论文总字数:29638字
目 录
摘要………………………………………………………………………I
关键字……………………………………………………………………I
Abstract…………………………………………………………………II
Key words…………………………………………………………………II
1 技术简介 ………………………………………………………………1
1.1 Scrapy网络爬虫简介……………………………………………………………………1
1.1.1 网络爬虫简介 ……………………………………………………………………1
1.1.2 Scrapy简介 ………………………………………………………………………1
1.1.3 Scrapy框架结构及工作原理……………………………………………………1
1.2 Anaconda简介……………………………………………………………………………2
1.3 Jupyter Notebook简介…………………………………………………………………2
1.4 MySQL数据库简介………………………………………………………………………2
1.5 机器学习简介……………………………………………………………………………2
1.6 Scikit-learn简介…………………………………………………………………………2
2 Scrapy网络爬虫在收集APP特征数据中的应用……………………3
2.1 确认需求…………………………………………………………………………………3
2.1.1 目标网站选择…………………………………………………………………3
2.1.2 APP特征选择……………………………………………………………………3
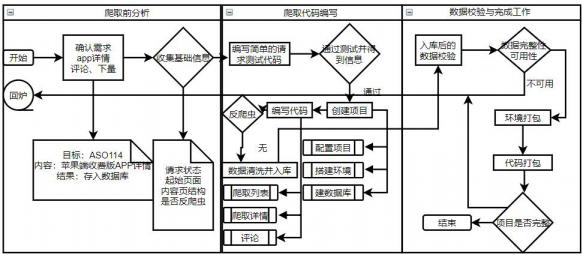
2.2 爬取流程……………………………………………………………………………………4
2.2.1 爬虫设置settings.py…………………………………………………………5
2.2.2 爬虫数据抽取(例举)…………………………………………………………5
2.2.3 爬虫数据清洗items.py…………………………………………………………5
2.2.4 爬虫数据入库pipelines.py……………………………………………………6
3 MySQL数据库表结构…………………………………………………6
3.1 info表……………………………………………………………………………………6
3.2 getcomment表……………………………………………………………………………6
3.3 downnumber表……………………………………………………………………………7
3.4 comment表………………………………………………………………………………7
4 基于SVM的分类模型…………………………………………………8
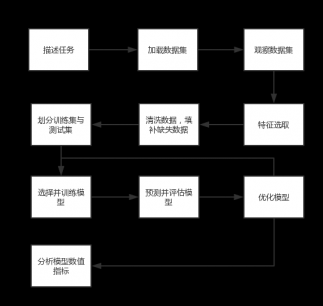
4.1 数据挖掘的基本步骤……………………………………………………………………8
4.2 APP分类任务描述………………………………………………………………………8
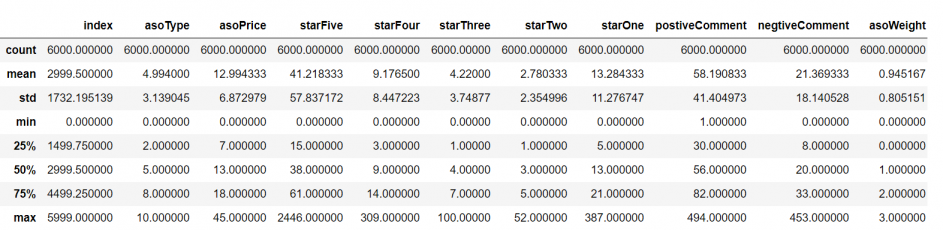
4.3 加载并观察数据集………………………………………………………………………9
4.3.1 Python数据处理库使用…………………………………………………………9
4.3.2 数据特征描述………………………………………………………………………9
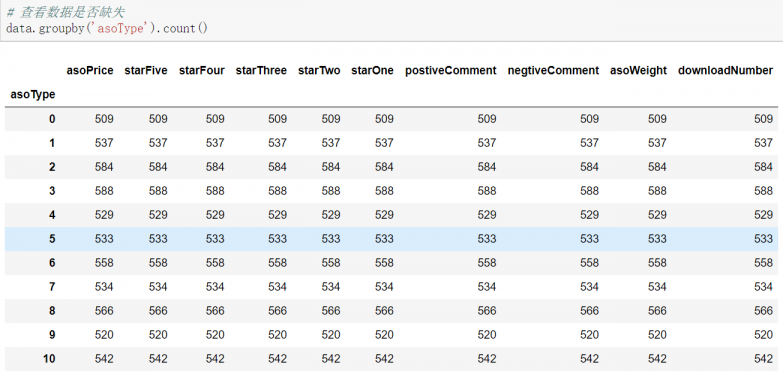
4.3.3 数据完整性保障…………………………………………………………………10
4.3.4 原始数据清洗……………………………………………………………………11
4.3.4.1 处理类别意义特征………………………………………………………11
4.3.4.2 检测并去除数据集data中的异常离群点………………………………11
4.3.4.3 扩充数据集数据…………………………………………………………13
4.4 数据特征预处理——规范化……………………………………………………………13
4.5 划分训练集与测试集……………………………………………………………………14
4.5.1 交叉验证法………………………………………………………………………14
4.6 SVM支持向量机分类方法………………………………………………………………14
4.6.1 SVM模型机制……………………………………………………………………14
4.6.2 SVC的实现…………………………………………………………………………15
4.6.3 SVC模型应用………………………………………………………………15
4.6.3.1 模型输入…………………………………………………………………16
4.6.3.2 性能度量…………………………………………………………………16
4.6.3.3 训练模型…………………………………………………………………16
4.6.3.4 寻找最优参数……………………………………………………………19
5 基于XGBoost的回归模型……………………………………………20
5.1 XGBoost介绍………………………………………………………………………………20
5.2 XGBoost在预测APP下载量中的应用…………………………………………………21
5.2.1 任务描述、数据收集与数据清洗………………………………………………21
5.2.2 XGBoost的参数……………………………………………………………………21
5.2.2.1 通用参数…………………………………………………………………21
5.2.2.2 booster参数………………………………………………………………21
5.2.2.3 学习目标参数……………………………………………………………21
5.2.3 训练模型…………………………………………………………………………22
5.2.4 预测下载量并显示预测结果……………………………………………………23
5.2.5 XGBoost回归器性能评估………………………………………………………23
6 结论……………………………………………………………………24
7 讨论……………………………………………………………………25
参考文献…………………………………………………………………26
致谢………………………………………………………………………28
手机APP特征数据收集与挖掘
蒋伟光
,China
Abstract:In order to predict user evaluation and usage of mobile phone APP, the graduation design is expected to use ASO114 (China professional APP promotion platform) of the relevant data, using currently popular scrapy framework, using the python language, the anaconda, currently the most popular open source python distributions) of virtual environment crawl related characteristics of the APP you will be able to access data, and will crawl to the data stored in the mysql database.Next, the data collected is analyzed and cleaned to obtain the effective features.Then, using sklearn machine learning repository, using the SVM and XGBoost forecast data set and the classification, and carries on the analysis and evaluation of the effects of different model, finally it is concluded that the pros and cons of different models and specific usage scenarios.
Key words:Data mining; scrapy crawler; mysql database; machine learning model; model numerical index analysis .
- 技术简介
- Scrapy网络爬虫简介
- 网络爬虫简介
- Scrapy网络爬虫简介
网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称为网络蜘蛛或者或网络机器人。大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或者企业也可以利用爬虫收集对自身有价值的数据。
一个网络爬虫程序的基本执行流程可以总结为如图1-1的循环:

