论文总字数:18082字
目 录
1绪论 1
1.1 研究背景和意义 1
1.2 国内外研究现状 1
1.3 本文的主要工作 2
1.4 本文的结构安排 3
2 SIFT特征与词袋模型(BOW) 3
2.1 SIFT特征 3
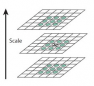
2.1.1 生成尺度空间和检测极值点 4
2.1.2 精确定位关键点 5
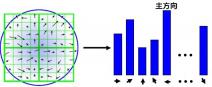
2.1.3 分配关键点的方向 6
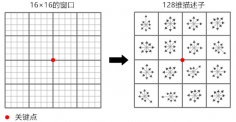
2.1.4 生成特征向量描述子 7
2.2 词袋模型(BOW) 7
2.2.1 文本信息检索领域的词袋模型 7
2.2.2 图像检索领域的词袋模型 8
3系统框架设计 9
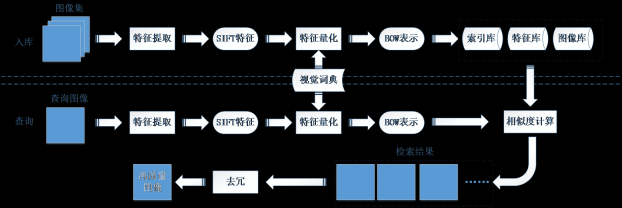
3.1 基于BOW的近重复图像检索去冗框架 9
3.2 图像数据集 10
3.3 倒排索引 11
3.4 相似度度量 12
3.5 检索结果评价 12
3.6 图像去冗 12
4系统集成实现 13
4.1 开发工具简介 13
4.1.1 OpenCV简介 13
4.1.2 VC 与MFC 13
4.2 系统模块 13
4.3 界面设计 14
4.4 图像检索流程 16
5系统实验与分析 17
5.1 实验环境 17
5.2 实验方法 17
5.3 实验结果与分析 18
6总结与展望 19
6.1 本文主要工作的总结 19
6.2 工作展望 19
参考文献: 20
致谢 21
基于Bag of Visual Words的近重复图像去冗系统
设计与实现
朱宝佳
,China
Abstract:The existence of large near-duplicate images brings about a series of problems such as slow retrieval, copyright infringement, the waste of network bandwidth and storage space. How to manage these image data efficiently, and then establish a near-duplicate images retrieval system to help users quickly find satisfactory images has become an important and challenging research work.
The purpose of this paper is to research and implement a near-duplicate images retrieval and de-duplication system based on Bag of Visual Words (BOW). This scheme can be divided into two main parts, near-duplicate images retrieval and de-duplication. In near-duplicate images retrieval, use SIFT feature as a base, and use BOW and inverted index to speed up the feature retrieval process. In de-duplication, pick up the best image by calculating the quality of query results.
Finally, experiments show that the method can retrieve the image database in real-time, and return the near-duplicate images similar to the query image in the database.
Key words:near-duplicate images retrieval;scale invariant feature transform(SIFT);bag of visual words(BOW);K-means clustering;inverted index
1绪论
1.1 研究背景和意义
近些年,由于互联网、多媒体技术的飞快成长与智能手机、平板和图片编辑软件等的遍及,使互联网中图像等多媒体信息爆炸式增加。对图像来说,人们可以很方便的使用相机、智能手机和平板等设备拍照、修图并上传到社交平台上,网络上的图片数据量暴增。如何对互联网上大量的图像数据进行高效管理以及方便人们的不同查找需求,愈来愈成为一个具有挑战性的工作和研究。而解决这个问题的关键点便是利用图像检索和去冗方法。
虽然我们能够很快的发现几副图像的相似点与不同点,但是面对互联网上海量的图像数据,人工检索是不可行的,这就需要计算机来帮助检索。然而一切存储在计算机中的数据都是一些“01”二进制串,需要一种可以让计算机理解图像丰富信息的方法,这促使了基于内容的图像检索的出现。基于内容的图像检索通过匹配图像特征进行检索。基于特征的图像检索在当前研究中应用较为广泛。
近重复图像检索是图像检索中的一个重要钻研方面,拥有极大的探究价值和应用领域。在图像搜索中,可以快速筛选出高质量的近似图像,提高人们的搜索使用体验。在安全领域,可以用来识别人脸和指纹等。此外,还可以用在检测图像版权、协助医疗诊断、节省网络带宽和存储空间等方面。
