论文总字数:26541字
目 录
1. 绪 论 1
1.1 研究背景及研究意义 1
1.2 国内外研究现状 1
1.3 本文的主要工作及布局安排 2
1.3.1本研究的主要工作 2
1.3.2 结构安排 2
2. 数据挖掘 3
2.1 数据挖掘介绍 3
2.2 可挖掘数据形式 3
2.3 数据挖掘基本步骤 3
2.4 作用于自动化网络管理的数据挖掘 4
2.5 序列模式 5
2.6 数据挖掘的研究现状 5
3. 序列模式数据挖掘 6
3.1 序列模式挖掘介绍 6
3.2 序列模式的挖掘方法 6
3.3 序列模式的定义 7
3.4 序列模式挖掘算法 8
3.4.1 AprioriAll 8
3.4.2 GSP 10
3.4.3 FreeSpan 10
3.4.4 Prefixspan 12
3.4.5 4种算法比较分析 14
3.5 作用于自动化网络管理的序列模式数据挖掘算法 15
3.6 小结 15
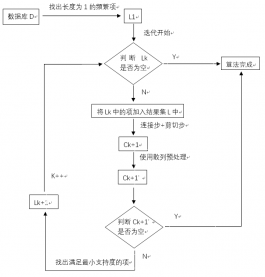
4. GSP算法 15
4.1 相关概念和定义 15
4.2 GSP算法的主要步骤 16
4.3 流程分析 17
4.4 算法实例 17
4.5 GSP算法主要问题 18
4.6 GSP算法的改进 19
4.6.1 使用散列技术预处理候选项 19
4.6.2 对事务进行压缩 20
4.7 小结 21
5. 实验及分析 21
5.1 实验平台及语言介绍 21
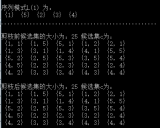
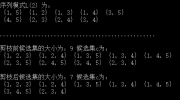
5.2 实验数据及分析 22
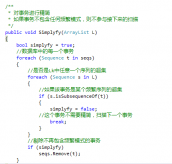
5.3 核心部分代码 23
5.4 算法效率分析 24
6. 总结与展望 26
6.1 总结 26
6.2 下一步工作 26
参考文献 27
致谢 29
应用于自动化网络管理的高效序列模式挖掘技术研究
戴晟
,China
Abstract:The successful developments of Database systems enable people to deal with things much more efficiently. And then people came up with higher demand. They hope that computer can help to analysis and comprehend the data, and then make decisions based on plentiful data. So Data mining emerges as the times require. It is the procedure that searching closet information through massive data with methods which includes gathering statistics, machine learning, On-Line Analytical Processing, Expert system, Information Retrieval, Pattern Recognition and so on. Automated Network Management is just one of the cores of. Automated Network Management is the inevitable development trend of the network which is growing bigger and more complex. And Data Mining Algorithms is just one of the cores of it. This article introduces and analyzes four main Sequential Pattern Mining Technology. Through implementation of the GSP algorithm, we analyze the shortcomings during the operation of the algorithm, and bring forward a way to improve it.
Key words:Data mining; Frequent pattern mining; GSP algorithm.
1. 绪 论
1.1 研究背景及研究意义
数据挖掘(Data mining)作为数据库知识发现中的一个关键步骤,通常指从大量的数据中自动搜索隐藏于其中的有着特殊关系性的信息的过程。数据挖掘通常作用于包含大量复杂数据的数据库系统,通过统计、情报检索、在线分析处理、模式识别、专家系统(依靠过去的经验法则)和机器学习等诸多方法完成对关键数据的检索和处理。
序列模式是数据挖掘中的一个重要研究课题。所谓序列模式,即在一组有序的数据列组成的数据集中,经常出现的那些序列组合构成的模式。不同于关联规则发掘,序列模式挖掘的作用目标以及产生的结果是有序的,也就是说数据中的每个序列都在一定规则下是有序排列的,例如时间或者空间,输出的结果序列同样如此。
