论文总字数:20742字
目 录
一、绪论 1
1.1国内外研究现状 1
1.2研究内容 2
1.3研究意义 2
二、算法原理 2
2.1朴素贝叶斯算法原理 2
2.2 Laplace校准 4
三、关键技术与算法设计 4
3.1特征提取 4
3.2算法过程 7
3.2.1数据输入 7
3.2.2算法过程 8
3.2.3核心伪代码 8
四、验证实验 11
4.1数据源 11
4.2实验结果 11
4.3与研究相同问题的其他方法的对比 11
4.3.1 与svm分类器性能的对比 11
4.3.2与多层次聚类算法的对比 12
五、结论 13
参考文献 14
致谢 17
基于朴素贝叶斯分类器的同名消歧算法
李娜
,China
Abstract:The duplication of names exists in the academic resource management system, which brings difficulties to academic evaluation, citation analysis, information retrieval and so on. According to different authors use function words in different habits, the Naive Bayes classifier was used to study in this paper. Based on the assumption of feature independence, this paper selects 26 common function words with high frequency as statistical frequency standard, use Naive Bayes classifier to classify texts. Experiments show that the method has a high accuracy rate.
Key words: Naive Bayes classifier;feature independence; function words analysis; name disambiguation
一、绪论
1.1国内外研究现状
同名问题是一个人的名字对应于多个真实的个人的现象。 在学术资源平台中同名的问题是由于多个实体作者共享相同或相似的名称而导致的作者各自的文档混杂在一起的现象。许多科学论文的作者同名,有些作者的姓名随着时间或生活环境的变化而变化,这些问题给学术评价、、引文分析、信息检索等带来了困难。另外,论文中介机构的出现使很多论文代写现象滋生蔓延,这种非法的知识产权交易行为必然会导致学者的学术不端,我们需要科学而准确的方法来辨别论文的真实作者。同名问题严重降低了文档检索和后续算法的准确性。同名划分是为了区分这些混合的真实个体。早在 1998 年 Bagga 和 Baldwin把这个问题做过探索,渐渐引起人们关注。 刚开始针对数字参考文献检索系统中经常会出现同名作者问题进行同名作者消歧,数字图书馆联合会议(Joint Conferences on Digital Libraries,JCDL)就是针对同名消歧的问题而召开的,从 2001 年开始它在美国举行,现已成功举办 16 届,随着网络技术的迅速发展,网页中人名重复问题开始对网络应用造成不利影响。2007 年,网页人物搜索会议(Web People Search,We PS)召开,把同名消歧问题作为自然语言处理的一个基本问题并且主要解决在网络中搜索人名中的同名问题。
为了解决网络搜索中的名称重复问题,已经开发了一些系统。Masaki Ikeda 和 Shingo Ono 等开发了一个 ITC_UT 系统,采用两步聚类策略,第一步采用层次聚类,第二步采用基于混合关键字聚类(CKW-based Clustering)的算法。 Lorenza Romano 和 Krisztian Buza 等开发了一个 XMedia 系统,该系统采用质量阈值聚类(Quality Threshold Clustering)算法,在相似度比较上采用机器学习方法。在2007,陈和马丁提出了一种健壮的无监督名字消歧方法,开发了聚UHK系统。Masaki Ikeda和Shingo Ono开发了一个ITCUTUT系统,采用两步聚类,第一步采用层次聚类,第二步基于混合关键词聚类AlGORIO-THM。罗伦扎-罗马诺和Krisztian Buza开发了一个XMIX系统,该系统采用了质量阈值聚类算法,并利用机器学习方法对相似度进行比较。
近年来,提出了一些新的名字消歧算法。第一类是基于相似性计算的聚类消歧方法,如基于多视图非负矩阵分解的同名区分算法。二是一种基于分层的聚类消歧方法,如分层聚类算法来解决中文姓名的多文档歧义问题。黄提出了基于层次聚类和网页关系的人名消歧。第三是基于特定关系的聚类消歧方法。例如,李提出了一种基于文档合作者的关系的名称消歧方法。
上述聚类算法大多是以论文的元数据作为聚类的基础,计算论文之间的相似度,然后利用合适的聚类算法根据相似度进行聚类。上面有算法也研究了文献检索系统中的同名消岐问题,但是算法依赖于作者的合作者,当研究的某位作者合作者数量较少或经常变化,会导致测试准确率的大幅下降。但是这些算法依赖于很多条件。当条件变少或经常变化时,测试精度将大大降低。此外,这种算法的应用也很窄。但是本文中的姓名消歧算法是基于虚词的使用频率,消除了对很多条件的依赖,具有更广泛的应用范围,并进行了良好的名字消歧。本文所实现的基于虚词分析的同名区分算法消除了对文献合作者关系的依赖,并且在同名区分问题上表现较好。
