论文总字数:19485字
目 录
第一章 绪论 1
1.1引言 1
1.2中文分词的发展 1
1.3本文结构 1
第二章 中文分词算法基本介绍 2
2.1中文分词算法主要的问题 2
2.1.1词语的界定 2
2.1.2分词和理解的先后顺序 2
2.1.3歧义处理 2
2.1.4未登录词处理 3
2.2现有的分词算法 3
2.2.1机械分词 3
2.2.2统计分词 3
2.2.3理解分词 3
2.2.4相互比较 4
第三章 分词算法的设计 4
3.1 系统总体架构 4
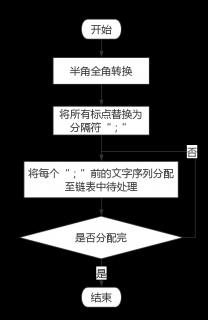
3.2 预处理流程设计 5
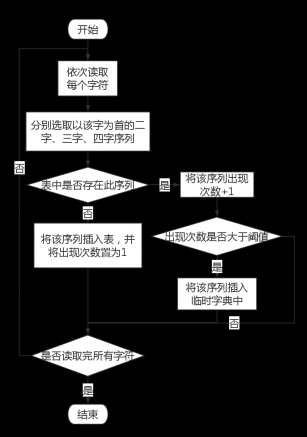
3.2 基于统计的分词设计 6
3.3.1统计分词原理 6
3.3.2统计算法的设计 7
3.3.3 统计策略具体流程 7
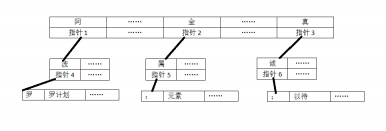
3.4 机械分词词典构建 8
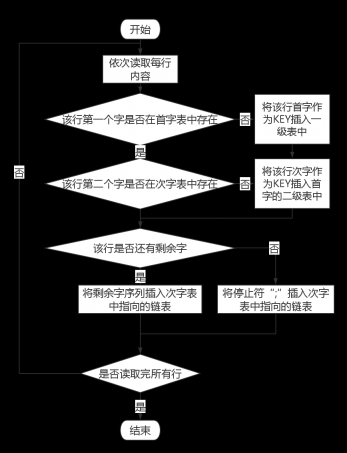
3.4.1核心词典构造 8
3.4.2拼音字典构造 10
3.4.3其他字典 11
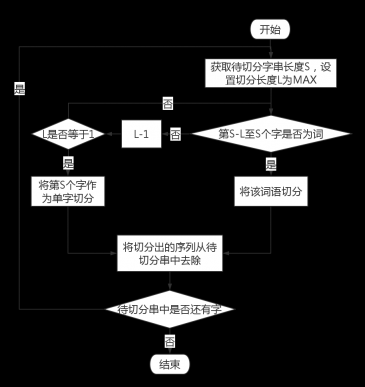
3.5 机械分词算法设计 11
3.6 后续处理设计 13
3.6.1 歧义处理 13
3.6.1.1 歧义识别 13
3.6.1.2歧义处理 14
3.6.2 拼音纠错 15
3.6.2.1 纠错字段识别 15
3.6.2.2拼音纠错处理 16
第四章 系统实现及实验 16
4.1系统演示 16
4.1.1界面演示 16
4.1.2统计分词演示 17
4.1.3分词演示 18
4.1.4纠错分词演示 18
4.2实验比较 19
4.2.1标准介绍 20
4.2.2初始化实验 20
4.2.3学习语料后实验 20
4.2.4 拼音纠错实验 21
第五章 总结与展望 22
参考文献 23
致谢 24
声 明
本人郑重声明:
- 持以“求实、创新”的科学精神从事研究工作。
- 本论文是我个人在导师指导下进行的研究工作和取得的研究成果。
- 本论文中除引文外,所有实验、数据和有关材料均是真实的。
- 本论文中除引文和致谢的内容外,没有抄袭其他人或其他机构已经发表或撰写过的研究成果。
- 其他同志对本研究所做的贡献均已在论文中作了声明并表示了谢意。
作者签名:
日 期:
汉字智能分词系统的设计与实现
吴宇雷
,China
Abstract: Stepping into the Information Age,the information processing technology becomes more and more important,and the foundation of it is text segmentation.Compared with western languages,the segmentation of Chinese is more difficult because of its complexity.Statistical word segmentation and mechanical word segmentation is widely used at present.In this paper, an algorithm based on both Statistical and mechanical word segmentation is designed.We first used statistical skills to generate the results and put them into the core dictionary as a supplement to solve the problem of unlisted words,then we used the mechanical word segmentation to segment the text.Overall,the system in this paper has a satisfactory result.It has good ability to identify the unlisted words and eliminate the ambiguity.It basically satisfies the practical application of Chinese information processing requirement in terms of efficiency.
