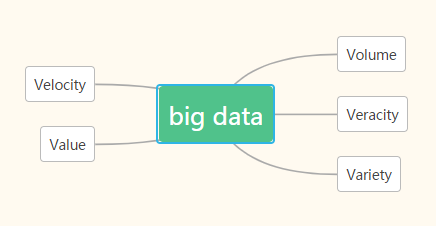
图1 大数据5V定义
智能手机在我们生活中扮演着不可或缺的角色,移动互联网可以记录用户的各种行为信息,给用户画像可以为以后的数据建模、用户分类、用户产品推送提供事实依据,因此对用户画像的研究有着深刻的意义和价值。
1.2 研究意义
随着移动互联网的不断壮大,人们逐渐放弃了在PC端的购物习惯,转而使用移动端,很多网站如淘宝、京东等同样的商品在移动端购买会便宜一些,在这样的刺激消费下,人们经常在移动端进行购物。除了购物在移动端便宜以外,听歌、阅读、玩游戏等在移动端也明显便捷很多,无须等待漫长的开机时间,点开一个APP就可以轻松得解决我们的需求。一个企业想要长足的发展,获得高水平的收益,就必须将用户摆在首要位置,用户体验满足了,营销策略才算成功。因此,研究用户行为,将用户的群体特点找出来并分好类,给不同类别的用户他们所需要的服务,“私人定制”,这样才能更好的创造价值。
当然,对于不同领域不同行业的企业,用户的行为特征都是不一样的,企业想从用户身上获得的潜在信息也各不相同,这样就会使得不同行业的企业都需要有自己“定制”的用户画像模型[2]。
1.3 研究现状
用户画像的研究,其实也就是对人物特征的研究,在互联网背景下它是一个新的定义,近些年来,用户画像在人机交互、机器学习等方面经常被提起,用来代表用户群体。目前,国内有一些做大数据用户画像的工具,比如说Cobub用户行为分析平台发布的Cobub Cloud云服务新增了一个功能模块——标签画像。除了免费的这种云平台服务,还有一些付费的服务,如百分比提供的用户标签管理系统等[3]。
在国外,对于用户画像的研究起步更早。KK Karthikeyan,CS Ramani Gopal,G Palaniappan在用户画像建模方面进行了研究,用于改进客户关系管理。B Mont-Reynaud,J Huang,KG Lokeswarappa,J Gedalius研究了构建一个集成的用户画像所需要的方法和系统。T Song,DY No,JC Kim三人研究了在基于位置的社交网络中用户画像消失的原因[17]。不同的研究人员对用户画像的研究方向都是多种多样的。
综合国内外用户画像的研究现状,可以看出,国内外的各个领域各个行业都或多或少得涉及到用户画像的研究。
1.4 文章结构
本论文主要采用相关的理论知识和实际数据分析相结合的方法,对用户画像的各个方面进行研究,并着重研究用户画像中的用户行为这个方面,在众多聚类算法中选择一种算法将用户数据进行分类,得出不同的用户人群特征,完成用户画像的构建。
第1章为绪论内容,主要通过此章节对本文的选题背景和研究意义做出论述,并论述了用户画像在当今社会的国内和国外的研究现状,本章结尾是论文的组织结构,方便读者看清本论文的思路和结构。
第2章为用户画像概述篇,详尽而全面得解释了用户画像的简介、使用场景、分类等。用户画像可分为明确的用户画像、模糊的用户画像、混合的用户画像。虽然用户画像这个概念已经在早年间被提出,但是很多人都未曾听闻过这个名词,人们很容易将其误解为给用户画“自画像”等美术方面的东西,因此,我认为这一章的介绍是很有必要的,让读者初步了解何为用户画像。
第3章为用户画像的步骤篇,配置文件提取,配置文件集成和用户兴趣挖掘。本章还讨论了几种过滤技术,分别为基于内容的过滤、基于协同的过滤、基于混合的过滤,并比较了三种过滤技术的优缺点。
第4章为聚类分析篇,介绍了聚类分析和聚类模型的定义,同时列出了几类常见的聚类算法:分区聚类、分层聚类、密度聚类,为第五章的k-means算法起到引入的作用,k-means算法就是分区聚类算法的一个典型。
