论文总字数:20773字
目 录
1绪论 1
1.1课题研究背景及意义 1
1.2文本特征选择的研究现状 1
1.2.1 国外研究现状 2
1.2.2 国内研究现状 2
1.3论文的组织结构 3
2社交网络文本特征选择方法综述 3
2.1 社交网络文本特点 3
2.2 社交网络文本常用特征 4
2.3社交网络文本常用特征选择方法 5
2.3.1 基尼指数特征选择法 5
2.3.2 信息增益特征选择法 6
2.3.3 文本证据权特征选择法 6
2.3.4 文档频数特征选择法 7
2.3.5 卡方检验特征选择法 7
2.4 本章总结 8
3基于互信息的文本特征选择算法及其改进 8
3.1传统互信息文本特征选择算法描述 8
3.2互信息特征选择的缺点 9
3.3针对互信息特征选择过程的改进 10
3.3.1 平衡权重属性因子 10
3.3.2 特征差异因子 10
3.4本章总结 11
4常用文本分类算法及评价指标 11
4.1 SVM分类算法 11
4.1.1 SVM算法原理 11
4.1.2 SVN优点与缺点 13
4.2 KNN分类算法 14
4.2.1 KNN算法原理 14
4.2.2 KNN优点与缺点 15
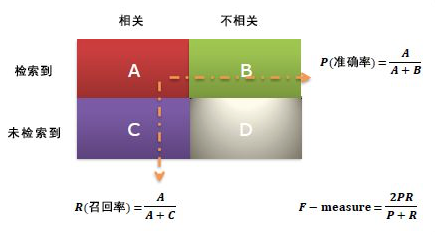
4.3 常用文本分类评价指标 15
5社交网络文本特征选择效果比较及结果分析 16
5.1实验思路与评价指标 16
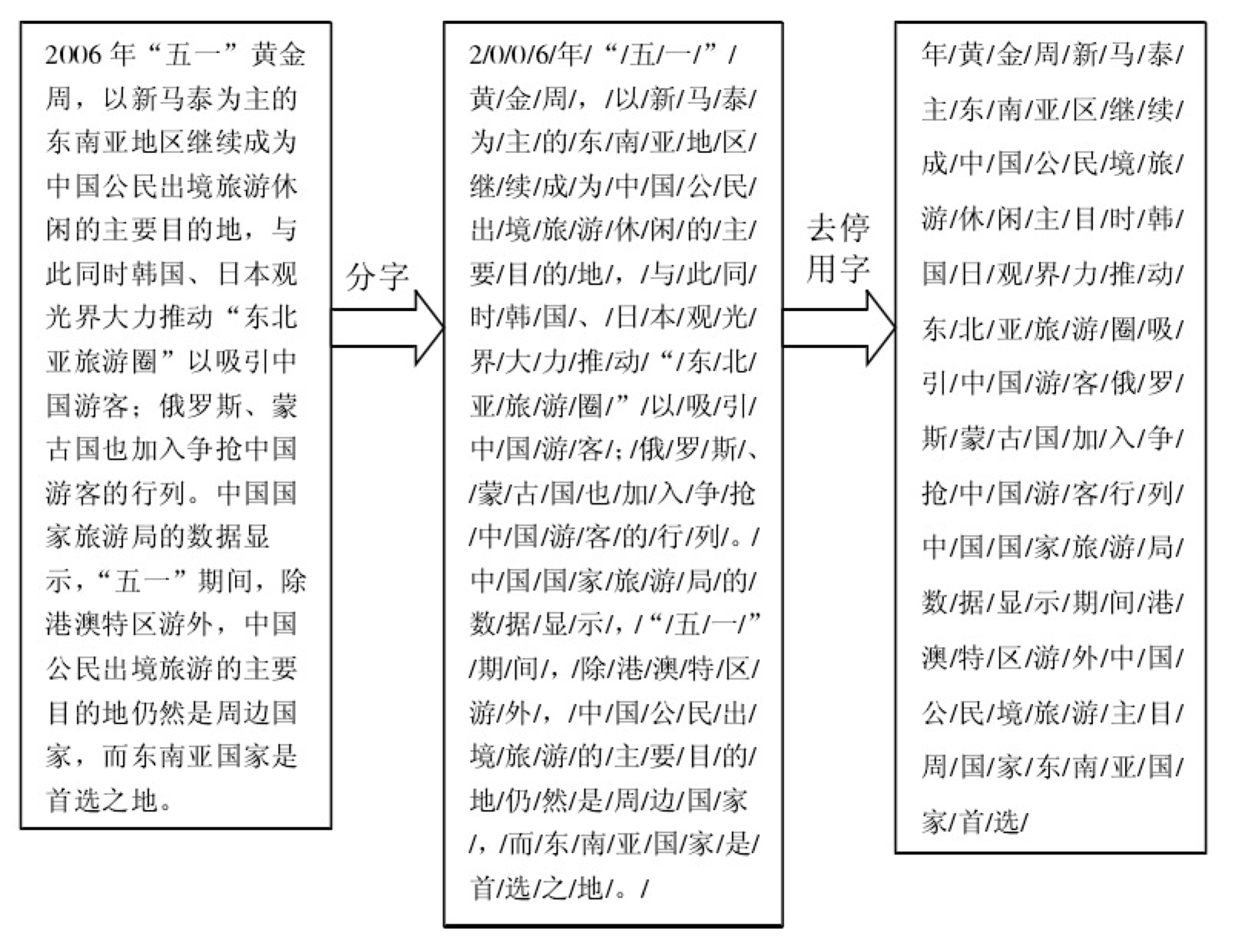
