论文总字数:23261字
目 录
I. 绪论 1
1.1 研究背景及意义 1
1.2 图像检索的概述 2
1.3 国内外研究现状 2
1.3.1 图像检索的国内外研究现状 3
1.3.2 感知哈希的国内外研究现状 4
1.4 研究内容及章节架构 4
1.4.1 本文研究内容 4
1.4.2 本文的章节架构 5
II. 图像检索的基本理论及其相关技术 6
2.1 图像检索的基本框架 6
2.2 图像检索的评价标准 7
2.3 感知哈希的基本概念 7
2.4 本章小结 9
III. 基于感知哈希的图像检索算法 10
3.1 图像检索系统设计 10
3.2 图像局部特征提取 10
3.3 基于BOF的全局特征向量 14
3.3.1 词袋模型 14
3.3.2 K-means聚类方法 15
3.4 特征哈希 16
3.5 本章小结 16
IV. 基于MATLAB的系统实现 17
4.1 系统实现 17
4.2 检索精度 20
V. 总结与展望 25
5.1 论文总结 25
5.2 未来展望 25
参考文献 25
致谢 26
基于感知哈希的图像检索算法研究与实现
沈磊
,China
Abstract:With the popularity of the Internet, information technology, upgrading of social media week and image capture device, and now the emergence of a large amount of image information on the Internet, we become an integral part of everyday life. Image information can be more vividly visual information to the public, to help you build a more vivid way of thinking will help us to learn and think. Therefore, the image information has become our understanding, learning a big help.
The current image retrieval according to the principle, is based on the text and content based image retrieval, both which generally includes three aspects: first, according to the image retrieval needs analysis, establish index; second, using the algorithm of image feature point extraction, establish the index of the image database; finally, according to the similarity algorithm will be retrieved images and index database records the size of the similarity, according to a particular algorithm results as a result of the output. In the algorithm research. First of all, the SIFT image feature points and the descriptor computation; then use the K-means clustering method of the feature points is trained to generate the type of heart; is then generated for each image of the bag of words (bow); then the bow of each image was calculated mean values and compares the hash values are generated; finally, calculate the similarity of the results obtained with the Hamming distance. In this study, we refer to the surf algorithm and K-means clustering method, based on BOF the global feature vector, the Hamming distance and so on.
Through the research of this paper, we propose and plan to implement an algorithm that can enable us to perform image retrieval function efficiently in our daily life. However, there are still a lot of unknowns to explore, improve and study, considering the performance of the image retrieval system. I hope I can devote more time to understand and study the image retrieval in the future.
Key Words: Internet; Perceptual Hashing; Image retrieval; SURF algorithm; BOF model set
绪论
这些年来,随着多媒体技术及互联网技术的高速发展,平民大众使用现代化智能设备越来越普及,进而导致产生了大量爆炸式的数字图像数据信息。图像在日常生活中包含了丰富的内容信息,具有直观、形象的特点,贴近人们认知世界的方式,因此以图像为输入信息,从海量的数据库中进行检索所需要的信息得到了越来越广泛的应用。因此,对于图像检索的研究在实际生活中具有重要的理论价值和商业用途。
研究背景及意义
随着数据库系统和计算机视觉技术的成熟,21世纪已成为一个大数据信息时代,传统的数据分析明显已经无法跟上时代的潮流。图像成为人们生活中必不可少的元素的同时,如何快速进行图片的检索成为现今人们研究的课题。
如今,Web 3.0已渗透到人们的生活之中。互联网技术的日新月异,各种社交网站及APP已经彻底改变了人们对生活的一种认知方式。由于图像具有直观、形象的特点,人们开始用图片记录自己的生活,并利用社交平台在互联网分享自己的动态。据社交搜索引擎Statista的数据分析表明(如图1-1所示[1]),自2010年起,Facebook上分享的图像超过了7000亿张;截止到10年,flickr这个网站上的图像已突破了50亿张,并仍以10亿/每年的数量递增(如图1-1);而Twitter分享的图像的增长率达到了421%,仅12月用户进行上传分享的图片就多达5840万张。
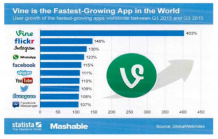
图1-1 Statista研究数据展示
从上面的数据信息,我们能够看到图像信息在带给人们生活便利的同时,也导致了互联网上图片信息的泛滥,造成了图像灾难,给信息资源的管理遗留下一大隐患。因此,大数据时代下我们所需要解决的问题,就是能对图像数据信息进行一种归类,再使用高效简洁的检索方式去获得我们所需要的图片。
图像检索的概述
图像检索,顾名思义,当我们需要对一张图像进行查询的时候,找到与该图像相同或相似的图像信息。从上个世纪70年代开始,人们才开始将重点放在如果从大量图像中检索到自己所需要的图像[2]。到目前为止,图像检索的技术大致分为两大阶段:1)基于文本的图像检索[3];2)基于内容的图像检索[4]。
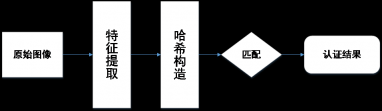
基于文本的图像检索简称为TBIR。它避免了对图像可视化元素的分析,人工对图像进行关键字的标记,同时把这些关键字作为主要依据存入数据库中。当进行图像检索时,使用关键字的查询实现对图像的检索。然而,这种方法由于需要人工进行标记,带来了繁琐浩大的工程量;并且人类认知事物的主动性,难以解决不同人对于同一图像理解不同而带来标注不同的问题。因此,到了上个世纪90年代,研究者们提出了基于内容的图像检索(简称为CBIR)。通过对图像的视觉特征的提取,如颜色、纹理、状态等方面,然后利用这些特征点来匹配相似度接近的图像。CBIR一般都会有可视化界面来与用户进行交互,使得检索构造和结果显示更直观。图1-2则是基于内容的图像检索的一般框图

图1-2 基于内容的图像检索的一般框图
剩余内容已隐藏,请支付后下载全文,论文总字数:23261字
相关图片展示:


该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