1.2 国内外研究现状
最早的图像检索是基于文本标注的,通过检索描述图像特点的文字来查询图像。但因其人工工作量大,检索效果差等原因已逐渐被淘汰。当前最为热门的是基于内容的图像检索方法。
基于内容的图像检索技术流程一般如下:首先提取图像库中全部图像的某种或多种特征来带代表这些图像;然后建立提取的大量特征的索引,来加快下一步的匹配速度;接下来通过比较这些特征的相似度来检索相似图像;最收集使用者的意见来评价并改进各种参数,来增大检索的精确性。
从图像中提取的特征一般可分为全局特征和局部特征。全局特征包括形状、文理和颜色等特征,但是因为全局特征对各种常见图像变换的鲁棒性比较差,所以并不适合用来表示图像。为了增强图像特征的鲁棒性,专家们提出了多种局部特征,如SIFT[1]、SURF[2]和Harris[3]角点等。局部特征具有很好的稳定性,不容易受外界环境的干扰,因此得到了广泛关注。图像专家David G. Lowe提出并改进的SIFT[1]特征是当今应用较多且效果优良的图像局部特征之一,在实际的图像应用中可以取得很好的效果。后人在SIFT特征的基础上做了许多的改进。例如Harris角点和SURF方法分别从兴趣点方面和特征提取速度上对SIFT进行了改进。
基于局部特征的图像检索通过计算各个图像的特征相似度来获取检索结果。由于每幅图像提取出的局部特征量非常多,逐个比较时计算量很大,会花费大量时间。而文本检索领域中的词袋模型(BOW)的引入,成功的解决了这一问题。词袋模型[4]将一幅图像中的局部特征当作一个个“单词”,将这幅图像当作由这些“单词”组成的文本,然后利用文本检索的方法进行检索。此方法效率很高,节省了图像匹配时间,在图像检索中获得了广泛的应用和发展。
在词袋模型(BOW)中,较为重要的一个步骤是由局部特征生成视觉词典。所有的局部特征通过聚类算法生成本图像库的视觉词典,通常选用基于距离的K-means聚类算法,N个局部特征将被划分成K个类别,被放入同一组的特征相似度很高,不同组之间特征相差较大。
虽然词袋模型(BOW)具有较高的检索精度和速度,但是却忽略了一幅图像中各个局部特征之间的关系,无法筛除错误的匹配以达到更高的检索精度。这使得人们的关注点转向几何校验,通过对局部特征进行空间关系检查以提高精度。传统的方法在全几何校验中计算时间太长,效率不高。而Jegou针对这个问题提出的弱几何一致性[5](Weak Geometry Consistency,WGC)方法,通过在局部特征中引入尺度和角度变化信息,使得空间关系检查变的更加高效,节省了大量检查时间。然后又出现了对WGC进行改进的E-WGC[6](Enhanced Weak Geometry Consistency)方法,此方法在WGC的基础上加入了位移信息,进一步提高了精确性。
随着大量优秀的图像算法的提出和应用,图像检索正变得越来越高效和精确。接下来列举二个比较常用的图像检索系统。
我们这里所列举的并不是平时我们常用的百度图片这类用关键词来搜索图片的系统。而是使用图片自身来搜索图片的系统。这种搜索不使用关键字,而是用图片自身取代关键字来搜索网络中的相关图片。此处用图片来搜索图片的方法常常被称作“反向图片搜索”。
TinEye是一个性能强劲的老牌相似图片搜索网站。如果存在一张你不知道来从哪里来的图片,或是你想知道这张图片在哪些网站出现过,这时候TinEye就可以派上用场了。它可以帮你找到这张图片的类似结果。TinEye网站的使用方法和常用的百度图片搜索存在很少的不同点,用户能够选择上传一副图片,然后点击搜索,也能够选择在输入框内键入一副图片的网络地址,该搜索网站一样能够搜索出与这张图片相似的图片来。TinEye可以在几秒内搜索数百亿张图片,而且搜索出来的结果相当精确。TinEye对于非商业应用完全免费,图片搜索准确率很高,即使上传图片的局也可以找到这张图片的整个部分。而且,我们还可以在自己的web浏览器中安装TinEye工具。安装完毕之后,我们即可以对打开的网站中的图片直接右击搜索了。
百度识图是百度发布的一款以图搜图产品,功能和Tineye类似,也是根据用户上传的图片或者提供的图片URL。它拥有全中文的界面,交互方便,并且可以检索到国内的论坛或者小网站。除了相似图片搜索功能,百度识图还可以实现全网人脸搜索和花卉品种搜索等细化功能。利用百度识图,我们可以利用手头的小图片或有水印图片,找到更大更清晰的图片,也可以由图像的局部搜索出该图的完整版本。
1.3 本文的主要工作
本文的工作主要包括:学习研究了近重复图像检索中常用到的SIFT算法和词袋模型(BOW)的基本原理、主要特点和使用方法等。基于上面的学习研究以及参考他人论文中的方法理论,构思设计了基于BOW的近重复图像检索去冗系统,为提高系统的检索效率对图像特征建立了倒排索引,并思考制定了图像相似度度量、检索结果评价和图像去冗的方法。然后使用C 语言编程实现了一个简单易用的近重复图像检索去冗系统,能够实时地检索图像库,并较为准确的返回数据库中与查询图像相似的图像集。最后通过实验及对实验结果的分析,得到了本实验的最佳实验参数大小,然后使用该结果计算了本检索系统的准确性。
1.4 本文的结构安排
本文内容共包括六章,各章安排如下:
第一章是绪论,首先分析了基于Bag of Visual Words的近重复图像检索的研究背景和意义,然后介绍了图像检索领域的国内外研究现状,包括研究方向、使用的算法和目前较为著名的图像检索系统。最后说明了各章节的结构安排。
剩余内容已隐藏,请支付后下载全文,论文总字数:18082字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