5.1.1 分词处理 16
5.1.2 去停用字词 16
5.1.3 文本的特征加权表示 17
5.2实验环境 18
5.3实验结果分析 19
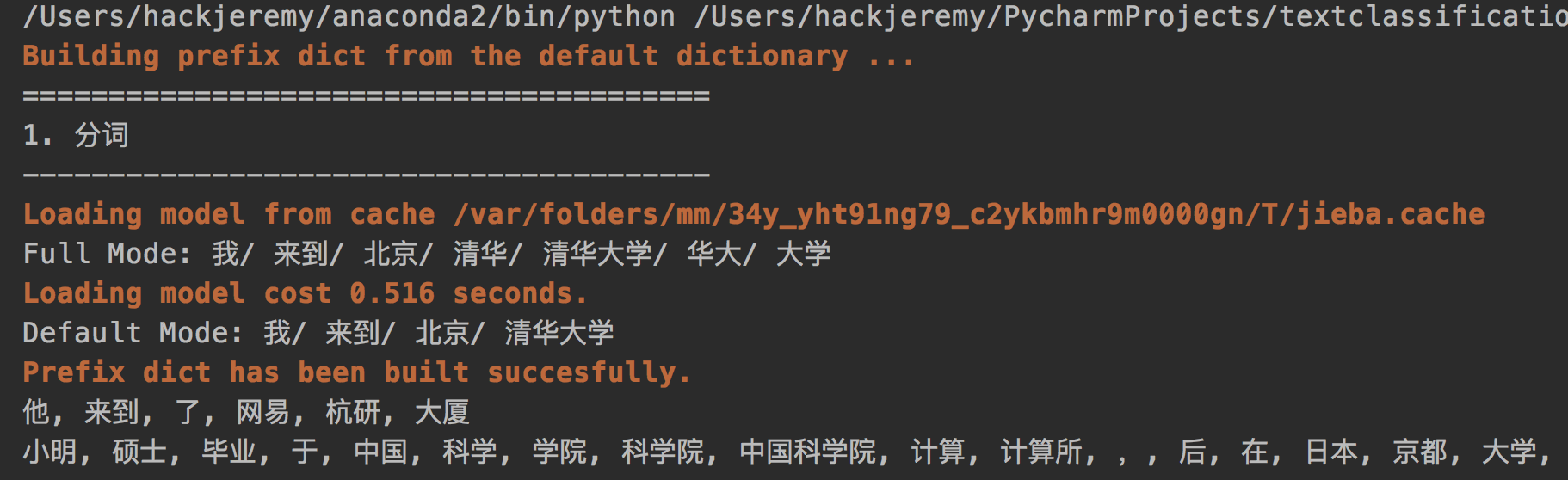
5.3.1 中文分词与转码 19
5.3.2 特征选择算法对比 20
5.4 本章总结 21
6总结与展望 21
参考文献 22
致谢 24
社交网络文本特征提取方法研究
周抒
, China
Abstract: The development of various applications based on social network text is in full swing. Studying text features and classifications is of great value to extract important information. This paper mainly introduces the common feature selection algorithms and feature representation methods, and introduces the basic principles, advantages and disadvantages of SVM and KNN, and the evaluation indexes of classification algorithms.
