论文总字数:19565字
目 录
1引言 1
1.1研究背景 1
1.2研究意义 1
1.3国内外研究现状 2
2相关研究与技术 3
2.1网页信息获取技术 3
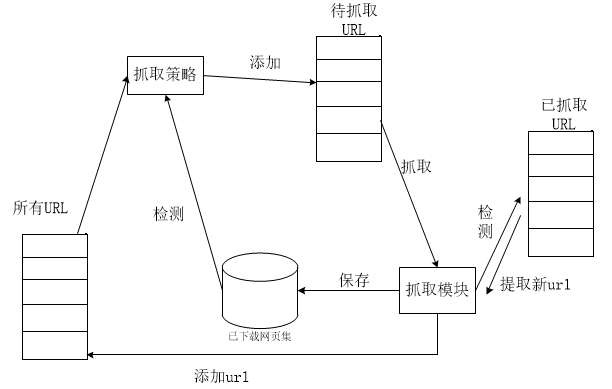
2.1.1网络爬虫 3
2.1.2网页结构与dom树 8
2.2数据挖掘简介 9
2.3Java与htmlparser 10
2.3.1Java简介 10
2.3.2Java EE平台 10
2.3.3htmlparser库 11
2.4 MyEclipse开发工具 12
3可行性分析 12
3.1技术可行性 12
3.2经济可行性 12
3.3操作可行性 13
4需求分析 13
4.1功能需求 13
4.2性能需求 13
5系统设计 13
5.1总体设计 13
5.1.1系统流程设计 13
5.1.2模块功能设计 15
5.1.3软件体系结构 16
5.1.4数据库设计 17
5.2详细设计 17
5.2.1网页抓取模块 17
5.2.2信息提取模块 20
5.2.3信息展示模块 21
5.2.4可视化爬虫界面 22
6系统测试 22
6.1系统环境 22
6.2测试结果 22
7.结论与不足 25
参考文献: 26
致谢 27
热点新闻跟踪与抓取系统设计
南天
,China
Abstract:With the rapid development of Internet, the network gradually become an indispensable part of private life and public activities. Rich source of news reports, diversified reporting ways, spread of channels, high-speed transmission speed and great news effect makes people pay more and more attention to the development and extension of the field of network news. Extracting and tracking the hot topic of news has become the key of news gathering. Because of a great amount of network information and its fast speed of updating, a new problem has been brought to extracting news in a timely and accurate manner.
This paper design a system on the basis of the research on web crawler and the web page content extraction technology .The system select a news website and automatically extract the content of hot news so that for public opinion analysis. The system first crawls web through the web crawler, then extracts page text content for analyzing, at last picks up the news and save them for tracking.
Key words:Topic News,Web Crawler,Content Extraction, Web Page Parsing
1引言
1.1研究背景
近年来,随着电脑落户千家万户,互联网随之快速发展,网络不仅成为个人工作生活必不可少的一部分,也带动了互联网行业的快速兴起。随着网络涉及各行各业,网络信息的数量也呈爆炸式地增长,其规模之庞大己经远远超乎人们想象,并且随着互联网的普及,网络信息积累的速度还在加快增长。由于计算机制造成本的减少,计算机销售价格下降,越来越多的人们购买计算机,个人计算机获得了普及,个人计算机使用方便,功能多样使得互联网成为人们生活的一部分,也成为了人们获取信息的重要方式之一。但是互联网提供的信息的量己经超出了人们可以接受的范围,相对于如何找到需要的信息,人们更倾向于能够快速准确地从网站提供的信息提取出关键内容,因此更需要研究人员研究出针对网络信息进行快速提取、分析并跟踪的方法。
针对大量信息的处理问题,研究人员提出了很多技术并迅速应用到信息搜索中 ,以搜索引擎为例,搜索引擎可以根据使用者提供的搜索关键字在已经处理好的数据中快速搜索到使用者需要的信息。人们利用搜索引擎定向地寻找自己所需要的信息。在搜索过程中也诞生了新的需求,人们希望能够在查找过程中能够获得与自己搜索的内容相关的一些信息,这些信息可能是某些技术,也可能是一些事件。人们对于相关热点信息的需要,衍生了网络中相应的服务和应用,例如网络订阅RSS服务,通过站点与站点之间共享信息来丰富网站信息,不同信息的来源可能相同,相同信息也可能有不同的来源。显然这种服务需要用户关注一些固定的信息发布者,再由发布者来发布最新信息,为此出现了新闻门户网站,提供了来自不同信息来源的新闻信息。有些用户长期固定搜索某类信息,因此为了避免用户重复输入搜索,需要一种智能化的自动检索系统,能分析出用户的关注点并自动向用户推荐相关热点新闻。但是在未给出关键词的前提下,能自动发现关键信息的技术有待深入研究。
