论文总字数:18901字
目 录
1.引言 6
2.相关研究与技术 7
2.1网络爬虫 7
2.1.1工作原理与分类 7
2.1.2聚焦爬虫 8
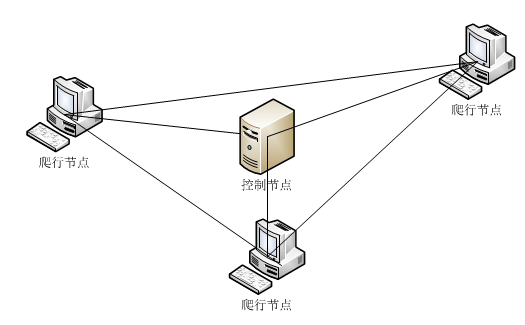
2.1.3分布式爬虫 8
2.2 Ajax动态加载 11
2.3情感分析 12
3.系统设计 13
3.1系统需求分析 13
3.2系统开发环境 13
3.3爬虫设计 14
3.3.1爬虫系统结构图 14
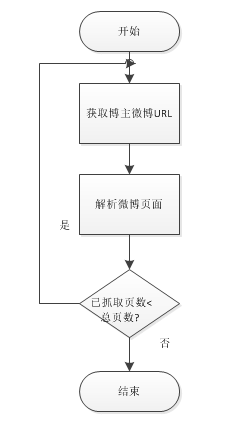
3.3.2用户微博爬虫流程图 14
3.4数据库设计 15
4.系统实现 16
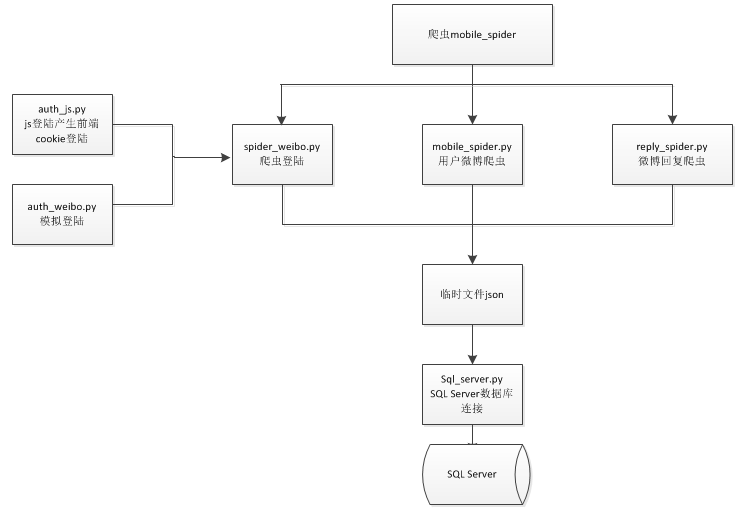
4.1爬虫实现 16
4.1.1微博登录 16
4.1.2用户微博爬虫 19
4.1.3微博回复爬虫 22
4.2数据过滤与分析 24
4.2.1数据过滤 24
4.2.2数据分析 25
5.结论 27
参考文献 28
致谢 29
气象灾害与公众安全信息的抓取与分析
周洁
,China
Abstract:Over the years,meteorological disasters have occurred frequently in China ,causing great damage to the safety of the lives and property of the public. However, the prevention mechanism of meteorological disasters in our country is not perfect yet, and depends more on the public improving the defense capability. With the rapid development of mobile Internet and We-media, the public has been able to obtain a great deal of news and information. However, the news on the Internet is massive,extensive and accessible, which makes meteorological disasters and other emergencies covered by other hot topics rapidly.Then the forecast and warning information released by the official platform fails to reach the original goal.
Therefore, this paper designs a Python-based web crawler system that collects micro-blog data from official platforms (such as China Meteorological Administration, National Emergency Broadcasting, China Daily and Xinhua, etc.) and well-known weather bloggers. The system supports Multi-threading, which can crawl reply information of the blogs released by bloggers simultaneously; The system uses SQL Server database to store micro-blogs’ data and reply information, and filters out the information of rain | haze | floods | drought | typhoon | earthquake and other weather disaster with keyword matching technology;Finally, do a data analysis on reply information. The system can effectively monitor the public opinion on to avoid public opinion crisis.