In the aspect of mutual information feature selection function, it describes its processing flow, shortcomings and optimization improvements. In view of its weakness in not balancing the positive and negative correlation characteristics, a balance weight attribute factor and feature difference factor are introduced to make up for its deficiency.
The experimental stage mainly describes the specific process: the word segmentation processing, to disuse words, using various feature selection algorithms, including optimized mutual information, and weighted with TF-IDF. Under the two classification algorithms of SVM and KNN, we compare the merits and demerits of all the feature selection algorithms according to the evaluation index. Experiments show that the optimized mutual information feature selection has good performance and is better than KNN under the SVM classification algorithm. This experiment proves its validity.
Key words:social network text;mutual information;positive and negative correlation characteristics;svm;knn;
1绪论
1.1课题研究背景及意义
至2018年,互联网的发展历程已经经历了几十年,但是这几十年的发展给各个地方带来了许多的变化。这些变化使得人们交流便利,人与人之间的距离越来越近。中国移动互联网的市场总体规模也在不断增大。
如今,各种电子商务、区块链、人工智能如火如荼。而其中仍然社交网络呈现出一种爆炸式的火热,如国内的微博、国外的Twitter。这些类似微博客类的应用使得信息传播十分方便,同时里面还包含了大量的视频信息,使得文本信息内容更加丰富多彩。
电子商务、社交网络平台(如微博、Twitter、Facebook)、搜索引擎,这些主体具有许多的文本数据。其中,电子商务平台具有大量商品的信息,对商品的评价、具体信息描述。社交网络平台(如微博、Twitter、Facebook)上具有大量的评论信息,与电子商务商品信息不同的是,这些信息往往具有较短内容。所有的这类信息我们把之成为社交网络文本。
因此,这些社交网络文本在各种交流过程中起着很大的作用,它的特点是文字少、特点鲜明,具有重要的研究意义。曾几何时,新浪微博与腾讯微博争夺市场,经过几年的厮杀,目前市场上存留的是新浪微博,后改名为微博。而电子商务市场,阿里巴巴、京东、苏宁等几分天下,其中目前市场最大的是属于阿里巴巴旗下的淘宝。
面对这些电子商务平台、社交网络平台等产生的大量社交网络文本,准确提取重要合理信息是关键。列如对于出现的正负向社交网络文本信息,社交网络文本分类占有着较高的地位。社交网络社交网络文本分类的研究使得对于后续工作,如文本描述、文本数据挖掘等都具有重要意义。