针对互联网信息中的关键信息进行提取面临很多问题。首先,互联网信息相对于传统的数值类型数据,有不一样的存在形式,这使得其提取信息的方式与传统的方式存在一些区别。其存在形式主要是自然语言,而自然语言灵活多样,语素的含义在一定程度上需要结合上下文分析。其次,网络信息随时间变化而变化,这给关键信息的提取增加了难度。关键信息可能是一段时间人们关注的焦点,也能是突然爆发出来的大事件。最后,高效自动化信息处理必不可少。从目前技术应用中以人工分类的方式来刷选、挖掘社会热点的处理方法来看,效率十分低下。
1.2研究意义
近年来,网络媒体的逐渐兴起,使得网络逐渐成为人们获取信息的重要渠道 ,随之而来的是网络信息量的爆炸式增长。这种信息逐渐增多的趋势使人们更加关注热点新闻的获取,这就带来了新的需求,更多的研究人员开始关注网络热点新闻的提取与跟踪研究。其研究意义在于对于用户来说,挖掘新闻热点能减少自己的劳动量,可以毫不费力地获取到数量丰富且涵盖广泛的信息,也能针对某一特定的事件的整个发展过程进行跟踪关注,了解各方各面对该事件的理解和看法。网络新闻热点的提取不仅使人们更加关注这些热点,还能促进人们参与网络热门事件讨论的积极性;另一方面,对新闻网站建设者和网络监管部门而言,也有研究意义。他们通过热点挖掘的研究,可以有效地把握舆论风向,观察互联网用户行为习惯变化,从中分析出有益的规律。这样, 网站设计者就能根据用户的需求,进行更加准确的需求分析,设计出更符合用户想法的网站,使网站更具吸引力。网络监控者也能根据分析更好地对网络进行管理,减少了工作量。
1.3国内外研究现状
随着网络资源的逐渐丰富和网络与人们工作生活更加息息相关,网页数据提取技术也因此得到飞速发展。对于一些基础网页处理技术,研究人员进行了深入的研究,取得了一些成果,比如说文本处理和网页解析技术。这些基础性的技术支撑了热点新闻挖掘这项任务,这项任务需要对各种网页信息挖掘技术进行模块化的整合,每个模块形成自己的处理流程,每个步骤又需要何种网页信息挖掘技术,对于这些技术的优化与适应性调整等都是该项任务需要考虑到的问题。
目前在网页文本信息处理的基础领域中,我们所熟知的网页都是由包含各种HTML标签的HTML语言构成的 ,HTML文本提取要根据其规则来进行解析。因此HTML页面的解析是一个关键,一个好的解析技术将影响系统对网页的解析程度,并直接影响最后的结果。目前HTML网页的解析技术已经趋于成熟,开发者们开发出许多HTML解析包,而这些工具包是开源的。htmlparser是Java提供的一种用于网页解析的类库,html网页是由各种标签以及文本构成的, htmlparser工具包不仅能根据网页中的标签将网页构成dom树用于标签中文本的提取,还能根据标签名或者标签值查找到这些标签,利用htmlparser可以更加有效地进行网页文本的获取。
在研究网络爬虫和信息获取方面,国内学者进行了深入研究。刘林浩等人在热点新闻事件挖掘的研究中使用了基于SST(Site Style Tree)的正文提取算法,并对其中节点权重的衡量算法进行了优化。该算法通过网页各内容的重要程度计算出DOM树中个节点的权重,过滤网页中无意义的节点,最后得到正文提取的结构模板来对网页正文进行提取。而潘庆芝等人通过过滤网页中的无意义标签,再将过滤后的HTML标签解析成DOM树,最后根据标签提取网页文本信息。廖浩伟等人提出了一种基于网页结构聚类的Web信息提取方法,并实现了基于该方法的系统设计。系统能够将网页按照结构的相似性分类,设计相似结构提取的规则,依靠生成的规则准确提取结构相似网页的信息。
对于网络热点的跟踪与获取的研究,在国外也引起了极大重视。美国国防高级研究计划署(DARPA)早在1996年就根据自己的需求,提出了TDT(Topic Detection and Tracking)技术,希望能智能化地自动判断新闻数据流的主题。美国国家标准技术研究所(NIST)每年都要举办一场国际会议用来对话题检测与跟踪进行讨论,并对参加会议的机构所携带的系统进行评测。Uzun E等人开发了一个智能爬虫(icrawler),该爬虫能从网页中自动并有效地提取必要的区块,包括标题、摘要、主要文本等内容,能够自动确定爬虫爬行的深度,使用块更为快速地发现网页中的新超链接。
对于数量众多的新闻网页,如何对其进行分类从而获得包含同类热点新闻的网页是一个问题,对此国内外研究人员提出了不同的方法。刘林浩等人在对原始网页进行提取的基础上,通过对网页内容进行先分类再聚类的方法对网页文本内容进行信息处理,通过新闻的分类极大地方便了用户的新闻查找。在对新闻内容进行分类的前提下,通过聚类的方法将相同类别下的相同或者相似内容进行聚集,通过聚类展现了新闻的热度,对新闻的跟踪有极大的帮助,更加方便用户进行信息浏览,掌握新闻的热度。徐春光等人针对网络内容热点信息提取的关键问题展幵研究,以高校新闻为实验目标 ,将语义分析方法与改进K-means算法相结合,提出了基于语义分析与改进K-means算法的网络热点提取算法,并在此基础上实现了新闻热点分析平台。廖浩伟等人的想法与他们不同,他通过研究网页的结构并将网页通过DOM模型表示成树形结构,对网页结构的进行相似性分析,提出了一种改进的基于树路径匹配的网页结构相似度计算方法,并且将该算法与树编辑距离和树路径匹配算法进行比较,显示了两者的优劣性。
2相关研究与技术
剩余内容已隐藏,请支付后下载全文,论文总字数:19565字
相关图片展示:

该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

