论文总字数:29368字
目 录
1.绪论 1
1.1课题的研究背景及意义 1
1.2国内外研究现状 1
1.3本论文研究内容 2
1.4本论文的结构安排 2
2.网页信息提取技术概述 3
2.1网页的基本结构和特征 3
2.1.1 网页信息特点 3
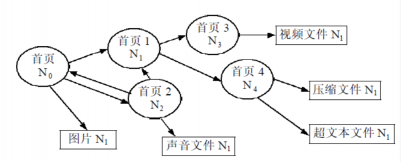
2.1.2 网页的组织结构 4
2.1.3噪声信息 4
2.2网页信息提取技术 4
2.3.1 基于正则表达式的网页信息提取技术 5
2.3.2 基于统计的网页信息提取技术 5
2.3.3 基于HMM的网页信息提取技术 5
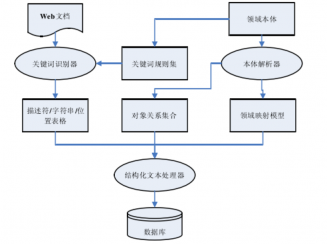
2.3.4 基于本体论的网页信息提取技术 5
2.3.5 基于网页查询的网页信息提取技术 6
2.3.6 各网页信息提取技术的比较 6
3.网页信息自动提取的网络爬虫技术 8
3.1网络爬虫的原理 8
3.1.1 爬虫的搜索策略 8
3.1.2 抓取效率的提高 8
3.1.3 数据库的定期更新 9
3.2爬虫的实现方法 9
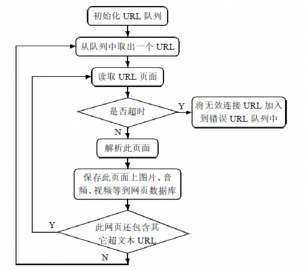
3.2.1 初始化URL队列 10
3.2.2 读取URL页面 10
3.2.3 解析URL页面 10
3.3网站爬虫的几个常见问题 11
3.3.1 重复链接 11
3.3.2 访问限制 11
3.3.3 错误链接 11
4. 豆瓣电影网页信息提取系统分析与设计 11
4.1开发工具 11
4.1.1 Python简介 11
4.1.2 Angular JS技术简介 12
4.1.3 Express JS技术简介 12
4.1.4 MongoDB简介 12
4.1.5 系统开发平台和工具 13
4.2系统需求分析 13
4.3系统设计 14
4.3.1 信息提取模块 14
4.3.2 信息检索模块 14
4.3.3 数据分析模块 14
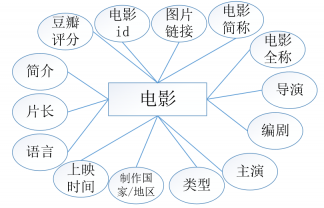
4.4数据库设计 15
4.4.1 概念结构设计 15
4.4.2 逻辑设计结构 16
5.豆瓣电影网页信息提取系统实现 17
5.1信息提取模块实现 17
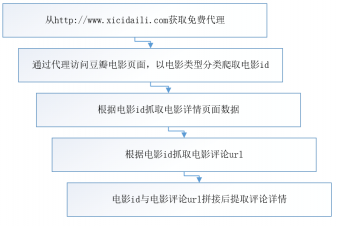
5.1.1 获取免费代理 17
5.1.2 获取电影链接 18
5.1.3 获取电影详情 18
5.1.4 获取电影评论链接 19
5.1.5 获取电影评论详情 19
5.2数据库配置 20
5.3数据展示模块实现 21
5.4信息检索模块实现 21
5.5数据分析模块实现 26
6.总结与展望 27
参考文献 27
致谢 29
网页信息自动提取技术的研究
葛妍娇
, China
Abstract: With the rapid development of Internet technology and its applications, Web has become a vast, distributed and shared information resource. Data increases exponentially, how to extract useful information from vast amounts of information has become an urgent and important topic in the field of web information extraction. The paper took the website of Douban Movie as the research object, uses the webpage extraction techniques to obtain valid information. First, it mainly employed the web crawler breadth first strategy algorithm based on the theme of the web page, ignored the meaningless short reviews, extracted the professional reviews and complete movie information, which is stored in MongoDB; Then it used JavaScript to build the page framework, displayed the top 50 films, provides genres-based, ratings range and keyword search engine, shows film types, produces and starring distribution of films in the form of statistical figures according to the analysis of information. It shows the web information extraction technology could find the useful information effectively, improve the speed of the information retrieval, decrease the noise information, which greatly meet the needs of the present users.
