论文总字数:24212字
目 录
1介绍 1
1.1研究背景和目的 1
1.2论文主要内容 2
1.3论文的组织结构 2
1.4本论文的主要研究内容及成果 2
2 预备知识 3
2.1 Python语言 3
2.2深度学习 3
2.2.1研究现状 3
2.2.2深度学习概念 3
2.2.3卷积神经网络 5
2.2.4全卷积神经网络 6
3 基于深度学习的视频显著性检测方法 8
3.1静态显著性检测方法 8
3.2动态显著性检测方法 10
4 实验设计及结果分析 13
4.1 实验准备 13
4.2实验方法 13
4.2.1分割视频原理 13
4.2.2训练静态显著性测试 13
4.2.3 视频分割功能测试 15
4.2.4 静态图片显著性检测功能测试 15
4.2.5 动态图片显著性检测功能测试 16
4.2.6 静态和动态显著性比较 17
4.3 实验数据比较 18
5 总结 20
5.1工作总结 20
5.2不足与展望 20
附录 22
致谢 25
基于深度学习的视频显著性检测研究
严雅夕
,China
Abstract: At the current environment surrounded by big data, to acquire effective data from videos by computer can avoid excessive visual information. However, the traditional video saliency detection methods are limited to computation speed on optical flow, lots of capacity of computation is wasted. Under such circumstance, this paper proposed a new deep learning method to effectively detect the salient part of video. This model is in order to solve two problems:1) The models of deep learning on video saliency detection is lack of sufficient pixel-wise annotated video data;2) Video saliency can finish training and detection rapidly. Under the foundation of fully convolutional network, dynamic saliency model combined with static saliency model can be derived to new one which can be used to generate temporal-spatial inference.
Key words: Deep learning; Video saliency; Salient object detection; fully convolution network
1介绍
1.1研究背景和目的
最近,使用深度学习的显著性检测引起了大量学者的研究兴趣。其越来越受欢迎的原因在于这些模型在诸如分割图片,检测对象处理,将视频汇总,压缩等许多视觉任务中取得了显著效果。显著性模型大致可以分为两类:人眼注视点预测或显著物体检测。根据输入的类型不同,它们可以进一步分为静态和动态显著性模型。静态模型将静态图像作为输入,而动态模型使用视频序列作为输入。
深度学习这一技术是目前在人工智能、机器学习等研究领域异常火爆的研究方向,受到了学术界和工业界的广泛关注。深度学习已经在语音识别、图像处理、自然语言处理等领域取得了很多突破性进展,对学术界和工业界产生了深远的影响。在深度学习方法中,有一种方法叫做卷积神经网络(CNN),其在图像显著性上表现优异。CNN在计算机视觉领域的成功很大程度上归功于数据集中大量被标记图像的可用性,但是现有视频数据集太小,无法为CNN提供足够的训练数据。 当前研究中所使用的ImageNet[1]数据集和其他经常采用的视频对象分割数据集,包括FBMS[2],SegTrackV2[3],VSB100[4]和DAVIS[5],很难与ImageNet数据集相当,无论是在质量上还是数量上。一方面,考虑到同一个视频剪辑出的帧与帧之间的高度相关性,现有视频数据集远远不能满足视频显著性对象检测等像素级视频应用训练CNN的需求;另一方面,目前来说,创建这样一个大规模的视频数据集通常是不可行的,因为标记视频的过程十分复杂并且耗费时间。因此,本文提出了一种能够大量生成带标签的视频训练数据的方法,使其易于访问和快速生成并产生接近逼真的视频,可以呈现各种运动模式,同时标记和光流可以自动生成。这些自动生成的视频的实验结果清楚地验证了本文设计的实用性。
