论文总字数:15958字
目 录
1绪论 5
1.1 课题研究背景 5
1.2发展与现状 6
1.3研究主要内容 6
2相关技术介绍 7
2.1 Hadoop简介 7
2.2 MySQL数据库 8
2.3 Linux简介 9
2.5 Java 9
3系统分析 10
3.1系统需求分析 10
3.2技术可行性分析 10
3.3功能模块需求 11
3.4非功能性需求 13
4 系统设计 13
4.1总体设计 13
4.2 详细设计 14
4.2.1 登录 14
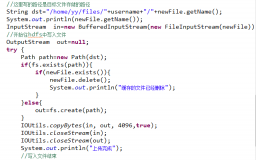
4.2.2上传文件 15
4.2.3查看所有文件 15
4.2.4 查看文件内容 16
4.2.5 删除指定文件 16
4.2.6下载文件 16
4.2.7 添加好友 16
4.2.8 分享文件 17
4.3 数据库设计 17
4.3.1 数据库的E-R图 17
4.3.2 数据库的表 18
4.4 Hadoop详细设计 19
5系统实现 20
5.1开发环境 20
5.2模块实现 21
5.3 系统演示实例 27
6 系统测试 29
6.1测试任务与目标 29
6.2测试方案与结果 29
7 结论 30
参考文献 31
致谢 31
基于hadoop的云盘系统的研究
杨洋
,China
Abstract: Cloud storage is a kind of new network storage technology, it can effectively use idle storage devices in the network, to provide a safe data storage, support big data fast reading and writing, improve the efficiency of cloud computing. To make a huge amount of data, data storage is a major problem, cloud storage is they tend to choose. This paper first introduces the background and status quo of cloud storage and Hadoop role in it. Have a general impression on the cloud and Hadoop technique. On the basis of the analysis of the cloud disk system architecture and implementation technologies. Finally in this paper, the cloud disk system implementation process and display the function of its
Key words:hadoop;hdfs;Cloud Storage System;
1.绪论
课题研究背景
现在的时代是个数据时代,随着Internet的发展,人们每天的生活已经离不开网络,而人们又随时随地会产生数据,因此数据的数量越来越庞大。很难估计全球以电子形式存储的数据量有多大,但从一些的网站的数据量就可想象。例如纽约证券交易所每天产生的数据量科大1TB,FaceBook存储着超过1PB的数据量。这些数据不仅需要存储,还需要分析,导致传统的数据处理方式越来越不适用,云计算也因此运用而生。
云存储是一门新的存储技术,现在在市场上非常热门,它是伴随着云计算孕育而生的。云计算首先是建立在集群之上,能够在网络上将庞大的需要计算处理的程序拆分成很多小程序,然后交给由很多服务器组成的系统处理。云存储的实质是将很多不同类型的存储设备通过软件或者其他系统功能,将其集合起来进行协同工作,形成一个能够实现数据存储和业务访问的系统
Hadoop使用Java语言开发,所以它有很强的通用性,同时Hadoop中的HDFS具有高容错性,从而它可以部署在连接的计算机上面,而且并不限制操作系统。Hadoop中HDFS的数据管理能力,MapReduce处理任务时的高效率,以及它的开源特性,使其在众多行业和科研领域中被广泛采用
发展与现状
伴随着着全球数据量的爆炸式的增长是数据存储方式的巨大变化。数据量的增大,数据的计算速度的要求,导致云环境下的大数据存储成为存储的的首选。目前主要的大数据平台以hadoop为主,主要是自建hadoop集群或者使用amazonElasticMapreduce服务。因为google的bigquery由于各种限制推广不理想,微软的Cosmos/Dryad/Scope也仅限于内部使用,不能成为大数据平台。
云计算已成为IT产业发展的战略重点,其实在很早之前有远见的公司已经开始了云计算方面的发展。从2014年开始,全球IT公司纷纷向云计算转型。2015年云计算市场出现了混合云状态,企业级云服务和个人云服务持续升温,智慧城市和工业等行业都成为云计算的重要市场,因而云计算已经在稳步发展。
近年来云计算的发展离不开Google,IBM,亚马逊等企业的贡献,他们都有着自己的比较成熟的云平台。Google的云计算平台,主要是由Mapreduce,Google File System和BigTable3部分组成。