图1-1 网络爬虫基本执行流程图
如图1-1所示,首先网络爬虫将所需要爬取的页面下载下来,然后提取下载的页面中的所需要的数据,接下来提取该页面中接下来需要爬取的网页的链接,然后重复执行上述过程。
- Scrapy简介
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试[1]。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
- Scrapy框架结构及工作原理
Scrapy框架的结构以及工作原理如图1-2所示:

图1-2 Scrapy框架结构
首先,Scrapy Engine从Scheduler中取出一个链接(URL)用于接下来的抓取,然后,把URL封装成一个请求(Request)传给Downloader,接着,Downloader将资源下载下来,封装成Responses,然后Spiders解析Responses得到Items,交给Items Pipeline进行下一步处理,如果解析出来的是链接,那么就把链接转交给Scheduler等待处理[2]。
- Anaconda简介
Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
- Jupyter Notebook简介
Jupyter notebook [3]是一种 Web 应用,能让用户将说明文本、数学方程、代码和可视化内容全部组合到一个易于共享的文档中。Notebook 已迅速成为处理数据的必备工具。其已知用途包括数据清理和探索、可视化、机器学习和大数据分析。
- MySQL数据库简介
MySQL是一种DBMS,即它是一种数据库软件。MySQL优点有如下四点:第一,MySQL的成本低,并且开放源代码,一般都可以免费使用甚至免费修改。第二,MySQL性能好,执行效率很快。第三,MySQL适用范围广泛,很多大型公司都使用MySQL处理自己的重要数据。第四,MySQL的安装使用非常容易。
- 机器学习简介
机器学习是一门既“古老 ”又“新兴 ”的计算机科学技术,隶属于人工智能研究与应用的一个分支。机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。在计算机系统中,“经验 ”通常以“数据 ”形式存在,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型 ”(model)的算法,即“学习算法 ”(learning algorithm)。有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时,模型会给我们提供相应的判断,机器学习可以说是研究关于“学习算法 ”的学问。以下引述美国卡耐基梅隆大学机器学习研究领域著名教授Tom Mitchell的经典定义来阐述机器学习理论。它的大致翻译如下:如果一个程序在使用既有的经验(E)执行某类任务(T)的过程中被认定为为是“具备学习能力的 ”,那么它一定需要展现出:利用现有的经验(E),不断改善其完成既定任务(T)的性能(P)的特质[4]。
- Scikit-learn简介
Scikit-learn也简称sklearn,是机器学习领域当中最知名的python模块之一.Sklearn包含了很多种机器学习的处理工具,例如:Classification分类模型、Regression回归模型、Clustering非监督分类模型、Dimensionality reduction数据降维方法、Model Selection模型选择以及Preprocessing数据预处理功能[5]。
- Scrapy网络爬虫在收集APP特征数据中的应用
- 确认需求
- 目标网站选择
- 确认需求
ASO114(https://aso114.com/)是国内专业的APP推广平台,深受百万移动开发者的喜爱,平台独家提供苹果ASO优化和安卓ASO优化支持,ASO114是国内首家ASO培训源头技术服务公司和APP推广平台。
- APP特征选择
以下为选取的app特征数据(以网页图片形式展示,方框内为选取的特征),如图2-1所示:

图2-1 APP特征选择图示
剩余内容已隐藏,请支付后下载全文,论文总字数:29638字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