Key words: Chinese Word Segmentation,Statistics,Dictionary,Unlisted Words,Typos
第一章 绪论
1.1引言
随着计算机的诞生以及飞速发展,人类正式步入了信息时代。在这个信息飞速膨胀的时代,不论是个人、企业还是国家,如果想要在激烈的竞争中具备优势,都需要获取大量有价值的信息,信息的重要性与日俱增。在这样的环境下,信息处理技术应运而生。在各项计算机信息处理技术中中,中文信息处理技术是非常重要的一个单项,而中文分词技术又是中文信息处理领域的最基础也是最重要的技术。无论是信息的校正、信息分类还是信息检索、语言翻译,都需要建立在分词的基础上,所以分词的好坏直接影响了后续处理环节的效果。只有提高中文分词的工作效率和准确率,才能使中文信息处理平台稳定而高效的工作。
1.2中文分词的发展
中文分词处理涵盖了汉字、词组、句子、段落等多级信息的处理任务。早期的中文分词主要采用的是机械匹配的办法,这种办法虽能大体上将句子划分成单个的词语,但由于仅仅是通过计算机机械的比较,所以这种办法并不具备对歧意的处理能力,因而导致分词准确率也较差。
CDWS分词系统是我国最初使用的中文分词处理系统,它于上世纪八十年代由北京航空学院提出实现,其主要思想是使用最大匹配算法进行分词,并且采用了词尾字构词纠错技术[1]。
之后,北京航空学院又在其基础上提出了CASS分词系统,在使用正向最大匹配算法的基础上,添加了运用知识库来处理歧异字段的方法[1]。
ABWS是由山西大学开发的自动分词系统,它采用了“两次扫描联想回溯”的方法,通过使用了一定数量的词法和句法知识,使得在不计算非常用词和未登录词时切分正确率达到了98.6%[1]。
清华大学开发了SEG和SEGTAG分词系统。SEG分词系统提供了带回溯的正向最大匹配、反向最大匹配、双向最大匹配和全切一一评价切分算法[9],并首次提出了找出待切分字串所有可能的切分方法并选出最佳字串序列分词结果的全切分算法。后者使用有向图来集成不同种类的信息并将各类信息进行综合来提高切分的精度。
目前使用的最广泛的分词系统是中科院开发的ICTCLAS分词系统。ICTCLAS系统建立了各种各样的资源库,比如地名资源知识库(分为地名库、地名用字库等),识别规则库(筛选规则、确认规则、否定规则)。利用各种信息和规则,通过层叠马尔科夫模型语料库进行训练,将汉语分词,词性标注、歧异排除和未登录词识别集成到一个完整的框架中。该系统目前被证明具有较好的分词效果[1]。
1.3本文结构
本文主要分为五章:
第一章是绪论,介绍了本文的研究背景和意义以及中文分词算法目前的发展情况。
第二章是中文分词算法的中难以攻克的几个主要问题,主要包括未登录词处理和歧异识别等,并且介绍了使用较为广泛的机械分词与统计分词。
第三章主要介绍了本文采用的算法的主要步骤与具体流程设计,采用了统计分词与机械分词相结合,通过一定的语料学习生成临时字典来解决部分未登录词的问题,之后使用最大匹配算法分词,采用了一定的歧异处理策略,最后在进行拼音纠错提高分词的准确率。
第四章主要展示了系统的运行情况以及相关的实验,并给出了实验数据进行比较。
第五章主要为总结和展望,以及本文提出系统的创新及不足。
第二章 中文分词算法基本介绍
2.1中文分词算法主要的问题
由于中文的结构特点,即汉字的词语与词语之间不存在明显的边界,所以相较其他西方国家的语言相比,中文分词的难度要高得多。在目前的研究中,中文分词主要遇到的问题有如下几个:“词”的清晰界定,分词歧异的消除,未登录词的识别以及分词和理解的先后问题。
2.1.1词语的界定
自动分词需要解决的一个基础问题是需要在计算的意义上界定出自然文本中词与词的边界问题。由于汉字是一个连续的序列,词语与词语之间不存在明显的分隔符,使得中文中词语的界定标准一直存在争议。在汉语词典中,可以找到一条相当抽象的关于“词”的定义:语言中有意义的能单说或用来造句的最小单位,但是这种定义是不可计算的。尽管《信息处理用现代汉语分词规范》已经提出了分词的单位以及系统分词规范,可是由于真实文本存在巨大的复杂性与多样性,导致理论和实践之间存在极大的差别,这个标准仍然没能够在词层面解决问题。在应用的角度上,不同的应用目的,对分词单元、词条颗粒度等有不一样的需求,甚至还有不一致的认识[2]。
2.1.2分词和理解的先后顺序
人类在阅读时,通常是理解在前分词在后,或者是分词和理解同时进行,有时甚至需要回顾上文的内容来考虑语句的正确切分方法,即在考虑词语的意思的基础上进行分词。而对于计算机来说,由于计算机理解文本的基础是识别出词语,以此来获得词语的信息最终来理解语句的意思,所以计算机无法像人类那样先理解后分词,大多数算法的处理策略都是分词在先理解在后。由于计算机只能在识别出词的基础上根据词语的表层意思进行分词,而未能考虑到整个句子的完整含义,所以任何分词系统都不具备百分之百的分词准确率。也有些研究者认为自然语言处理的基础是文本信息的理解,并在此基础上提出了类似于人类阅读习惯的先理解后分词的算法,但这类算法现在还存在各类不完备的地方,无法达到目前广泛采用的先理解后分词的分词算法的水平[2]。
2.1.3歧义处理
如果只根据分词字典对文本进行机械切分,那么在不同的切分方法下,可能存在多种不同的切分形式,这就是切分歧义。而在多种不同的切分结果中,选取一个最合理的正确结果,就是歧义字段的处理。
在自然语言处理中,歧义主要分为两类,一类是由于语言的二义性所引起的歧义,比如“美女记者潜伏朝鲜”,既可以切分为“美女/记者/潜伏/朝鲜”,也可以切分为“美/女记者/潜伏朝鲜”,这两种切分方法的结果在意思上都是正确的,在不包含上下文环境参照的情况下,即使是人工分词也很难确定究竟如何切分。
剩余内容已隐藏,请支付后下载全文,论文总字数:19485字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