亚马逊的“弹性计算云“,它将该云平台提供给用户,用户可以通过web访问,并可在虚拟机上运行任何软件,旨在将开发者的网络规模计算变得更容易。IBM的“蓝云”计算平台,这个平台的特点是用户可以在你上面建立自己的平台运行软件。雅虎的云平台,更多的给用户提供平台的支持。
当然中国的云计算开始也是很早,并且发展也是非常的迅速的。早在2007年,百度使用Hadoop做离线处理。同年淘宝和移动也都开始与计算的研究。而今天百度云计算平台,华为云计算平台,阿里云等云计算平台层出不穷。各种千万级的云计算项目也是层出不穷,例如2015的10个千万级云计算项目的落地。当然如今各种云存储服务,例如百度云,网易云等也是非常成熟。
研究主要内容
使用javaweb和hadoop技术实现在集群中对文件进行操作。
- 虚拟机的创建和Linux系统的安装。
- Hadoop集群搭建和环境变量的配置。
- 编写javaWeb代码实现对HDFS文件系统的操作。
2相关技术介绍
Hadoop简介
- Hadoop概述
Hadoop是一个分布式系统基础框架由Apache开发。它是一个开源的分布式计算平台,同时使用JAVA语言编写,同时它的通用性和容错性,使得可以部署在廉价的计算机上。
Hadoop主要由2部分组成:HDFS和MapReduce。HDFS提供海量数据存储,MapReduce提供计算。
Hadoop的架构
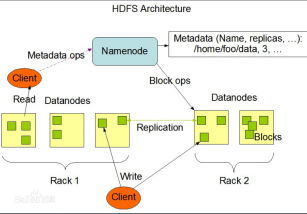
- Namenode:是HDFS的守护程序,记录文件是如何分割成数据块的以及这些数据块被存储到哪些节点上。对内存和I/O进行集中管理,它是个单点,若他崩溃则集群崩溃。
- SecondaryNameNode:监控HDFS状态的辅助后台程序,每个集群都会有一个。与NameNode进行通讯,定期保存HDFS元数据快照。若是NameNode故障,它可作为备用NameNode使用。
- DataNode:每台服务器运行一个,负责将HDFS数据块读取到本地文件系统。
- JobTracker:用户处理作业的后台程序,决定有哪些文件参与处理,然后切割task并分配节点。监控task,重启失败的task,每个集群只有唯一一个JobTracker,位于Master。
- TaskTracker:位于salve节点上,与DataNode结合,管理各自节点上的task,每个节点只有一个tasktracker,但一个tasktracker可以启动多个jvm并执行map或者reduce任务。与jobtracker交互。
HDFS概述
HDFS初期是Apache项目Nutch的基础结构,后来成为Hadoop的基础架构之一。HDFS是一个分布式文件系统。由于其高容错性特点,所以可以部署在廉价的机器上。它可以通过提供高吞吐率来访问应用程序的数据,适用于有着超大数据集的应用程序。
HDFS具有一下特点:
- 检测和快速恢复硬件故障。由于整个HDFS系统是由数百甚至更多的的存储服务器组成,其故障的发生率就意味着很高,因此HDFS要具有检测和快速恢复硬件故障的功能
- 流式的数据访问。在HDFS中数据的存储数据的方式是以文件,因此以流的形式读写。
- 简单一致性模型:HDFS对于文件要求一次写入,多次读取不支持并发读取。一个文件一旦经过存入后,就不可修改。所以就解决了数据一致性问题和高吞吐量的问题
- 通信协议。所有的通信协议都建立在TCP/IP协议上。客户端与NameN之间的协议是客户端协议,数据节点(DataNode)和名字节点(NameNode)之间则是护具节点协议(DataNode Protocal)。
HDFS集群是由一个NameNode和若干个DataNode组成。NameNode负责和客户端通信,并记录数据块的存放位置。HDFS的数据是以文件存储的形式,文件是被分成许多个数据块放在一组DataNode中。需要该文件时,可从NameNode中获取其位置,并从DataNode中读出。即客户端可以与NameNode进行交互从而达到对文件操作的目的。如下是HDFS的体系架构。
MySQL数据库
MySQL是典型的关系型数据库,十分适用用中小型项目中。相对与Oracle,DB2等关系型数据库,MYSQL功能并不那么强大,但他的优势使得它很受欢迎。
MySQL的优势:
- 速度:运行速度快
- 价格:MySQL对多数用户来说是免费的
- 容易使用:与其他大型数据库的设置和管理相比,其复杂度较低,易于学习。
- 可移植性:能够工作在众多不同的系统平台上,如:windows,Linx,unix等
- 丰富的接口:提供了用于C、C 、Eiffel、Java、Perl、PHP语言的API
- 支持查询语言:MySQL可以利用标准SQL语法和支持ODBC(开发式数据库连接)的应用程序。
- 安全性和连接性:十分灵活和安全的权限和密码系统,允许基于主机的验证。连接达到服务器时,所有的密码传输均采用加密形式。从而保证密码安全。并且由于MySQL是网络化的,因此可以在因特网上的热河地方访问提高数据共享的效率。
Linux简介
Linux是一个遵循POSIX(标准操作系统界面)标注的免费操作系统,具有BSD和SYSV的扩展特性(其表面和性能上tongue常见的UNIX非常相似,但核心代码都重新编写过)。
Linux是正真的多用户,多操作系统,它继承了UNIX的主要特征,具有强大的信息处理功能,特别是在Internet和Internet的应用中占有明显的优势。
剩余内容已隐藏,请支付后下载全文,论文总字数:15958字
相关图片展示:
该课题毕业论文、开题报告、外文翻译、程序设计、图纸设计等资料可联系客服协助查找;