1.2研究内容
根据论文中所标注的机构名以及不同作者使用虚词的习惯不同,本文利用朴素贝叶斯分类器进行研究。首先在假设特征独立性的基础之上, 讨论朴素贝叶斯分类器的原理。继而描述提取特征的方案:将pdf格式的文本提取为字符串,通过大量实验选取出分辨度较高的一些虚词,统计这些虚词出现的频率,将这些频率作为特征。再将贝叶斯分类器用代码实现,用CNKI上的论文作为数据源进行大量实验。贝叶斯分类器不存在单分类器与多分类器的实现差异, 应用于文本分类这一问题上,达到了一个不错的效果。
1.3研究意义
对于一些作者同名的论文,难以分辨此论文究竟出自哪个作者。本文根据论文中所标注的机构名以及不同作者使用虚词的习惯不同,利用朴素贝叶斯分类器进行同名消歧,使论文被引频次的统计工作更为精确。名称重复存在于学术资源管理系统中,同名消歧给学术评价、信息检索、引文分析等降低了困难。提高区分同名作者的精度,使论文被引频次的统计工作更为精确。同时帮助研究有潜力的学者在各个学科领域的分布状况,从而能够发掘各个学科领域中的专家,研究和辨明不同领域的论题热点。
二、算法原理
2.1朴素贝叶斯算法原理
朴素贝叶斯分类器是基于贝叶斯定理与特征条件之间独立的假设。朴素贝叶斯模型易于建立,没有复杂的迭代参数估计,这使得它对于非常大的数据集特别有用。尽管朴素贝叶斯分类器很简单,但它常常做得出奇地好,并且被广泛使用,因为它通常优于更复杂的分类方法。
朴素贝叶斯是一种有监督学习算法。大多数实际机器学习使用监督学习。监督学习是指你有输入变量(x)和输出变量(y),并且你使用一个算法来学习从输入到输出的映射函数y= f(x)。我们的目标是很好地逼近映射函数,当您有新的输入数据(x)时,您可以预测该数据的输出变量(y)。它被称为监督学习,因为从训练数据集学习算法的过程可以被认为是监督学习过程。训练数据中已标注好正确与否,算法迭代地对训练数据进行预测并纠正。当算法达到可接受的性能水平时,学习停止。无监督学习是指只有输入数据(X)和没有相应输出变量的学习。无监督学习的目标是对数据中的底层结构或分布进行建模,以便了解更多的数据。这些被称为无监督学习,因为不同于上面的监督学习,没有正确的答案,也没有老师。算法留给他们自己的设计来发现和呈现数据中有趣的结构。无监督学习问题可以进一步分为聚类和关联问题。
已知集合: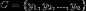 和
和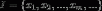 ,确定映射函数为
,确定映射函数为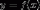 ,使得任意
,使得任意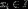 有且仅有一个
有且仅有一个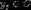 使得
使得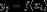 成立。对上述符号的解释如下:其中C为类别集合,其中每一个元素yi是一个类别,而I为一个待分类项,其中每一个元素是为一个特征属性,f叫做分类函数(分类器)。分类算法的核心任务就是构造分类函数(分类器)f。
成立。对上述符号的解释如下:其中C为类别集合,其中每一个元素yi是一个类别,而I为一个待分类项,其中每一个元素是为一个特征属性,f叫做分类函数(分类器)。分类算法的核心任务就是构造分类函数(分类器)f。
在许多分类器的构造方法和理论中,朴素贝叶斯分类器因其计算效率高、精度高、理论基础扎实而得到广泛应用。该思想的基础是:对于给定的待分类项目,在该项目发生的条件下,求解每个类别的发生概率,并将该项目排序为概率最大的类别。每个训练样本数据被分解为一维特征向量X和决策类别变量C,并且假设特征向量的分量是相互独立的。
具体定义如下:
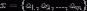 为一个待分类项, 每个 "a"是x的一个特征属性,
为一个待分类项, 每个 "a"是x的一个特征属性, 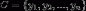 为一个类别变量, 计算出
为一个类别变量, 计算出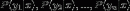 .
.
如果, 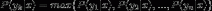 ,那么
,那么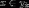 .
.
根据贝叶斯定理:
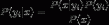
由于分母对于所有类别来讲都相当于常数,要使上述公式所得计算结果最大我们只需要使分子最大。因为特征属性是条件独立的所以有:
剩余内容已隐藏,请支付后下载全文,论文总字数:20742字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

