论文总字数:26304字
目 录
1.引言 5
2.背景知识 5
2.1 研究背景现状 5
2.2 研究意义 6
2.3 研究可行性 6
2.3.1 经济可行性 6
2.3.2 技术可行性 6
2.3.3 操作可行性 7
3.开发环境背景技术介绍 7
3.1 Chrome浏览器 7
3.2 插件开发环境 8
3.2.1 chrome插件结构 8
3.2.2 Manifest.json 9
3.3 JavaScript语言 9
3.4 HTML语言 10
3.5 Java语言 10
3.5.1 Java语言简介 10
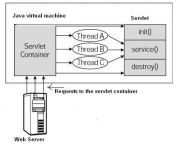
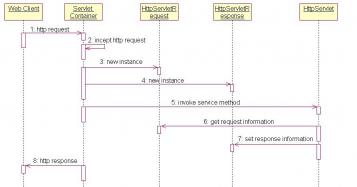
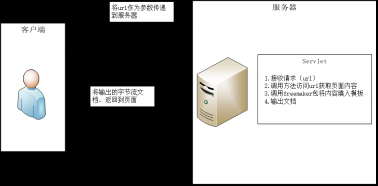
3.5.2 Servlet简介 11
3.6 核心包介绍 12
4.系统设计 13
4.1 系统概述 13
4.2 主要功能模块 14
4.2.1 获取网页核心内容 14
4.2.2 模板装填 15
4.2.3 控制程序实现 16
4.2.4 模板文件 18
4.3 系统核心操作说明 18
5.系统配置与功能测试 20
5.1 服务器环境配置 20
5.2 浏览器环境配置 21
5.3 系统运行环境 23
5.4 系统维护 23
5.5 测试环境 24
5.6 测试用例 24
5.7 测试的意义 25
6. 结论 26
参考文献: 26
致谢 28
网页核心内容提取与转换插件开发与实现
金素梅
,China
Abstract:With the rapid development of the information network era, information dissemination is no longer the paper, "formalization is becoming more and more popular, the explosive growth of data, but we have access to information at the same time, there are a lot of is that we don't need the information, such as advertising, pop, these are not what we want, but also in the browse we sometimes are not careful to them, for us, this is a very troublesome problem, but also reduces the efficiency of our study and work. This topic is to study how to extract the core content of the web page based on the Chrome browser, including the core content of text and pictures, the core content of the extract to save the form of Word or PDF. First of all, we need to understand the basic knowledge of chrome expansion development, followed by an understanding of the development of spring MVC framework and the use of JavaScript language.
Key words:Chrome browser;Core content;spring MVC ;plug-in;boilerpipe;
1.引言