Key words: Web information extraction; Web Crawler; webpage of douban movie; Information Retrieval; data analysis
1.绪论
1.1课题的研究背景及意义
随着互联网技术的飞速发展和互联网在人们日常生活中的广泛深入应用,人们之间的信息传播和信息获取途径越来越多。与传统的纸质媒介不同,电子媒介的传播速度更快、传播灵活性更大,自由度更高。由于互联网信息的传递不易受到时空限制,因此,互联网逐渐获得了人们的普遍认同并得到了广泛应用,渗透到人类世界的角角落落。近几年,因特网技术飞速发展,
信息量呈指数形式疯涨,类型越来越多样化,虽然用户基本都可以在庞大的数据库找到自己所需要的信息,但是我们不能方便快捷地查找到关键信息。现在网站基本都设置了搜索引擎,它不能准确地定位到所需信息,只能缩小信息的搜索范围,搜索结果中常有许多噪声信息,用户只能不断增加关键字重复搜索,才能准确获得自己所需的信息。此外,一个信息可能涵盖多个主题,跨越多个领域,导致不同的用户对同一个信息的关注点不尽相同。因特网庞大的数据库既方便了人们的生活,但成了许多用户的困扰。如何从海量信息中提取有用信息已成为当前的网页信息提取领域亟需解决的一个紧迫而重要的课题。
把如何有目的、有选择地选取某一方面的信息的技术称为信息提取(IE,Information Extraction)技术。该技术就是定位网页中的有效信息,并将它们转化为人们可以理解、可以结构化表示的信息。网页信息自动提取技术可以精准的定位到数据库中的有效信息,提高了信息的搜索速度,减少信息的检索次数,节省了大量的时间。另外,提取半结构化数据获得的结构化信息可以被直接用于其他应用程序,完善信息搜索、数据挖掘等后续信息处理操作。
1.2国内外研究现状
信息提取技术的研究开始于对自然语言的探索,后来经过不断创新发展,成功在自然语言处理领域崭露头角,并推动了该领域的研究不断向前发展。下面是国外的几个重点研究项目。
(1)基于有限状态自动机的文本理解系统
该系统是国际斯坦福研究学会开发的,它以不确定性的有限状态自动机为基础,从自然语言文本提取网页中的结构不严谨的信息,转换成严密的结构化数据并入库,或者作其他应用。它属于纯粹的模式匹配。该系统较TACITUS(基于理解的系统)相比,它的运行速度有了大的进展、提取数据的准确率和召回率也改善了不少。基于有限状态自动机的文本理解系统通过了一系列的消息理解系列会议评测,充分显示了该系统能被灵活地应用于涉及到信息提取技术的领域[1]。
(2)文本信息统计系统
雷神BBN公司在信息提取的过程中逐步增加统计训练的分量,开发了基于HTM模型的使用统计方法的文本信息统计系统,取代了需要手写模式的PLUM模型[2]。该系统在提取句子时,句中的词语会经过词性判别、命名发现、分析和关系查找等统计过程转换成相应的语义构造。
(3)仿真软件应用系统
该系统是根据对象的语法、语义的分析结果,生成相应的模式。系统原来的语法解释器和解析器不能很好地满足用户的需求,所以系统换用有效形态模型解释对象的语法和语义。系统还添加了一个图形用户接口模块,该模块与关系联系密切,首先随机挑选几个对象作为样本,根据样本与提取引擎的交互结果,不断提取出新的关系实例,最后生成该对象所对应的模式。
国内在这方面的研究历史较短,但也形成了一些相关的研究理论成果,如:中国因特网研究院开发了一个提取实体间关系以及中文命名实体的信息提取系统[3];国立台湾大学参与了第七届消息理解系列会议,实验测试识别中文命名实体 [4]等。
国内较为典型的系统和算法有:
(l)基于预定义模式的包装器[5]:模式由用户自主定义,并确定HTML网页与模式之间的对应关系,然后根据映射关系分析用户定义模式的推导规则,同时生成包装器。
(2)基于DOM的信息提取算法[6]:它以提取信息的路径为“坐标”而设计的一种半自动生成信息抽取规则的归纳学习算法,通过该算法分析文档对象总结提取规则,依据规则生成对应的JAVA类。
(3)基于样本实例的信息抽取算法[7]:它需要用户学习页面的样本记录的标识,得出信息映射关系等规则,并把规则放到知识数据库,就可以利用知识库分析其他相似页面的提取规则,抽取数据并入库。
1.3本论文研究内容
基于网页信息提取技术的发展历史进行的回顾和总结其研究现状,分析HTML网页结构特点及已有的几个常用的网页信息提取技术,重点介绍了与网页信息提取的网络爬虫技术,设计实现豆瓣电影网页信息提取系统。主要研究内容如下:
1首先抓取电影信息,由于豆瓣限制访问,通过代理访问。
剩余内容已隐藏,请支付后下载全文,论文总字数:29368字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