与现有视频显著性模型相比,本文的深度学习视频显著性检测模型计算效率更高。检测物体显著性是许多图像分析任务中的关键步骤,因为它不仅识别视觉场景的相关部分,而且还可以通过滤除场景的无关部分来降低算法的复杂度。
近年来,许多计算机视觉应用中已经提出了一些视频显著性检测模型,如视频分割和视频重定时。但时间效率则成为现有视频显著算法适用性的常见瓶颈,大部分计算力用于光流计算。另外,从动态场景学习出深层网络的角度来看,很多方案以光流为输入将造成高昂的计算开销。
为此,本实验展现了一个提高效率且效果显著的视频显著性模型,摆脱了以往昂贵的光流估计问题。跟动作检测等高级视频应用不同,视频显著性是从视频帧的短期分析中获得相应信息。因此,本实验通过从对帧的深度学习来直接捕获时间显著性,而不是使用长视频信息,比如来自若干个相邻视频帧的光流。同时,在GPU上实现2fps(包括所有步骤)的帧速率。 因此在速度和准确性方面都是实用的视频显著性检测模型。本实验提出了一种基于深度学习的生成视频数据的新型培训方案,明确利用现有的丰富的图像数据集,静态和动态显著性信息被编码成统一的深度学习模型,计算方法效率很高,相比于动态场景中的传统视频显著性模型和其他深度学习网络也在速度上有了更多提高。
1.2论文主要内容
本课题主要是研究基于深度学习的视频显著性检测,内容主要包括:
- 深度学习的研究现状及相关概念。
- 卷积神经网络和全卷积神经网络之间的联系和区别。
- 动态显著性检测的方法。
1.3论文的组织结构
第一章是论文的介绍部分。这部分先对本课题的背景进行了概述,介绍显著性检测和深度学习的发展情况,然后对静态显著性和动态显著性进行了说明和相关介绍,并阐述一种既有效又高效的视频显著性模型。
第二章是相关工作。介绍基于深度学习的视频显著性检测的需求,然后对Python语言,深度学习进行了简要描述。
第三章是基于深度学习的视频显著性检测原理的介绍,包括分割视频原理、静态显著性检测原理、动态显著性检测原理。
第四章介绍了实验的运行环境和具体测试情况,包括了本文所提到的方法的实验结果以及和其他方法的比较。
第五章总结,总结了本次研究的成果以及存在的不足,并对深度学习及显著性算法的将来提出了展望。
第六章为参考文献。
第七章是附录,附上本次实验所用到的主要代码。
最后是致谢。
1.4本论文的主要研究内容及成果
本论文提出了一种新的图像集生成方法,使用了图像集合和视频切片来产生更大的数据集,提供给深度网络模型使用。之后,将这些图像整合起来,使用了静态显著性图像和动态图像组合给模型学习,同时学习到时空的显著性关系。
本文使用了全卷积网络(FCN)来进行显著性学习的模型。结合以上的数据输入,提升了模型的训练精度,降低了模型训练的时间。
2 预备知识
2.1 Python语言
Python是一种面向对象的、解释型的计算机程序设计语言,于1991发布了第一个公共版。是一个纯粹免费的软件,源代码和解释器CPython遵循GPL协议。强制空格缩进是Python的特性之一,简单明了是Python语法的主要特点。
Python有功能十分强大的库。粘贴语言是另一种处理Python的方式,各种其他语言模块(特别是C/C )可以很容易地与Python结合在一起。Python最常见的用法之一是用来快速生成程序原型,接着再将程序以更适合的语言重写,。例如,3D游戏中的图形的渲染模块对性能具有很高的要求,它可以重写C / C 封装成一个扩展的类库,Python可以对扩展的类库进行调用。但是需要注意的是,当调用扩展的类库时需要考虑平台问题,有些类库可能不能实现跨平台调用。
2.2深度学习
2.2.1研究现状
深度学习在现代社会机器学习技术的许多方面提供了许多便利:比如在网络搜索方面,在过滤社交网络方面,在推荐电子商务网站方面,以及在消费产品中也越来越多的展现,比如在单反相机,拍照手机和智能手机上。机器学习系统能够分析辨认出图像中的对象、把语音转换成文本、搜索对应新闻项、选择出用户感兴趣的文章或产品,并且告知相应的搜索结果。越来越多的领域使用到这种被称为“深度学习”的技术。深度学习可以将多个处理层组成的计算模型来学习并且由相应的抽象层次的数据展现。这些方法极大地改进了语音识别、视觉对象识别、目标检测等许多领域,如药物发现和基因组学。为了发现大数据集中复杂的结构可以通过深度学习的反向传播算法来解决,调整机器识别的内部参数,每层中的表示都可以通过前一层中相应参数计算出来。递归网络在文本和语音等顺序数据上有着突出表现,深度卷积网络在处理图像、视频、语音和音频方面也取得了突破性进展。
2.2.2深度学习概念
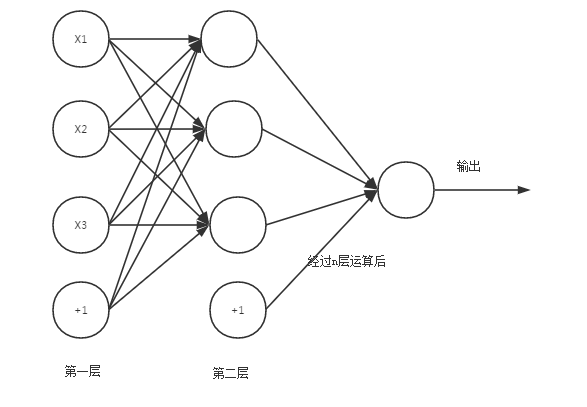
深度学习全称为深度神经网络学习[20],意为在模仿人脑神经网络来学习特征。神经网络就是将许多单一的神经元连接在一起,并且可以实现上一层的输出作为下一层的输入。如图1是一个简单的神经网络示意图。
剩余内容已隐藏,请支付后下载全文,论文总字数:24212字
相关图片展示:



该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