由于序列模式挖掘功能的强大,使其作用领域十分广泛,因此自序列模式挖掘被提出以来,一直作为研究的热门领域。随着研究人员的不断增多,研究者对这一领域的重视程度不断加深,一大批成熟而高效的算法应运而生。应用于自动化网络管理的高效序列模式挖掘技术作为数据挖掘作用于具体领域的一个实例,可以直观的反应出序列模式挖掘技术对于实际领域的影响,十分有研究价值以及实际的应用潜力。
本课题以数据挖掘理论为基础,通过理论论述及算法实现两方面具体研究相关算法,并以实际情况针对算法进行分析。
1.2 国内外研究现状
上世纪80年代,数据库系统迅猛发展,因其存储过程简单直观、管理数据方便、数据查询系统化和数据存储量巨大等特点,迅速在各个领域得到了广泛的应用。随着记录数据量的增加,数据库系统便捷存储繁杂的数据的同时,人们也提出了新的方向:是否能将隐藏于其中的有着特殊关系性的信息提取出来。
1995年,学术界和工业界一起成立了ACM(数据挖掘、知识发现专委会),同时组织了第一届国际数据挖掘与知识发现大会。该会议每年举行,已发展成为数据挖掘领域的顶级会议。随着数据挖掘关注度的提升,每年论文提交量以及参会人数也呈现高增长趋势,以社会网络和信息网络为中心的大数据分析成为数据挖掘研究的热点。
目前,数据挖掘领域已经出现了许多十分成熟的算法,如AprioriAll、GSP、FreeSpan、Prefixspan等。国内虽然起步较晚,在科研单位和各大高等院校的带动下,数据挖掘算法也开始在各个领域得到应用。
1.3 本文的主要工作及布局安排
1.3.1本研究的主要工作
本文的主要研究内容介绍如下:
(1) 掌握序列模式数据挖掘基础理论,整理、分析数据挖掘中序列模式挖掘技术原理,对相关算法进行深入研究。
(2) 以理论知识为基础,对AprioriAll算法、GSP算法、FreeSpan算法、Prefixspan算法进行算法分析,分析算法性能。
(3) 程序实现GSP算法,分析算法运行流程,对于算法缺点提出优化。
1.3.2 结构安排
本文的结构如下:
第一章绪论部分,介绍课题的研究背景,课题国内外的研究现状以及主要工作。
第二章数据挖掘部分,介绍数据挖掘的相关概念,数据挖掘的目标以及数据挖掘的步骤,分析自动化网络管理领域中数据挖掘技术的作用,并提出序列模式的概念。
第三章序列模式挖掘概述,首先介绍时间序列、时间序列数据和数据特点、时间序列模式挖掘的概念。紧接着详细分析时间序列的四种常见算法:AprioriAll算法、GSP算法、FreePan算法、PreFixspan算法。
第四章算法,介绍了GSP算法的相关概念,介绍了GSP算法的步骤,并以伪代码和实力结合的方式介绍了GSP算法挖掘的流程。最后对GSP在实际应用中的缺点进行了分析,并根据缺点提出了相关的优化。
第五章实验及分析,这部分交代算法实现基于的平台及语言,以及实验测试数据和测试结果。
第六章总结和展望,主要是对整篇论文做一个概述性质的总结,并说明进一步要做的工作。
2. 数据挖掘
2.1 数据挖掘介绍
1995年8月,在加拿大蒙特利尔举办了第一届以在数据库中发现知识为主题的ACM会议。自此,数据挖掘逐渐兴起,成为近年来的一大热门领域。
数据挖掘通常与另一个词一同提起,知识发现(KDD),可以被定义为在数据库中,数据仓库中,WEB,或是数据流中,自动的提取出暗含的知识的过程。与统计学不同,数据挖掘并不是为了验证某一假设或是估计模型的参数而从数据库中搜索特殊的数据。它采用的数据并不一定是为了定量分析而生成的,通常是一些系统运行后留下的历史操作记录。
2.2 可挖掘数据形式
数据挖掘是一种通用的技术,可以作用于任何可以产生有兴趣信息的数据。挖掘的数据形式,大致可分为数据库数据,数据仓库数据和事务数据。
关系数据库由大量的表组成,表中以属性为单位存储着一系列的数据。表之间蕴含着不同的关系,代表着各个实体间的关系。不同表之间的不同关系构造成了一整个关系数据库。对关系数据库进行挖掘时,可以发现如实体间隐含的联系,事务的发展趋势,分析商品热度等等,也可以对偶发的事件进行分析,预测发生的频率以及发生的事件与其他事件的联系等等。
数据仓库是由多个数据源存储于同一位置后集合而成的存储模式。与关系数据库可以利用Sql语句灵活操作不同,数据仓库更像是一个存储的单位,只关心以何种形式存储各类数据,同时对外只提供数据的查询。当有改动发生时,数据仓库不会覆盖掉原有的数据,而是将改动的部分以新记录的形式增加到历史记录之上。数据仓库中的数据通常表现为数据立方体,即以多种维度的形式展现数据,因此数据挖掘作用于数据仓库时将采用多维度并行挖掘的方法,以OLAP的方式组合挖掘,更有效挖掘全部数据的同时,更易于发现数据不同组合中蕴含的模式。
事务数据直观的表示出每一个事务发生的过程,例如一个顾客购买商品的事务数据,由两个属性构成:顾客ID,以及购买商品的目录。每一条事务即表示着一个顾客一次消费过程中购买的商品。作用于事务数据的数据挖掘可以寻找出事务间的关系,如序列模式等。
2.3 数据挖掘基本步骤
剩余内容已隐藏,请支付后下载全文,论文总字数:26541字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

