论文总字数:21197字
目 录
1 引言 1
2 相关研究 1
2.1 ESI介绍 1
2.2 网络爬虫 2
2.2.1 反爬虫技术的应对措施 3
2.3 代理 4
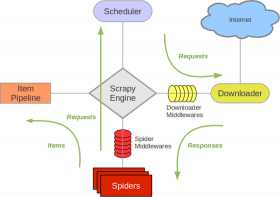
2.4 Scrapy 4
2.4.1 spider中的属性,方法 5
2.5 XPath 5
2.6 MongoDB 7
2.7 困难与挑战 8
3 系统设计与实现 8
3.1 代码运行环境 8
3.2 页面结构分析 8
3.2.1 ESI 搜索结果页 9
3.2.2 ESI历年被引用数纪录页面 9
3.2.3 Web of Science 页面 9
3.3 数据结构 10
3.4 设计xpath规则 12
3.4.1 浏览器容错机制 12
3.5 url结构分析 13
3.5.1 ESI搜索结果列表页 13
3.5.2 ESI历年被引用数纪录页面 13
3.5.3 Web of Science页面 13
3.6 配置代理IP 14
3.7 工作流程 14
3.8 scrapy 设置 15
3.9 数据清洗 16
3.10 统计 17
3.10.1 MongoDB聚合操作介绍 17
3.10.2 项目实例 18
4 实验结果 19
参考文献: 23
致谢 24
计算机类ESI数据采集系统设计
吴乾泰
,China
Abstract:ESI is playing a more and more important role in scientific research in universities.These years,ESI has become a import index in evaluating the international development level of scientific research.More and more universities use ESI to guide their research and study. This article is aim to build a data acquisition system based on Scrapy to collect the data of papers in computer science on ESI, and persistent data into local MongoDB. Schools can use it to acquire the latest hot subject in computer science area,and provide reference and evocation for research works. Base on the data collected,we also make some analysis and find out some conclusions,these conclusion show the development status and research fronts in computer science in a way.
Key words:spider,Scrapy,ESI,MongoDB
引言
科学研究是我国世界一流大学和一流学科建设的重要内容。 美国科学信息研究所(ISI)的基本科学指标(Essential Science Indicate,ESI)数据库统计结果全面、更新速度快,目前已经成为科学评价的标杆数据库。 ESI数据库包含国家、机构、期刊、科学家等若干个子数据库,其中 ESI 世界前 1%学科数据库在我国具有较大的影响力。通过分析统计ESI数据库的论文数据。指出目前存在的问题,明确科研管理改革方向, 以期为我国高校进一步提高科研发展水平、增强科研 相对影响力提供科学依据。
论文总被引频次综合反映了科研规模以及质量,是在国际范围内衡量科研发展水平的客观指标。ESI数据库以全球各个科研机构在过去十年里被SCIE(科学引文索引)和SSCI(社会科学引文索引)数据库收录文献的总被引频次为依据,分22个学科对所有科研机构进行排序,选取各学科论文总被引频次排列在世界前1%的机构, 构建了ESI世界前 1%学科数据库。虽然ESI的世界前1%学科数据库存在一定的局限性,但其排名已成为各个高校评估科学研究国际发展水平的重要指标。
ESI本身已经提供了一系列的统计结果,从多个维度对不同领域的前沿论文做了展示,不过,对于高校来说,更细致的研究分析,ESI并没有满足。目前,业界也没有很好的基于ESI做进一步统计分析的平台。基于这样的现状,本文尝试建立了一个针对计算机科学这一学科的高引用论文采集系统,并作了一些简单的数据统计,为学校的科研建设提供数据上的支持和参考。
相关研究
ESI介绍
ESI(Essential Science Indicators)-基本科学指标数据库,是由ISI(美国科技信息所)于2001年推出的衡量科学研究绩效、跟踪科学发展趋势的基本分析评价工具,是基于ISI引文索引数据库Science Citation Index (简称SCI)和 Social Science Citation Index(简称SSCI)所收录的全球8500多种学术期刊的1000多万条文献纪录而建立的计量分析数据库。ESI从引文分析的角度,针对22个专业领域,分别对国家、研究机构、期刊、论文以及科学家进行统计分析和排序,主要指标包括:论文数、引文数、篇均被引频次。ESI中的数据包括高被引率作者的排名、论文排名(前1%)、国家排名(前50%)和期刊排名(50%)。
ESI的功能:
1. 分析指定机构、国家和学术期刊的科研实力,论文影响力;
2. 对22个学科领域分别从国家、研究机构、期刊、论文、科学家不同的角度进行统计分析;
3. 跟踪各个学科领域内的研究发展趋势;
4. 可用于企业,科研机构查找潜在的同行和雇员,为个人提供潜在的合作者信息;
5. 测定,统计各个研究领域的发展现状;
6. 提供与ISI Web of Knowledge的链接。
ESI相关概念解释:
1. 高被引论文: ESI 根据论文在相应学科领域和统计时间内被引频次排在前1%以内的论文;
2. 热门论文: 某学科领域发表在最近两年间的论文在最近两个月内被引次数排在前0.1%以内的论文;
3. ESI划分的22个学科按名称的 英文字母排列依次为:农业科学、生物学与生物化学、化学、 临床医学、计算机科学、经济学与商学、工程学、环境科学、药理学和毒物学、物理学、植物学与动物学、精神病学与心理学、社会科学总论、空间科学。