Key words: python; crawler;multithreading; meteorological disasters ;SQL Server
1.引言
21世纪以来,随着科学技术与经济的迅速发展,人类干预自然的能力和规模日益增长,导致全球气候变暖、环境污染和生态破坏,自然灾害也接踵而至。据统计,我国在近10年(2006-2015)发生的自然灾害次数是20世纪80年代的3倍[1]。
自然灾害中,气象灾害占七成。近年来,特大暴雨、超强台风、区域性严重干旱等历史罕见事件频频发生在中国的多个城市和地区。由于我国城市密集、人口密度高,每年因暴雨洪涝引发大规模的城市内涝,严重影响了公众的生产生活。同时,我国还是农业大国,这些极端天气气候事件每年造成农村耕地近2500公顷[2]的少收、绝收,提高了公众的生活成本,影响社会安定。
随着我国对气象灾害重视程度的加强,气象服务工作得到了大幅改善,无人机技术等高新技术也开始应用于灾害现场,使得受灾后死亡人数锐减。然而我国的气象灾害防御机制尚不完善,预报预警信息的发布渠道有限,多集中在报纸、电视、广播、PC端等传统媒体,覆盖面窄,传播内容套路化严重。媒体防灾减灾知识宣传力度不足,更重视报道灾害发生后的信息,诱发公众自救互救能力弱、负面情绪重等问题,导致灾情恶化。因此,增强气象部门的服务能力尤为迫切。
随着移动互联网和自媒体的迅速发展,公众能够及时获得海量的新闻资讯。然而网络新闻体量大、覆盖面广、传播速度快,使得气象灾害等突发性事件被其他热点迅速覆盖,官方气象平台发布的预报预警信息难以进入公众视野。因此,使用网络爬虫技术,及时、高效地采集气象灾害相关的网络新闻,能够迅速掌握灾情、舆情,有效地监控事态的发展,避免舆情危机。
据国内移动大数据服务商QuestMobile发布的“2016APP价值榜”显示,截至2016年12月,微博活跃用户数超过排名在第2-9位APP的总和。摩根士丹利预测,2017年内,微博的月活跃用户将达4亿。在网络社交平台领域,新浪微博保持着绝对的领先优势,为数据挖掘方面的研究人员提供了有力的数据支持。
然而新浪微博上的气象灾害热点较为分散,用户关注度不高,研究人员难以获得有效数据,导致研究分析工作的滞后。虽然新浪微博提供了免费的OpenAPI接口,但对普通的开发者仍有很大的权限限制,使开发者难以在短时间内获得海量的研究数据。因此本文设计了一个针对气象灾害的微博爬虫系统,为气象工作者提供相关数据支持。
该爬虫系统采用了两种方法登录微博,一是Selenium phantomJS,结合Xpath登录,模拟人的操作实现登录,二是用Python模拟新浪服务器的JS[3]加密流程实现登录。登录成功后,采集新浪微博中官方平台(如中国气象局、国家应急广播、中国日报和新华网等)和知名气象博主的微博数据和公众回复数据,该系统支持多线程,可同时抓取多个用户的回复信息。该系统利用SQL Server数据库存储微博和回复数据,并用关键字匹配技术,筛选出含暴雨|雾霾|洪涝|干旱|台风|地震等气象灾害关键词的微博数据;最后对回复数据做了一个数据分析。
2.相关研究与技术
2.1网络爬虫
2.1.1工作原理与分类
网络爬虫是搜索引擎[4]技术的基础。搜索引擎首先利用网络爬虫,跟踪URLs,采集Internet上的各类网页;同时分析网页结构,抽取有用的信息,再用Index给这些数据定位,构建索引数据库;然后根据用户输入的搜索字段,检索数据库,按一定的规则对检索出的数据进行排序,最后将匹配度最高的结果返回给用户。从搜索引擎的工作原理中可以看出,搜索引擎的数据采集(网络爬虫)能力决定了它信息量的丰富度和网络覆盖率。
网络爬虫[5],又被称为网络蜘蛛,是一种自动抓取Web页面的计算机程序。一般从一个种子URL集合开始,将其放入待抓取队列中,按照一定的规则,抓取URL对应的网页,分析当前页面,抽取新的URL放入队列,直到满足系统的的停止条件。
网络爬虫的分类标准有多种,从不同的角度进行分类,得到的结果也不尽相同。下面是两种普遍认可的分类结果。
- 从爬虫结构和实现技术来看,可以将网络爬虫分为以下四类:通用网络爬虫(全网爬虫),主题网络爬虫[6],增量式网络爬虫[7]和深层网络爬虫[8]。通用网络爬虫,常见于诸如百度、谷歌等大型搜索引擎以及大型网站上Web 数据的爬取分析,实现方式是从种子URL扩充到全网抓取。主题网络爬虫,针对某一特定领域和主题,爬虫工具从互联网中选择性地采集与主题相关信息,这种爬虫一般应用于特定领域。增量式网络爬虫,是指在已存储部分网页的基础上,继续爬取更新了的页面或新生成的页面,实现对数据的更新,这个过程不会对已有内容进行重复爬取,有效减少了时间和空间上的消耗。深层网络爬虫是专为无法通过普通静态链接访问Deep Web资源而提出的爬虫分类,新浪微博就属于Deep Web。
- 从爬取目标和范围来看,分为三类,分别是批量型爬虫、增量型爬虫和垂直型爬虫。批量型爬虫预先设定爬取范围和目标,达到预期目标时即停止抓取。垂直型爬虫,又称为聚焦爬虫,主题爬虫,选择性地爬取特定主题相关的页面或者属于特定领域的专业网站,以满足特定领域或背景的用户的检索需求。另外,这个分类标准把增量式爬虫和上述通用爬虫归为一类。
这两种爬虫分类的具体内容在某些方面存在一些交叉,这在实际分类过程中属于正常情况,实际的网络爬虫系统也通常是由这几种爬虫技术结合实现的。
2.1.2聚焦爬虫
随着移动互联网对社会行业结构的调整和深度挖掘,各行各业的发展趋于专业化、细分化和科学化,聚焦爬虫显然更符合这一发展趋势。下面介绍聚焦爬虫的三种爬行策略。
(1)基于链接结构的爬行策略
剩余内容已隐藏,请支付后下载全文,论文总字数:18901字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