本文结合社交网络文本的文本特点,对其已经存在的问题展开研究讨论,分析不同信息特征提取对其影响的精确度。
1.2文本特征选择的研究现状
什么是社交网络社交网络文本特征选择?简单的说,在一个具体的社交网络特征选择体系中,将指定的社交网络文本进行单独分到若干个类别的过程。社交网络文本特征选择对数据挖掘、信息处理等有着重要的研究价值与应用价值。社交网络文本特征选择可以较快地处理好各种庞大信息,在各种信息处理领域都有着较多的研究价值。
在早期社交网络文本特征选择中,主要分为两种类型。第一种便是手工特征选择,它主要是先根据已有的规则,由这些规则的特性进行手工特征选择。第二种便是自动特征选择,自动特征选择主要是在每个类别定义若干个具有各自特点的规则,主动的把具有这些特点的文本划分到对应项。
随着人工智能的不断发展,现代社交网络文本特征选择已经越来越成熟了,在电子商务、社交网络平台等搜索方面特别显著。在这些平台的搜索,往往会结合当时最火热的商品、点击率最高的文本等,特别是在搜索领域着有建树的百度,诸如搜索“2018年中国国家领导人是谁”,此时与之问题最匹配的答案便是“习近平”。
1.2.1 国外研究现状
在社交网络文本特征选择与特征选取这一块领域,国外起步比较早,国内起步稍晚。国外起步最早可以追溯到二十世纪五十年代,主要可以分为3大种类:第一种类是对文本自动特征的选择的可以进行正确性的设计规划研究工作,第二种是基于第一种的实验性测试与研究,第三种是基于文本自动特征选择的实际应用场景落地化研究。
1979年,van总结了信息检索领域的研究成果,此后,直到1989年,基于人工手动撰写的特征规则形成的特征方法在社交网络文本特征选择中占很大比重,时间推后到九十年代,网络时代浮现苗头,社交网络文本特征选择首次引进了基于线性核函数的向量机方法[1]。
随着这项技术的不断更新,越来越多的特征选择模型和算法诞生,这些技术都被广泛的运用到了如今的信息处理中。国外相关学者自然是步入其中,对网络信息资源自动特征选择展开了深入性的研究。
近期,新生的社交网络文本特征选择方法有整体文本归类的社交网络文本特征选择方法、多种特征选择方法和对经典特征选择方法做出改进的特征选择方法。
1.2.2 国内研究现状
社交网络文本自动特征选择研究方面的技术,国内最早由候汉清在1981年提出,他对文献特征选择在计算机中的相关应用进行了研究,其中包括文本自动特征选择技术和社交网络文本特征选择搜索等技术方向的情况。在这之后,文本自动特征选择研究技术在国内迅猛发展,大批学者对此展开了系统性的研究。由于国外在文本自动特征选择方面的研究起步较早,所以国内学者最初的研究文本是以英文单词为载体进行专门研究,随着后来中国学者对相关的特征选择算法等技术的不断改进,社交网络文本也已经能够进行文本自动特征选择,最终,形成了较为系统性的社交网络文本自动特征选择研究技术。
朱兰娟等人于1986年开发了具有可操行性的文本文档特征选择系统[2];吴军等人在1995年开发了以中文为载体的面向文本的特征选择系统;张月杰等人在1998年提出自动特征选择系统是可以通过计算机具有的类别特点和文本之间所有含有的特点[3],对这两个进行较大关联的设计;邹涛等人随后便在1999年开发出中文技术社交网络文本特征选择系统[4],提出了采用向量空间模型和基于统计的特征词提取技术。
国内的学者不光是对社交网络文本特征选择系统进行了不断地升级和改进,对社交网络社交文本特征选择算法也是进行了深入的研究,黄萱菁等人提出了一种独立于语种的社交网络文本特征选择模型,这种社交网络文本特征选择模型是基于机器学习的[5];周永庚等人研究了社交网络文本处理中有关隐含语义检索的应用;张剑等人研究出了基于一种词向量的神经网络[6];朱婧波等人提出基于知识的社交网络文本特征选择方法,这种方法把相关知识用作文本特征,将其使用在社交网络文本特征选择中。时至今日,社交网络文本自动特征选择技术已逐渐成熟,许多研究成果已经得到了广泛的应用。
剩余内容已隐藏,请支付后下载全文,论文总字数:20773字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