在当今的信息化时代,信息数据呈爆炸式增长,但对于我们来说并不是所有的信息都是我们想要的,我们只有通过检索的方式才能找到我们所需要的相关信息。如何确定是否是我们需要的信息呢?这个就需要我们对检索到的信息进行筛选,筛选完成后,如果正是我们需要的信息我们可能会选择下载或者把链接地址添加到收藏夹,以防我们再次需要的时候,重复以上操作,严重降低工作效率。当我们保存链接到收藏夹时会发现,页面上有许多的广告和弹窗,并不是我们所需要的信息,而且一不小心就会点错,并且不能保证广告里是否有捆绑插件,是否插件中捆绑了病毒,这些都是网页上潜在的危害。当我们选择文件进入下载的时候,往往会带有捆绑软件,一不小心就会安装到计算机上。本论文实现的是在网页上,通过点击插件的方式,提取网页核心内容,并把提取的核心内容保存到Word或者PDF中去,同时保存的文档会自动下载本地计算机。这样的好处是把你所需要的信息分类,把下载的文件通过文件目录的形式保存到电脑里,即使你处于离线状态,依然能够查看所需要的信息。并且减少了大量搜索筛选的所话费的时间,提升了学习状态和工作效率。
本论文是基于Maven搭建Spring MVC框架,通过Maven来管理此项目。Maven是一套可以通过简单的描述信息来管理项目的构建、报告以及文档的项目管理工具。
本论文后台处理机制是用Spring MVC框架,它很好的把网站的处理程序对象、模型对象、控制器、和分派器分离了出来,降低了耦合性,也变得更加多样化。Spring框架优点在于高度可配置,易于代码的单元测试。
本论文前端采用javascript语言编写,保证了客户端交互的效率,通过ajax方式进行后台交互,JSON格式进行数据交换,增强系统的可读性和可扩展性。
本论文是一个Chrome插件开发,它的组成非常简单。谷歌插件扩展程序其实由一个manifest.json 和一系列 html页面、css样式表、Javascript、image组成的。其中核心文件manifest.json用于指定应用的显示名称、图标、应用入口文件地址、插件的动作及需要使用的设备权限等信息。
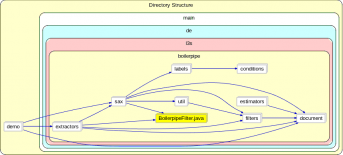
本论文通过引入开源的boilerpipe包,用于实现从网页中去除广告信息,弹窗以及一些其他的不必要的信息,提取出我们所需要的信息,比如网页的核心内容。可以通过配置不同的extractor来extract目标内容。其算法的核心是用一个分类器来提取出我们的核心信息。这个类里面会用一个URL会通过这个URL中提取标题和文章内容,包里还定义了多个filter,filters的作用是对TextBlock进行过滤,Extractors(提取器),提取流程的入口。提取器会定义自己自己的不同的提取方法,这些提取的方法是根据自己需要所确定的,通过调用编写的不同过滤器方法实现不同的提取的效果。Estimators(评估器),评估一个extractor对特定document的提取效果。下面的工作主要是实现包的调用,先把包导入到我们的项目中去,再在我们自己写的方法中实现报的调用,实现网页核心内容提取的局部工作。
2.背景知识
2.1 研究背景现状
当下,不仅是大学生,中学生都已经被受到了网络时代的影响,都会浏览网页,搜索信息,而且基本上电脑和网络是大众化的,很多人现在的惯性思维是有问题找百度,百度找一找基本能找到我们相关的资料或者信息。这样一来难免不会碰到网页中的广告和弹窗,如果网页信息量较大时加载可能会比较慢, 据我这段时间调查研究以来,网络上实现网页核心内容提取的插件并不多,而且应用范围比较小,局限性高,但拥有参考性的价值。还有一点就是大部分学生和工作者都比较喜欢用Chrome浏览器,而插件的开发与应用都是基于Chrome浏览器实现的。谷歌浏览器最大的特点架构的多进程化,这样可以保证它不会因为某个恶意软件或者不符合规范的网页而不能运行。他每个部分都是在独立的环境各自运行的,不会因为某个站点的问题影响到另外的站点打开或者使用。这样封闭式的环境架构的特点在于软件的安全性得到更深一步的提高。
2.2 研究意义
经过一段时间的调查研究,个人觉得这项课题研究是比较重要的,比较符合大众的需求,尤其是不擅长使用计算机和识别网络陷阱以及上网安全意识比较差的人。把网页核心内容的提取出来保存到Word或者PDF就会方便很多。尤其是方便下次查阅或者复习的时候就不需要再次到百度中搜索相关资料。不仅提高了工作效率,而其也便于以后在没有网络的情况下查阅这些资料。