图 2‑1 ESI首页

图 2‑2 高引用论文搜索框
图 2‑1显示的是ESI的首页。其中提供了:
1. Citation Rankings:科学家,机构,国家/地区,期刊四个维度的论文被引用数的排行榜,可以增加学科分类的筛选条件。
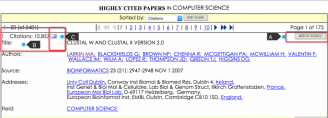
2. Most Cited Papers:查看过去10年或过去两年各个学科的高引用论文,也是本文所要研究的目标
3. Citation Analysis:主要是从学科角度出发,统计了各个学科的研究前沿排行(细分课题的论文数,引用数,每篇论文平均被引用数)和过去十年的论文数,被引用数。
图 2‑2显示的是过去10年高引用论文的搜索条件,可以增加多个筛选条件,这里和常见的论文数据库功能是一致的。
对于数据更新频率和数据源的说明:
1. ESI 数据库每两个月更新一次数据,每次数据的统计时段为过去十年。
2. 网站上和本文中多次提及“过去10年”只是ESI官方的说法,这里的实际数据来源在图2-1中显示的是:从2005年1月1日到2015年12月31日期间全球发表的所有论文,共11年0个月的数据,最近一次的更新日期是2016年3月10日。
网络爬虫
网络爬虫(web crawler)又被称为网络蜘蛛(web spider),它从可以按照代码中确定的逻辑下载互联网中特定的网页,是搜索引擎的一个重要组成部分。爬虫的关键技术包括两部分,一是从互联网上获取网页,这个过程中有许多需要考虑的问题,比如本地带宽的利用问题,根据站点特征设计合理调度策略以减轻对目标服务器的负担等。在一些超大规模的数据测量中,爬虫系统还需要考虑DNS查询的瓶颈问题。另外,还有一些通用规则需要遵循,例如大部分网站都有自己的robots.txt,其中声明了网站中的哪些内容是不允许爬取的,哪些是可以被获取的,还可以对特定的爬虫自定义规则。

图 2‑3豆瓣的robots.txt
1. 爬虫需要考虑的问题。有很多网页格式错误百出,要想得出一个通用的解析方法几乎是不可能的事。Ajax技术出现之后,如何提取JavaScript脚本动态生成的网页信息成了所有爬虫无法回避的一大难题,除此之外,Internet上还不可避免的会出现不同规模的环路,如果不加处理的盲目提取链接的话,就会陷入无限的循环爬取中,浪费网络带宽和其它资源。
2. 爬虫工作原理。根据提取数据内容和方式的不同,爬虫通常被分为两种:通用爬虫和聚焦爬虫。通用爬虫是搜索引擎使用的方式,其目标是抓取尽量多的网页信息,而聚焦爬虫是针对特定的一类或几类网站,抓取指定目标网页中的一些特定信息。通用爬虫是从初始设定的url开始,获取对应网页的内容,然后提取网页中新的url添加到url队列里,然后再提取url队列出的下一个url,开始下轮的抓取直到满足停止条件为止。相比通用爬虫,聚焦爬虫的工作流程通常会更加复杂一些,因为聚焦爬虫多了一个提取需求信息的步骤。爬虫运行的目标就是有目的的提取网页中的信息。此外聚焦爬虫与通用爬虫还有一个很大的不同,就是提取到的新的url并不都需要进行爬取,而是要经过开发者的算法筛选后才能确定是否需要对其进行爬取。
反爬虫技术的应对措施
很多网站为避免被爬虫抓取数据,使用了一定的规则和特定的机制来实现,常见的应对措施如下:
1. 设 置 download_delay, 即下载器在下载同一个网站下一个页面前需要等待时间。如果下载等待时间长,则不能满足短时 间大规模抓取的要求;而太短则大大增加了被Ban的几率。因此在 settings.py 中设置: DOWNLOAD_DELAY = 2;
剩余内容已隐藏,请支付后下载全文,论文总字数:21197字
相关图片展示:


该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