第5章为k-means算法的实例篇,介绍了那么多技术、算法,本文采用k-means聚类算法对样本进行聚类分析。本章介绍了k-means算法的流程步骤并贴出了重要的代码实现部分,让读者对k-means算法有个更形象的理解。
第6章为总结和展望篇,对整篇论文进行总结,并指出文章的不足之处,望以后加以改进。
2 用户画像
2.1 用户画像的简介
今天,各种电子设备(例如智能电话,平板电脑)的用户可以使用众多的服务。在这个竞争激烈的市场中,用户画像对于服务供给商来说是非常重要的,用以实现成功的服务个性化。个性化在计算机科学领域已经非常重要,具体涉及推荐系统的应用。推荐系统需要处理的用户众多,每个用户都有自己的偏好要求。推荐系统需要通过向用户推荐用户特定的项目或通过根据用户的需要修改自身来满足每个用户的要求。因此,用户画像可帮助推荐系统了解用户需求,并根据用户需求进行操作。
用户画像是随着数据挖掘和机器学习方式的发展而变化的。它的根可以在知识数据发现模型(KDD)中找到,KDD模型中的许多步骤类似于用户画像过程中涉及的步骤[18]。本文将用户画像称之为为用户数据发现模型(UDD)。
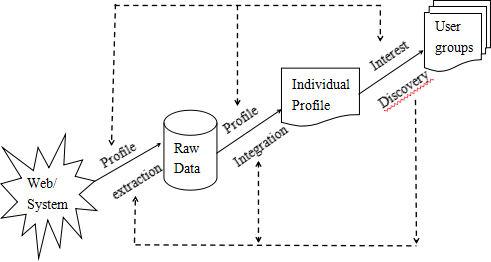
图2 UDD模型
为了显示KDD过程和UDD过程之间的相似性,图2中描述了修改后的KDD模型。在KDD模型中,已经有一系列可用于系统的数据,而在UDD模型中,系统具有关于用户的很少的信息,并且系统必须及时获取有关可用于进一步操作的用户的知识。
获得知识是这两个系统的主要目标,但是他们执行这个任务的方式才是重点。一种情况,需要从大量数据中提取知识的一个方面,即它必须处理可用的数据以找出有趣的东西,而另一种情况则包括数据量非常少的数据,但是还是要从中获取跟用户相关的知识。
2.2 用户画像的分类
用户画像通常从信息检索和用户信息的收集开始。较旧的系统更关心的从用户直接获取的数据,即系统明确询问用户哪些是被需要的数据[19]。但是这种方法并不被认为是有效的,因为用户从来没有兴趣直接给出输入,所以现在的研究更侧重于基于用户执行的某些动作来隐含分析用户数据,也可以被称为行为用户画像。已经有很多研究可供参考,我们可以确定用户画像的三个主要类型如下:
2.2.1 明确的用户画像
明确的用户画像可以解释为分析用户静态和可预测特征的过程。在这种方法中,通过分析用户的可用数据来预测用户行为。这些数据通常是通过提交在线表格或调查等方式来获得的。这也被称为静态分析或事实分析[20]。当我们只采用模糊的用户画像时,会出现一些问题,因为用户没有兴趣向任何人泄露他们的信息,因为他们担心自己的隐私或表单填写过程可能是乏味的,用户试图避免它。因此,使用这种类型的用户画像的精度会根据时间段而降低。
2.2.2 模糊的用户画像
模糊的用户画像,不是很专注于关于用户的当前信息,这种方法更多地依赖于我们在将来所知道的用户信息,即系统试图更多地了解用户。因此,这种类型的系统也被称为行为分析、自适应分析,现在更多地被称为用户的本体分析[21]。在这种分析中也使用不同类型的过滤技术。可以发现许多研究文献讨论了一些过滤技术,其中一些可能是基于规则的过滤,协同过滤和基于内容的过滤技术。
2.2.3 混合的用户画像
这种类型的用户画像结合了明确和模糊用户画像的优点。即它考虑到用户的静态特性,并且还检索关于用户的行为信息。这种方法使得分析更有效率,并保持信息随时间上更新的准确性。
表1比较了三种用户画像。
剩余内容已隐藏,请支付后下载全文,论文总字数:21821字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