2.3 研究可行性
2.3.1 经济可行性
到目前为止,本插件是公益安全性质,目的是为了让所有网民体验到便捷快速、安全高效的网络环境,并没有商业性质在里面。另一个方面,本插件投入使用以来并未有其他开销,可能后期会需要一笔阿里云服务器的租赁费用。前期只是用台式机装了服务器系统,模拟了服务器环境,可能导致的问题是使用不够稳定、并发量低,如果后期这些情况暴露出来而且很重的时候,会考虑租赁服务器,可以是类似于阿里的又或者是新浪的免费服务器,将成本降到最低。
2.3.2 技术可行性
本项目中使用到的Spring MVC框架,也是一个很成熟的架构。可以帮助我们设计更加简洁的Web层,更简洁的Web层的开发;天生与Spring框架集成(如IoC容器、AOP等);能简单的进行Web层的单元测试;支持灵活的URL到页面控制器的映射;非常容易与其他视图技术集成,他可以集成FreeMarker,在把核心内容填充到Word中,我们采用了FreeMaker,FreeMarker是一款模板引擎: 它可以将要改变的数据填入这个模板,并由此生产对应的文档等。模板是用FreeMarker模板语言(FTL),这是一个简单的、专业的语言(不成熟的编程语言如PHP)。在模板中,专注于如何呈现数据,而在模板外,专注于呈现什么数据。
本系统前端实现用了JavaScript语言编写,是一种轻量级的弱类型的开发语言。是可插入 HTML 页面的编程代码,它插入 HTML 页面后,可由所有的浏览器执行,对于开发者来说javascript语言学习起来很容易也很方便。变量类型采用弱类型,并未使用要求严格的数据类型,大家都清楚的是使用严格的数据类型,会给语言本身带来很大的局限性。它直接对客户端层面发出的请求做出响应,不需要再通过Web服务程序处理。Javascript语言采用事件驱动对用户的请求做出反应响应,例如表单的提交是通过button的点击事件,一些页面上的特效都是通过点击事件触发的。Javascript语言兼容性高,只是依附于浏览器,与操作系统的环境没有关系,但必须是能够运行浏览器的计算机。从而实现了“编写一次,走遍天下”的梦想。javascript语言另一个重要特点是安全性是可控的而且比较高,它禁止访问用户的个人计算机上的硬盘,也禁止将前台的数据保存到后端服务器上,禁止对网站上的资源信息编辑,只允许经过浏览器完成信息的查阅或数据的动态交互。从而有效地防止数据的丢失。
本论文研究插件的开发是基于谷歌浏览器完成的,换句话说,谷歌浏览器功能不再局限于是一款浏览器,完全相当于一个开发平台,更夸张点说是一套操作系统都不为过。它采用和Safari一样的内核WebKit,加快对网页的渲染,并且谷歌还自主研发了V8引擎,这使得谷歌浏览器的进一步提升了他的执行效率,让浏览器更加的高效,并实现了可以运行更深层次更复杂的javascript程序。
2.3.3 操作可行性
本插件使用的主体对象可以是所有网民,这类人群中有在校学生、上班族、以及一些退休工作者。都是对新鲜事物充满好奇和接受的能力,而且操作简单容易上手,比较人性化。最主要在于是节省了使用者的时间,增强了浏览网页的安全性,提高了我们浏览信息的效率。
3.开发环境背景技术介绍
3.1 Chrome浏览器
扩展程序的开发可以支持大部分的浏览器,扩展的开发编写的语言也是多样化的,比如PHP、C语言、Java语言和汇编语言等等。选择谷歌浏览器很重要的一点是谷歌的开源化,因为谷歌的开源给开发者带来了很大的便利,为开发者降低了开发成本,相比其他的浏览器开发步骤更加容易上手,更易于理解,为开发者减少了很多理解和运用的时间。其次谷歌的在保证系统的安全性上比其他的浏览器做的好,这样保证我们的扩展程序运行更加稳定,更加安全。谷歌浏览器在运行时,每个部分都是在独立的并不会对其他的空间造成影响,不会因为某个部分的崩溃造成其他网页浏览的拥堵,这是由谷歌浏览器的扩展开发应用运行机制所决定的,内部设计决定顶层架构。
3.2 插件开发环境
3.2.1 chrome插件结构
剩余内容已隐藏,请支付后下载全文,论文总字数:26304字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

